标签:import style out 时间 tps win 个数 获取 遍历
 登入今日热点网站,打开源代码可以得到标题标签为span,class=’t’。热度标签也为span,class=’e’,无需爬取排名数据只需要在之后遍历时使用i+1即可解决。
登入今日热点网站,打开源代码可以得到标题标签为span,class=’t’。热度标签也为span,class=’e’,无需爬取排名数据只需要在之后遍历时使用i+1即可解决。
首先将伪装爬虫,经过多次运行不伪装爬虫会报错无法运行,用find_all遍历标题和热点标签将他们添加入list列表中
用BeautifulSoup的HTML解析器
将list列表数据变为字符串否则报错,打开文件然后用追加文本形式将数据写入文件weibolist.txt中。
最后用主函数运行所有函数得出结果
import requests from bs4 import BeautifulSoup def get(url,list,num): #定义一个获取信息函数 headers = {‘user-agent‘:‘Mo+zilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11‘} #伪装爬虫 不然无法爬取网页信息 r = requests.get(url,timeout = 30,headers=headers) #发送请求 时间为30s soup = BeautifulSoup(r.text,"html.parser") list1 = soup.find_all(‘span‘,class_=‘t‘) #寻找标签为span的数据 list2 = soup.find_all(‘span‘,class_=‘e‘) print("{:^10}\t{:^30}\t{:^10}\t".format(‘排名‘,‘标题‘,‘热度‘)) for i in range(num): print("{:^10}\t{:^30}\t{:^10}\t".format(i+1,list1[i].string,list2[i].string)) #遍历前十个数据打印出来 list.append([i+1,list1[i].string,list2[i].string]) #将数据添加进列表中 def create_file(file_path,msg): #定义一个创建文件夹,将爬取的资源用txt格式打开 f=open(file_path,"a") f.write(str(msg)) #将列表数据变为字符串,直接用列表报错 f.close def main(): list = [] url = "https://tophub.today/" get(url,list,10) create_file("D:\python\weibolist.txt",list) main()
代码运行结果: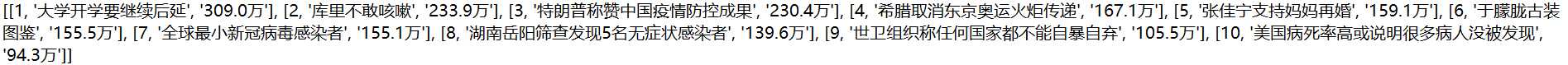
标签:import style out 时间 tps win 个数 获取 遍历
原文地址:https://www.cnblogs.com/ha15cier/p/12491784.html