标签:svm cap 生成 on() 关系 版本 edit 简化 分支
计算机程序利用经验E学习任务T,他的性能P会随着经验E不断增长。例如垃圾邮件过滤器,传统的编程技术只是针对指定的关键词(credit card,sale house)进行过滤。如果出现新的关键词保险,则需要更新标记。基于机器学习的垃圾邮件过滤器会自动检测保险关键词在用户手动标记为垃圾邮件中的反常频繁性,自动标记垃圾邮件。
Scikit-learn:对Python语言有所了解的科研人员可能都知道SciPy——一个开源的基于Python的科学计算工具包。基于SciPy,目前开发者们针对不同的应用领域已经发展出了为数众多的分支版本,它们被统一称为Scikits,即SciPy工具包的意思。而在这些分支版本中,最有名,也是专门面向机器学习的一个就是Scikit-learn。Scikit-learn项目最早由数据科学家David Cournapeau 在2007 年发起,需要NumPy和SciPy等其他包的支持,是Python语言中专门针对机器学习应用而发展起来的一款开源框架。
监督学习:知道结果的情况下进行学习,采用带标签的训练集(每个实例都有明确的标签标识是正确还是错误),例如垃圾邮件分类知道用于训练的邮件是正常邮件还是垃圾邮件。常的监督学习方法:K近邻算法, 线性回归, 逻辑回归,支持向量机(SVM),决策树和随机森林,神经网络。常见的两个实例:分类和预测目标值。
非监督学习:训练的数据没有标签,不知道是不是垃圾邮件。常用的实例就是聚类(博客访问人群分类),异常检测(信用卡异常),关联性检测(超市购买物品之间同时购买的放在一起),降维。
降维:简化数据,但是不能丢失大部分信息,做法之一就是合并若干相关特征。例如汽车的里程和车龄相关,降维就是将它们合并为一个特征值。
半监督学习:多数半监督学习算法是非监督和监督算法的结合,先用非监督方法进行训练,再用监督学习方法进行整个系统微调。
批量学习(离线学习):首先是进行训练,然后部署在生产环境且停止学 习,它只是使用已经学到的策略。
在线学习:是用数据实例持续地进行训练,可以一次一个或一次几个实例。响应快,实时性强。容易因为坏数据而性能下降,需要密集检测,检测到性能下降进行回滚。
学习速率:适应新数据的变化的速度。
基于实例学习:系统先用记忆学习案例,然后使用相似度测量推广到新的例子。例如采用单次数量相近作为一个判断相似性的标准。
基于模型学习:另一种从样本集进行归纳的方法是建立这些样本的模型,使得模型能够很好的进行预测。目标是找到最优的模型参数,使得代价函数的值最小。
(1)研究数据
(2)选择模型
(3)用训练数据进行训练(即,学习算法搜寻模型参数值,使代价函数最小)
(4)使用模型对新案例进行预测(这称作推断)。
幸福指数和收入GDP的关系
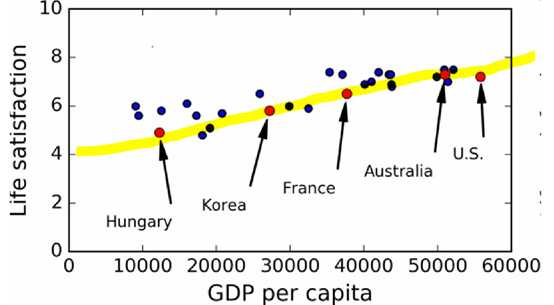
线性模型:分析可以发现趋势,采用一次函数life_satisfaction=a*gdp_per_capita+b作为线性模型。采用sklearn的线程模型 sklearn.linear_model.LinearRegression()。对数据进行分析拟合,得出分析模型,然后传入预测国家的gdp值得出这个国家幸福指数的预测值。
k近邻回归: sklearn.neighbors.KNeighborsRegressor(n_neighbors=3),取gdp值邻近的3个幸福指数,取平均值。
样本偏差:取样方法错误或者样本太小等,用于训练的数据不具备代表性,就会有样本噪声(即,会有一定概率包含没有代表性的数据)。
低质量数据:如果训练集中的错误、异常值和噪声(错误测量引入的)太多,系统检测出潜在规 律的难度就会变大,性能就会降低。花费时间对训练数据进行清理是十分重要的。大多数据科学家的一大部分时间是做清洗工作的。
特征工程:特征选择是在所有存在的特征中选取最有用的特征进行训练。 特征提取是组合存在的特征,生成一个更有用的特征(如前面看到的,可以使用降维算 法)。 收集新数据创建新特征。
(1)缺少数据,用于训练的样本数据不足、
(2)数据质量差(错误,异常值,噪声太多)
(3)数据不具有代表性(数据片面,在小范围)
(4)不相关特征,特征选择:在所有存在的特征中选取最有用的特征进行训练。 特征提取:组合存在的特征,生成一个更有用的特征(如前面看到的,可以使用降维算 法)。 收集新数据创建新特征。
过拟合:对数据进行高阶多项式拟合,虽然拟合误差越来越小,但是出现很大的波动曲线,使得偏离真实的数据范围。可以简化模型,减少模型参数,手机更多的训练数据,减少训练数据的噪声。
正则化:限定一个模型以让它更简单,降低过拟合的风险。
超参数(hyperparameter):正则化的度可以用一个超参数(hyperparameter)来控制,超参数越大,出现过拟合越小,但是拟合误差越大,调节超参数来测试拟合效果。超参数是算法的调节参数,模型参数是实例的建模参数。
欠拟合训练数据:模型过于简单,参数太少,无法有效的拟合数据。可以选择一个更强大的模型,用更好的滕州训练学习算法,减少对模型的限制。
将训练好的模型直接去应用,更好的方法是将你的数据分成两个集合:训练集和测试集。正如它们的名字,用训练集进行 训练,用测试集进行测试。对新样本的错误率称作推广错误(或样本外错误),通过模型对 测试集的评估,你可以预估这个错误。这个值可以告诉你,你的模型对新样本的性能。
训练集测试集验证集,用训练集进行训练,用测试集进行测试,你在测试集上多次测量了推广误差率,调整了模型和超参数,如果模型对新数据的性能不会高,可以在保留一个数据集验证集,可以在训练集和多个超参数训练多个模型,选择在验证集上有最佳性能的模型和超参数。
交叉验证:为了避免“浪费”过多训练数据在验证集上,训练集分成互补的子集,每个模型用不同的子集训练,再用剩下的子集验证。一旦确定模型类型和超参数,最终的模型使用这些超参数和全部的训练集进行训练,用测试集得到推广误差率。
自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取:
https://www.cnblogs.com/bclshuai/p/11380657.html
标签:svm cap 生成 on() 关系 版本 edit 简化 分支
原文地址:https://www.cnblogs.com/bclshuai/p/12470346.html