标签:font 时间复杂度 使用命令 value 字符 idt 复杂 应用 键值对
一、简介
Redis的五大数据类型也称五大数据对象;前面介绍过6大数据结构,Redis并没有直接使用这些结构来实现键值对数据库,而是使用这些结构构建了一个对象系统redisObject;这个对象系统包含了五大数据对象,字符串对象(string)、列表对象(list)、哈希对象(hash)、集合(set)对象和有序集合对象(zset);而这五大对象的底层数据编码可以用命令OBJECT ENCODING来进行查看。
//redisObject
typedef struct redisObject { // 类型属性存储的是对象的类型,也就是我们说的 string、list、hash、set、zset中的一种,
//可以使用命令 TYPE key 来查看。 unsigned type:4; // 编码,记录了队形所使用的编码,即这个对象底层使用哪种数据结构实现。 unsigned encoding:4; // 指向底层实现数据结构的指针 void *ptr; // ... } robj;
redis是以键值对存储数据的,所以对象又分为键对象和值对象,即存储一个key-value键值对会创建两个对象,键对象和值对象。键对象总是一个字符串对象,而值对象可以是五大对象中的任意一种。
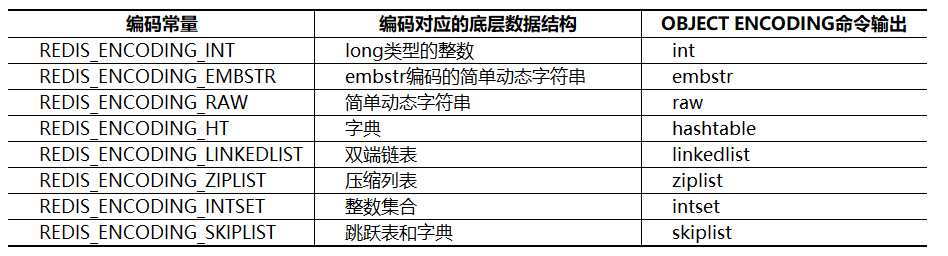
字符串对象底层数据结构实现为简单动态字符串(SDS)和直接存储,但其编码方式可以是int、raw或者embstr,区别在于内存结构的不同。
(1)int编码
字符串保存的是整数值,并且这个正式可以用long类型来表示,那么其就会直接保存在redisObject的ptr属性里,并将编码设置为int,如图:
(2)raw编码
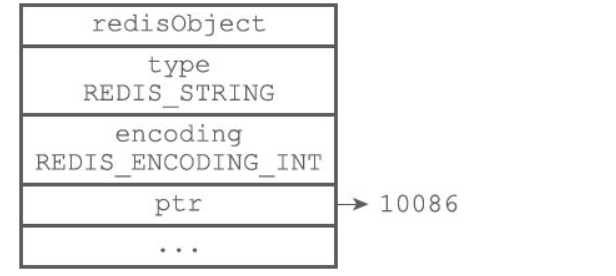
字符串保存的大于32字节的字符串值,则使用简单动态字符串(SDS)结构,并将编码设置为raw,此时内存结构与SDS结构一致,内存分配次数为两次,创建redisObject对象和sdshdr结构,如图:
