sphinx的使用两种方式:
1、使用sphinx的API来操作sphinx,PHP中将API编译到PHP中作为扩展
2、使用mysql的sphinx的存储引擎
sphinx是英文的全文检索引擎,coreseek是支持中文词库的全文检索引擎,Lucene是用java实现的全文检索引擎。
使用sphinx搜索引擎对数据做索引,数据一次性加载进来后保存在内存中,用户在进行搜索的时候只需要在sphinx服务器上检索数据即可。整个流程是:Indexer程序到数据库里面提取数据,对数据进行分词,然后根据生成的分词生成单个或多个索引,并将它们传递给searchd程序,然后客户端可以通过API调用进行搜索。
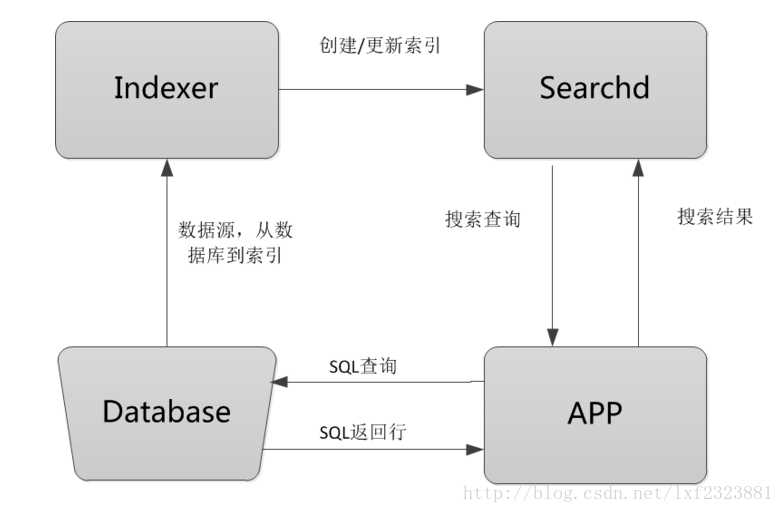
流程图解释:
Database:数据源,是sphinx做索引的数据来源。
Indexer:索引程序,从数据源中获取数据,并将数据生成全文索引。根据需求定期运行Indexer达到定时更新索引的需求。
## sphinx使用配置文件从数据库读出数据之后,就将数据传递给Indexer程序,然后Indexer会逐条读取记录,根据分词算法对每条记录建立索引,分词算法可以是一元分词或mmseg分词。
Searchd:Searchd直接与客户端程序进行对话,并使用Indexer程序构建好的索引来快速地处理搜索查询。
App客户端:接收来自用户输入的搜索字符串,发送查询给searchd程序并显示返回结果。
【安装过程】
|
1
2
3
4
5
6
7
8
9
10
11
|
# 到sphinx官网上下载源码文件:http://sphinxsearch.com/files/sphinx-2.2.10-release.tar.gz[root@localhost ~]# cd /usr/local/src[root@localhost ~]# tar -zxvf sphinx-2.2.10-release.tar.gz[root@localhost ~]# cd sphinx-2.2.10-release[root@localhost sphinx-2.2.10-release]# ./configure --prefix=/usr/local/sphinx --with-mysql[root@localhost sphinx-2.2.10-release]# make && make install# libsphinxclient安装(PHP模块需要)[root@localhost sphinx-2.2.10-release]# cd api/libsphinxclient[root@localhost libsphinxclient]# ./configure --prefix=/usr/local/sphinx[root@localhost libsphinxclient]# make && make install |
安装PHP的sphinx模块
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#下载sphinx扩展包:http://pecl.php.Net/package/sphinx[root@localhost src]# tar -zxvf sphinx-1.3.3.tgz[root@localhost src]# cd sphinx-1.3.3[root@localhost sphinx-1.3.3]# phpize[root@localhost sphinx-1.3.3]# ./configure --with-php-config=/usr/local/php/bin/php-config --with-sphinx=/usr/local/sphinx/[root@localhost sphinx-1.3.3]# make && make install# 安装成功:Installing shared extensions: /usr/local/php/lib/php/extensions/no-debug-non-zts-20131226/# 编辑php.ini[root@localhost sphinx-1.3.3]# vim /usr/local/php/etc/php.ini添加:extension=sphinx.so# 重启nginx服务器 |
|
1
2
3
4
|
[root@localhost ~]# vim /etc/ld.so.conf# 添加如下内容:/usr/local/mysql/lib[root@localhost ~]# ldconfig # 使命令生效 |
【Sphinx配置文件】
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
