标签:目的 相对 来源 变更 log 动物 一致性 场景 中学
欢迎来到Tungsten Fabric用户案例系列文章,一起发现TF的更多应用场景。“揭秘LOL”系列的主人公是Tungsten Fabric用户Riot Games游戏公司,作为LOL《英雄联盟》的开发和运营商,Riot Games面临全球范围复杂部署的挑战,让我们一起揭秘LOL背后的“英雄们”,看他们是如何运行在线服务的吧。
作者:Doug Lardo和David Press(文章来源:Riot Games)译者:TF中文社区

在上一篇文章中,我们讨论了Riot针对全球应用程序部署的解决方案rCluster所涉及的网络的一些内容。具体来说,我们讨论了overlay网络的概念,OpenContrail(编者按:已更名为Tungsten Fabric,下文中出现OpenContrail之处,均以Tungsten Fabric代替)的实现,以及Tungsten Fabric解决方案如何与Docker配合使用。
本文将在此基础上深入探讨其他主题:基础架构即代码、负载均衡和故障转移测试。如果你对如何以及为什么建立这些工具、基础架构和流程感到好奇,那么本文正适合你。
通过Tungsten Fabric提供用于配置网络的API,我们现在有机会自动化应用程序的网络需求。在Riot,我们将持续交付作为发布应用程序的最佳实践。这意味着每一次提交给master的代码都是潜在可释放的。
为了达到这个状态,应用程序必须经过严格的测试自动化,并具有完全自动化的构建和部署流程。一旦出现问题,这些部署也应该是可重复且可逆的。这种方法的复杂性之一,是应用程序的功能性不仅在于其代码上,还在于环境方面,包括它所依赖的网络功能。
为了使构建和部署具有可重复性,应对应用程序及其环境的每个部分进行版本控制和审核,以便知道谁更改了内容。这意味着不仅要在源代码管理中拥有应用程序代码的每个版本,并且还描述了其环境并将其版本化。
为启用此工作流,我们构建了一个系统,以简单的JSON数据模型(我们称为网络蓝图)描述应用程序的网络功能。然后,我们创建了一个周期性工作,从源代码管理中提取这些蓝图文件,然后将其转换为Tungsten Fabric上的API调用以实施适当的策略。使用此数据模型,应用程序开发人员可以定义需求,例如一个应用程序与其它应用程序进行交谈的能力。开发人员不必担心IP寻址或通常只有网络工程师才能真正理解的任何细节。
应用程序开发人员拥有自己的网络蓝图。现在,更改它们就像给其蓝图文件发出pull请求,并使对方将其合并到master一样容易。通过启用这样的自主服务工作流,我们的网络更改不再受限于少数专业网络工程师。现在,唯一的瓶颈是工程师编辑JSON文件并单击“提交”的速度。
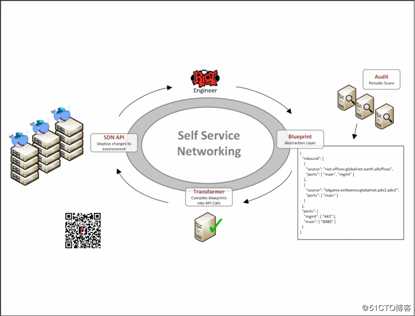
该系统使我们能够快速、轻松地打开必要的网络访问权限,这是安全策略的关键要素所在。在Riot,玩家的安全性至关重要,因此我们将安全性融入到了基础架构当中。我们安全策略的两个主要支柱是最低特权和纵深防御。
最低特权,意味着Riot网络上的任何参与者都只能访问完成其工作所需的最少资源集。参与者可能是人,也可能是后端服务。通过执行此原则,我们极大地限制了潜在***的影响范围。
