标签:div 含义 ati 基本 pre bsp 中文分词 重要性 计算
本文介绍一些常用的无监督关键词提取算法:TF-IDF,TextRank,主题模型算法
一、TF-IDF算法
即词频-逆文档频次算法,其基本思想是想要找到这样的词:它在一篇文档中出现的频次高(TF),即说明这篇文档很有可能围绕这个词进行说明;但是并不在多篇文档中出现(IDF),即说明这个词对文档的区分能力强。
tf(word)=(word在文档中出现的次数)/(该文档总词数),tf是就单篇文档来说的;
idf(i)=log(D/1+D(i)),idf是就多篇文档之间来说的,该式表达的含义是,D为总文档数,D(i)为出现词i的文档数量。
tf-idf值为上述相乘,在一篇文章中,计算每个词的tf-idf值,值最大的最适合作为这篇文章的关键词,关键词的数量通常不止一个,所以可以将tf-idf值由大到小排列,取前n个作为关键词。
整理完思路后,代码如下:
import jieba from jieba import analyse # 引入TF-IDF关键词抽取接口 filename = "C:/Users/Administrator/Desktop/stop_words/news/1.txt" # 基于TF-IDF算法进行关键词抽取 content = open(filename, encoding=‘utf-8‘).read() keywords = analyse.extract_tags(content,topK=10, withWeight=True, allowPOS=[]) # 第一个参数:待提取关键字文本 # 第二个参数:返回关键词的数量,重要性从高到低排序 # 第三个参数:是否同时返回每个关键词的权重 # 第四个参数:词性过滤,为空表示不过滤,若提供则仅返回符合词性要求的关键词 for keyword in keywords: print (keyword[0],keyword[1])
结果为: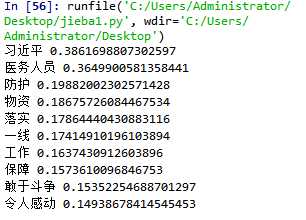
这里产生一个问题:我这里只有一篇文档,那么相当有1篇文档出现1次,那么如果我每次都是一篇一篇的文档进行关键词提取,岂不是相当于不考虑逆文档频率?因为每个文章的idf值是一样的?还是说,jieba有自己的语料库,idf值由它来确定?和我们输入多少篇文章无关?
标签:div 含义 ati 基本 pre bsp 中文分词 重要性 计算
原文地址:https://www.cnblogs.com/liuxiangyan/p/12458685.html