# sphinx可以定义多个索引与数据源,不同的索引与数据源可以应用到不同表或不同应用的全文检索。## 数据源 src1source src1{ ## 说明数据源类型,数据源类型可以是:mysql、mssql、odbc等等 type = mysql ## 下面是sql数据库特有的端口、用户名、密码数据库名等。 sql_host = localhost sql_user = root sql_pass = root sql_db = test sql_port = 3306 ## 执行sql前的操作,设置mysql检索编码 sql_query_pre = SET NAMES UTF8 ## 全文索引要显示的内容(尽可能不使用where、group by,将其的内容交给sphinx) ## select字段中必须包含一个唯一主键以及要全文检索的字段,where中要用到的字段也要select出来,sphinx使用此语句从数据库中拉取数据。 sql_query = SELECT id , name from tablename ## 以下是用来过滤或条件查询的属性 ## 当数据源过大时多次查询操作 sql_query_range = SELECT MIN( id ) , MAX( id ) FROM documents ## 获取最大和最小id,根据步长来获取数据 sql_range_step = 1000 ## 查询的步长 sql_ranged_throttle = 0 ## 设置分次查询的时间间隔,单位是毫秒 ## 以下都是不同属性的数据(属性字段),属性时存在索引中,它不进行全文索引,只可以用于过滤和排序 ## 在where、orderby、groupby中出现的字段要分别定义一个属性(以sql_attr_开头),定义不同类型的字段要用不同的属性名。 sql_attr_uint = cat_id ## 无符号整数类型 sql_attr_unit = member_id sql_attr_timestamp = add_time ## unix时间戳 ## 用于命令行界面调用测试 sql_query_info = select * from tablename where id=$id}## 索引index test1{ source = src1 ## 声明索引源 path = /usr/local/sphinx/var/data/test1 ## 索引文件存放路径及索引的文件名 ## mmseg分词 ## ##charset_dictpath = /usr/local/mmseg3/etc ## 指定分词读取词典文件的目录,目录下必须有uni.lib词典,当启用分词发时需要填 ## charset_type = zh_ch.utf-8 ## 设置数据编码 utf-8/gbk ## 一元分词 ## #charset_type = utf-8 ## 新的sphinx不支持charset_type设置 charset_table = ## 字符表和大小写转换规则 ngram_chars = ## 要进行一元字符切分模式认可的有效字符集 ngram_len = 1 ## 分词长度}## 索引器配置indexer{ mem_limit = 256 ## 内存限制}## sphinx服务进程searchd{ listen = 9312 ## 监听端口 listen = 9306:mysql41 log = /usr/local/sphinx/var/log/searchd.log ## 服务进程日志 query_log = /usr/local/sphinx/var/log/query.log ## 客户端查询日志 read_time = 5 ## 请求超时 max_children = 30 ## 同时可执行的最大searchd进程数 pid_file = /usr/local/sphinx/var/log/searchd.pid ## 进程id文件 max_matches = 1000 ## 查询结果的最大返回数 seamless_rotate = 1 ## 启动无缝轮转} |
【生成索引】
调用indexer程序生成全部索引:
|
1
|
[root@localhost ~]# /usr/local/sphinx/bin/indexer --config /usr/local/sphinx/etc/sphinx.conf --all |
指定某个数据源生成索引:
|
1
|
[root@localhost ~]# /usr/local/sphinx/bin/indexer --config /usr/local/sphinx/etc/sphinx.conf 索引名(配置文件中所定义的) |
如果此时searchd守护进程已经启动,需要加上--rotate参数:
|
1
|
[root@localhost ~]# /usr/local/sphinx/bin/indexer --config /usr/local/sphinx/etc/sphinx.conf --all --rotate |