深度防御,意味着我们在基础架构的多个位置执行安全策略。如果***者破坏或绕过我们的执行点之一,他们将始终碰到更多可抗衡的东西。例如,公共Web服务器被禁止从网络访问支付系统,并且该系统还维护自己的一组防御措施,比如第7层防火墙和***检测系统。
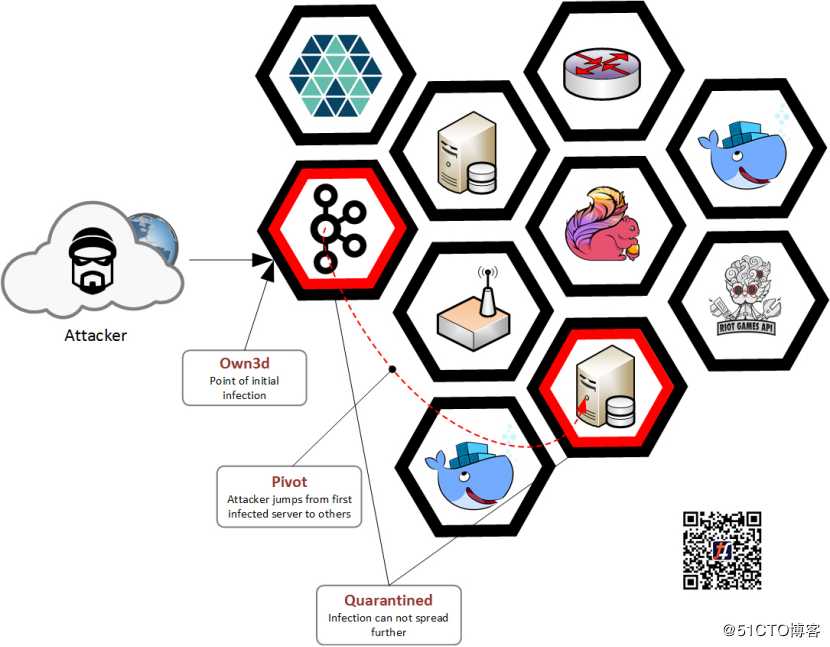
Tungsten Fabric通过其vRouter在每个主机上添加一个执行点来帮助我们。通过基础设施即代码JSON描述文件来使用其API ,我们始终可以为应用程序之间的通信提供最新的、版本化的,并且易于审核的网络策略。我们创建了可以扫描网络规则的工具,以发现违反政策和访问权限过大的情况。速度、最佳安全实践,以及审核能力的结合,构成了一个强大的安全系统,这并不会妨碍开发人员,相反,它使开发人员能够快速、轻松地做正确的事情。
为了满足应用程序不断增长的需求,我们将DNS、等价多路径(ECMP)和传统的基于TCP的负载均衡器(例如HAProxy或NGINX)相结合,以提供功能丰富且高度可用的负载均衡解决方案。
在Internet上,我们使用DNS将负载分散到多个全局IP地址上。玩家可以查找“riotplzmoarkatskins.riotgames.com”这样的记录(不是真实的,但也许应该是真实的),并且我们的服务器可以使用多个IP地址进行答复,这些IP地址将响应DNS查询。一半的玩家可能会收到一个列表,其中服务器A的位置位于顶部,而另一半玩家将看到服务器B的位置位于顶部。如果其中一台服务器关闭,客户端将自动尝试另一台服务器,因此没有人会看到服务的中断。
在网络内部,我们有许多服务器都配置为应答服务器A的IP地址。通过应答这个地址的能力,每个服务器都向网络发布通告,同时网络将每个服务器视为可能的目的地。收到新的玩家连接后,我们将在交换机中执行哈希计算,以确定性地计算出哪个服务器接收了流量。哈希基于数据包头中的IP地址和TCP端口值的组合。
如果其中一台服务器“休假”了,我们将尝试使用一种称为“一致性哈希”的技术,最大程度地减少影响,以确保只有使用故障服务器的玩家受到影响。大多数情况下,客户会通过自动重新启动新连接来无缝处理此问题,受影响的玩家甚至不会注意到。收到新的连接后,我们已经检测到并删除了发生故障的服务器,因此不会浪费时间尝试向其发送流量。
对于我们的大多数系统,我们会自动启动一个新实例,一旦它准备好接收流量,系统就会将其重新添加到循环中。我们认为它非常“漂亮”。负载均衡的最后一层,是通过传统的基于TCP或HTTP的负载均衡器(例如HAproxy或NGINX)执行的。
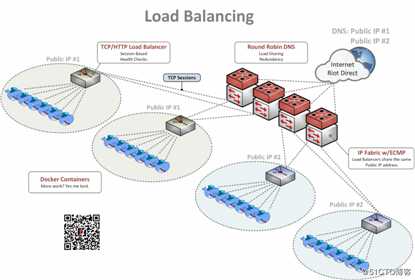
当请求来自ECMP层时,它们可能会遇到许多负载均衡的实例。这些负载均衡实例监视每个真实的Web服务器,并确保服务器运行状况良好,在适当的时间内做出响应,准备接收新的连接等。如果满足所有这些条件,则服务器会收到请求,并且答复将一直返回到玩家。
这一层通常是我们进行blue-green部署和智能运行状况检查的地方,例如“/index.html加载的响应代码为200吗?”