(3)embstr编码
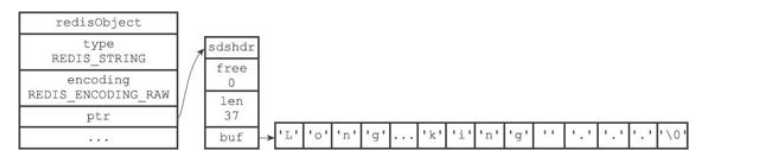
字符串保存的小于等于32字节的字符串值,使用的也是简单的动态字符串(SDS结构),但是内存结构做了优化,用于保存顿消的字符串;内存分配也只需要一次就可完成,分配一块连续的空间即可,如图:

字符串对象总结:
应用场景:
1.访问量统计:每次访问博客和文章使用 INCR 命令进行递增。
2.一般做一些复杂的技术功能的缓存。
列表对象的编码可以是ziplist和linkedlist之一。
(1) ziplist编码
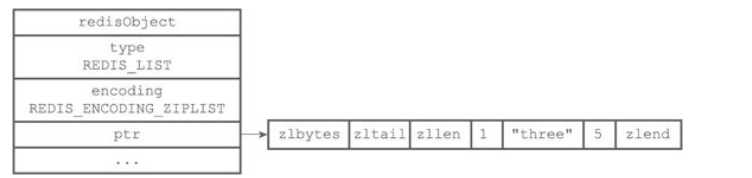
ziplist编码的列表对象底层实现是压缩列表,每个压缩列表节点保存了一个列表元素。
(2)linkedlist编码
linkedlist编码底层采用双端链表实现,每个双端链表节点都保存了一个字符串对象,在每个字符串对象内保存了一个列表元素。
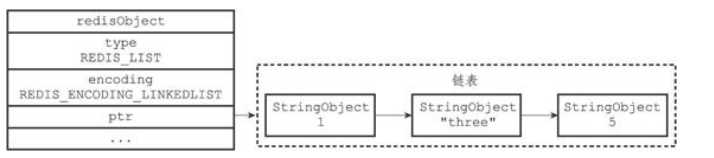
列表对象编码转换:
做简单的消息队列的功能;最新消息排行等功能(比如朋友圈的时间线)。
哈希对象的编码可以是ziplist和hashtable之一。
(1)ziplist编码
ziplist编码的哈希对象底层实现是压缩列表,在ziplist编码的哈希对象中,key-value键值对是以紧密相连的方式放入压缩链表的,先把key放入表尾,再放入value;键值对总是向表尾添加。
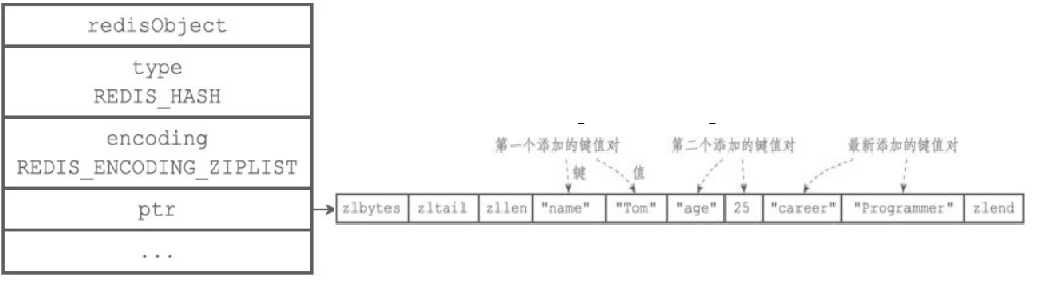
(2)hashtable编码
hashtable编码的哈希对象底层实现是字典,哈希对象中的每个key-value对都使用一个字典键值对来保存。
字典键值对即是,字典的键和值都是字符串对象,字典的键保存key-value的key,字典的值保存key-value的value。