【启动sphinx】
|
1
|
[root@localhost ~]# /usr/local/sphinx/bin/searchd --config /usr/local/sphinx/etc/sphinx.conf |
【使用sphinx】
1、new SphinxClient (); ## 创建sphinx的客户端接口对象
2、SetServer( host , port ); ## 设置连接sphinx主机与端口
3、SetMatchMode( mode ); ## 设置全文查询的匹配模式,mode为搜索模式
4、SetFilter( string $attribute , array $values [ , bool $exclude = false ] ) ## 增加整数型过滤器
string $attribute 属性名称
array $values 整数值数组
bool $exclude 匹配该过滤规则的文档是否会被排除在结果之外
5、SetSortMode( int mode [ , string $sortby ] ) ## 设置匹配排序模式
6、SetLimits( int $offset , int $limit ) ## 设置返回结果集偏移量和数目
7、Query( string $query [ , string $index=‘*‘ ] ) ## 执行搜索查询
string $query 查询的字符串
string $index 索引名称,可以是多个,用逗号分割或者为‘*‘表示全部索引
返回的数据结构:
| 键 |
值说明 |
| "matches" | 存储文档id以及其对应的另一个包含文档权重和属性值得hash表 |
| "total" | 此查询在服务器检索所得到的匹配文档总数(即服务器端结果集的大小,且与相关设置有关) |
| "total_found" | 索引中匹配文档的总数 |
| "words" | 将查询关键词(关键词经过大小写转换,取词干和其他处理)映射到一个包含关于关键字的统计数据。‘docs‘在多少文档中出现,‘hits‘一共出现了多少次。 |
| "error" | searchd报告的错误信息 |
| "warning" | searchd报告的警告信息 |
8、buildExcerpts( array $docs , string $index , string $words [ , array $opts ] ) ## 高亮关键字文本片段,可以用于实现摘要的功能
array $docs 文档内容字符串数组
string $index 检索名称
string $words 要高亮的关键词
array $opts 关联数组的附加突出选项
【sphinx增量索引更新】
索引建立构成:1、固定不变的主索引。2、增量索引重建。3、索引数据的合并。
在实际操作中,需要为增量索引的建立创建辅助表,这样才可以记住最后建立索引的记录id来做实际的增量部分的索引建立。
1)创建辅助表:CREATE TABLE `sph_counter` (`counter_id` int(11) NOT NULL COMMENT `标识不同的数据表`,`max_doc_id` int(11) NOT NULL COMMENT `每个索引表的最大ID,会实时更新`,PRIMARY KEY (`counter_id`)) ENGINE=MyISAM DEFAULT CHARSET=utf8
2)在主索引的数据源中,在sql_query的查询语句中,增加where条件语句(WHERE id<=( SELECT max_doc_id FROM sph_counter WHERE counter_id = 1 ))
3)在增量索引的数据源中,继承主索引数据源,在sql_query的查询语句中,增加where条件语句,获取主索引中没有的数据(WHERE id > ( SELECT max_doc_id FROM sph_counter WHERE counter_id = 1 ))
4)分别配置主索引和增量索引的index定义配置。
生成主索引,可添加crontab,定时重建主索引:
|
1
2
3
4
|
/usr/local/sphinx/bin/indexer --config /usr/local/sphinx/etc/sphinx.conf --rotate test1# 生成增量索引并且合并,可添加到crontab任务中每隔一段时间执行一次:/usr/local/sphinx/bin/indexer --config /usr/local/sphinx/etc/sphinx.conf --rotate delta/usr/local/sphinx/bin/indexer --config /usr/local/sphinx/etc/sphinx.conf --merge test1 delta --rotate |