(编者按:Bule-green部署是一种负载均衡健康检查的部署方法,请见链接:https://blog.christianposta.com/deploy/blue-green-deployments-a-b-testing-and-canary-releases/)
此外,我们可以执行诸如“canary部署”,每10台服务器中的一台获得最新版本的网页,而其他9台服务器仍使用旧版本。我们会密切监视新版本,以确保不会出现任何问题,如果进展顺利,我们会将10台服务器中的两台移至新版本,依此类推。如果情况不佳,就回退到上一个已知的稳定版本,并找出解决问题的方法。我们随后将添加测试以更早地发现这些问题,以便不会两次犯相同的错误。这使我们能够不断改进服务,同时最大程度地降低生产风险。
通过所有层的协同工作(DNS、ECMP和传统的TCP或第7层负载均衡),我们为开发人员和玩家提供了功能丰富、性能稳定,且具有可扩展性的解决方案,使我们能够尽可能快地将服务器安装在机架中。
高可用系统最重要的部分之一,就是当发生故障时,该系统能够进行故障转移。当我们刚开始构建数据中心时,通过让工程师拉出一些电缆,并在这里和那里重新启动一些服务器,来模拟这些问题。但是,一旦数据中心启动并为玩家提供服务,这个过程将变得很困难,前后不一致,并且根本无法接受。这鼓励我们构建一些东西,然后再也不要碰它。我们绝对发现了重要问题,并避免了此过程的中断,但是还需要认真改进。
首先,我们在过渡环境中构建了按比例缩小版本的数据中心。它足够完整,可以准确无误。例如,在过渡环境中,我们有两个机架,每个机架有五台服务器。而生产系统在两个维度上都大得多,不过我们的问题可以通过更小、更便宜的设置来解决。
在这种过渡环境中,我们将测试所有更改,然后再将其交付生产。我们的自动化部署将在这里变更,对于每一个变更,我们都会对其执行快速的基本测试,以防止我们做完全愚蠢的事情。这消除了我们对于自动化系统变得有知觉,进行了上千次失控改变并最终融化了整个星球的一份担忧(编者按:本句的原文特别文艺——This removes the fear of our automated systems becoming sentient, making a thousand runaway changes, and eventually melting the whole planet,实际上就是想表达,我们不会过度的依赖自动化系统,因为担心自动化系统会放大细微的错误而将业务毁于一旦)。相对于生产环境,我们更喜欢在过渡环境中捕获这些类型的错误。
除了基本检查之外,我们还进行了更为复杂和破坏性的测试,这些测试破坏了重要组件并迫使系统在降级状态下运行。尽管四个子系统中只有三个子系统可以运行,但我们知道可以忍受这种损失,并且我们有时间在不影响玩家的情况下修复系统。
全套测试更加耗时,更具破坏性(我们宁愿中断系统并立即开始学习,而不是在生产中学习),并且比基本测试还要复杂,因此我们运行全套故障转移测试的频率并不高。
我们让每个链接都失效,重新启动内核,重新启动TOR交换机,禁用SDN控制器,以及我们能想到的其他任何方法。然后,我们测量系统进行故障转移所需的时间,并确保一切仍在平稳运行。
如果事情发生了变化,我们可以查看自上次运行代码以来对代码所做的更改,并在将更改交付生产之前,弄清楚我们可能已更改的内容。如果我们在生产中遇到无法预见的问题,而故障切换测试中没有发现该问题,我们会将该测试快速添加到套件中,以确保不再发生类似情况。我们的目标始终是尽早发现问题,越早发现问题,就可以越快地解决它。当我们以这种方式工作时,不仅可以快速前进,而且更加自信。
在上一篇文章中,介绍了数据中心网络的核心概念和实现,这次我们介绍了如何实现基础架构即代码,以及安全策略、负载均衡和故障转移测试。“变化是唯一不变的东西”,可能是将这些问题结合在一起的最好主题。基础设施是活着的、有呼吸的,并且在不断进化的“动物”。我们需要在它生长的时候提供资源,需要在它生病时做出反应,需要在全球范围内尽快完成所有工作。拥抱这一现实,意味着确保我们的工具、流程和范例能够对动态环境做出反应。所有这些使我们相信,现在是开发生产基础架构的绝佳时机。
和往常一样,非常欢迎与我们取得联系,说出你的问题和评论。
更多“揭秘LOL”系列文章
揭秘LOL背后的IT基础架构丨踏上部署多样性的征程
揭秘LOL背后的IT基础设施丨关键角色“调度”
揭秘LOL背后的IT基础架构丨SDN解锁新基础架构

关注微信:TF中文社区
标签:目的 相对 来源 变更 log 动物 一致性 场景 中学
原文地址:https://blog.51cto.com/14638699/2477252