标签:href 方法 加法 通过 width mic 梯度 均值 sum
GBDT (Gradient Boosting Decision Tree) 梯度提升迭代决策树。 GBDT通过多轮迭代,每轮迭代产生一个弱分类器,每个分类器在上一轮分类器的残差基础上进行训练。 弱分类器一般会选择为CART TREE(也就是分类回归树)。
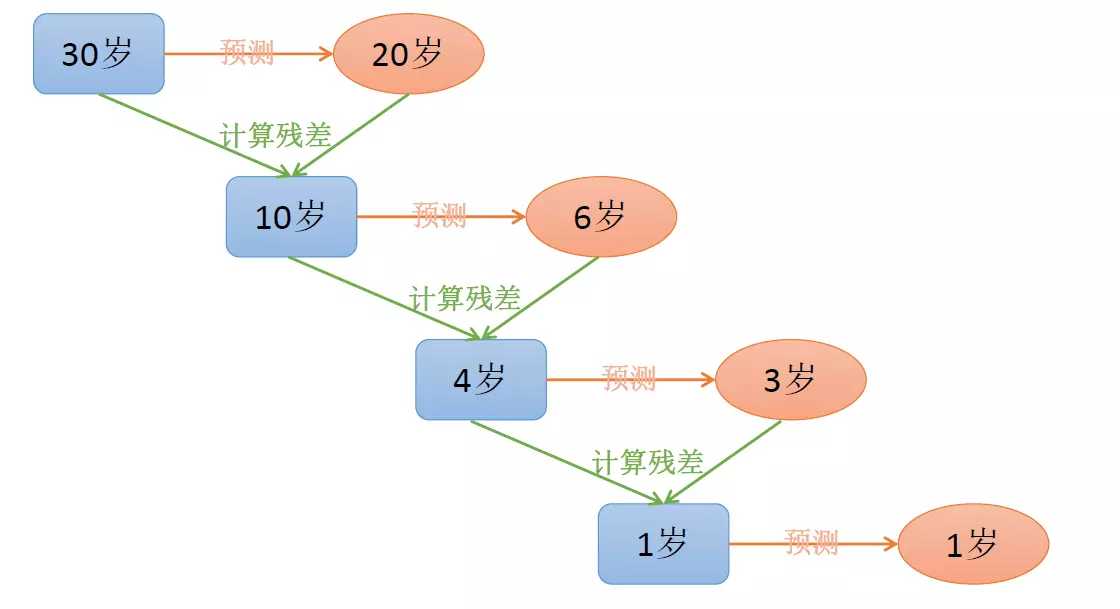
每一轮预测和实际值有残差,下一轮根据残差再进行预测,最后将所有预测相加,就是结果。
如下例子:给定目标值是30,而最终预测的值把各个预测的值相加,即20+6+3+1=30
最终的决策树加法模型:
$F(x)=∑_{m=1}^M T(x;\theta_m)$
其中,$T(x;\theta_m)$表示决策树;$\theta_m$为决策树的参数; M为树的个数或者也可以称为训练的次数。
下面我们具体来说CART TREE(是一种二叉树) 如何生成。CART TREE 生成的过程其实就是一个选择特征的过程。假设我们目前总共有 M 个特征。第一步我们需要从中选择出一个特征 j,做为二叉树的第一个节点。然后对特征 j 的值选择一个切分点 m. 一个 样本的特征j的值 如果小于m,则分为一类,如果大于m,则分为另外一类。如此便构建了CART 树的一个节点。其他节点的生成过程和这个是一样的。
现在的问题是在每轮迭代的时候,如何选择这个特征 j,以及如何选择特征 j 的切分点 m:
$f(x)=∑_{m=1}^M c_m I(x \in R_m)$
其中$I(x \in R_m)$表示x属于$R_m$区域,$\hat{c_m}$是一个区域的输出$y_i$平均值。详细下图

选择切分特征和切分点,其中$c_1$是$R_1$内的输出值,$c_1$应该是$\hat{c_1}$,因为此时$c_1$表示$R_1$内的最优值,其中$c_2$是$R_2$内的输出值。选用平方误差作为切分准则。


假设当前轮的输出是$y‘$,对应的标签是$y_i$,当选用均方误差作为损失函数时,
$L=\frac{1}{2}(y_i-y‘)^2$
此时的负梯度,因为导数的负方向可以减少损失
$-\frac{\partial L}{\partial y‘}=y_i-y‘$
那么下一轮迭代的$y_i=y_i-y‘$,所以下一轮拟合的就是上一轮对应的残差
和熵的意义一样,表示集合的不确定性,所以基尼系数越小,代表越确定。



假设$h_m(x)$ 就是学习到的决策树。
单样本$(x_i,y_i)$ ,其中$\hat{y_i}$ 表示决策树生成的标签,对应的损失函数可以表达为交叉熵:
假设第k步迭代之后当前学习器为$F(x)=\sum_{m=0}^M h_m(x)$ ,将$\hat y_i$ 的表达式带入之后, 可将损失函数写为:
可以求得损失函数相对于当前学习器的负梯度为:
可以看到,同回归问题很类似,下一棵决策树的训练样本为:{x_i,y_i-\hat y_i} ,其所需要拟合的残差为真实标签与预测概率之差。
假设共有K=3类。
我们在训练的时候,是针对样本 X 每个可能的类都训练一个分类回归树。举例说明,目前样本有三类,也就是 K = 3。样本 x 属于 第二类。那么针对该样本 x 的分类结果,其实我们可以用一个 三维向量 [0,1,0] 来表示。0表示样本不属于该类,1表示样本属于该类。由于样本已经属于第二类了,所以第二类对应的向量维度为1,其他位置为0。
针对样本有 三类的情况,我们实质上是在每轮的训练的时候是同时训练三颗树。
参考:
统计学习方法
https://www.cnblogs.com/bnuvincent/p/9693190.html
https://www.jianshu.com/p/405f233ed04b
https://zhuanlan.zhihu.com/p/46445201
标签:href 方法 加法 通过 width mic 梯度 均值 sum
原文地址:https://www.cnblogs.com/AntonioSu/p/12470366.html