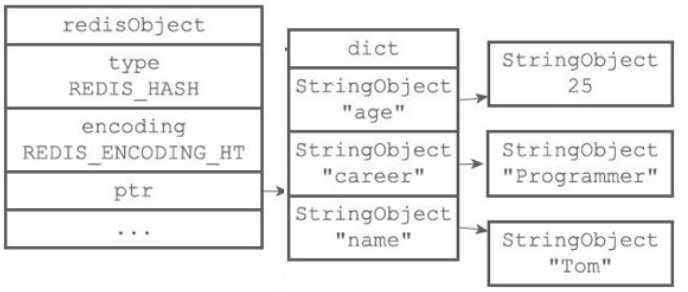
哈希对象编码转换:
存储、读取、修改对象属性,比如:用户(姓名、性别、爱好),文章(标题、发布时间、作者、内容)
集合对象的编码可以是intset和hashtable之一。
(1)intset编码
intset编码的集合对象底层实现是整数集合,所有元素都保存在整数集合中。
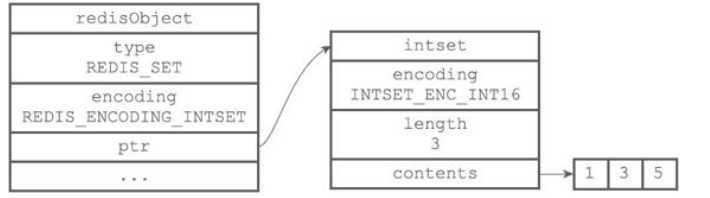
(2)hashtable编码
hashtable编码的集合对象底层实现是字典,字典的每个键都是一个字符串对象,保存一个集合元素,不同的是字典的值都是NULL;可以参考java中的hashset结构。
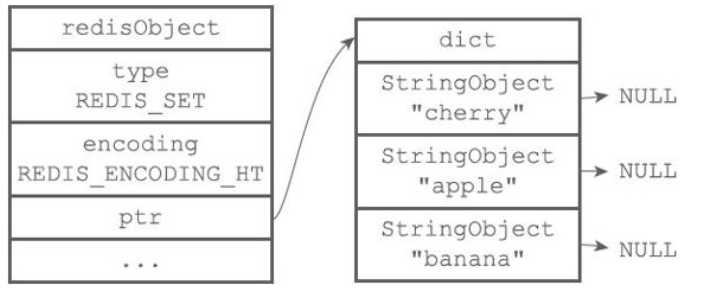
集合对象编码转换:
1、共同好友
2、利用唯一性,统计访问网站的所有独立ip
3、好友推荐时,根据tag求交集,大于某个阈值就可以推荐
有序集合的编码可以是ziplist和skiplist之一。
(1)ziplist编码
ziplist编码的有序集合对象底层实现是压缩列表,其结构与哈希对象类似,不同的是两个紧密相连的压缩列表节点,第一个保存元素的成员,第二个保存元素的分值,而且分值小的靠近表头,大的靠近表尾。
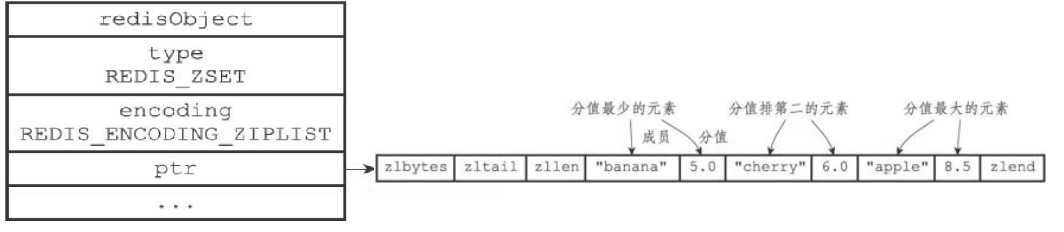
(2)skiplist编码
skiplist编码的有序集合对象底层实现是跳跃表和字典两种;
每个跳跃表节点都保存一个集合元素,并按分值从小到大排列;节点的object属性保存了元素的成员,score属性保存分值;
字典的每个键值对保存一个集合元素,字典的键保存元素的成员,字典的值保存分值。
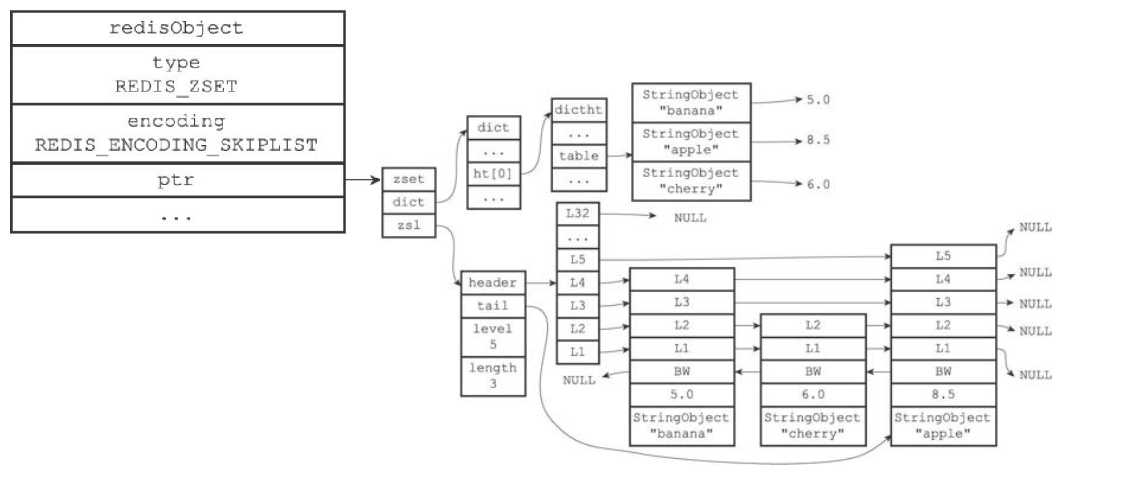
为何skiplist编码要同时使用跳跃表和字典实现?
有序集合编码转换:
排行榜,取TopN操作。带权重的消息队列。
在Redis的五大数据对象中,string对象是唯一个可以被其他四种数据对象作为内嵌对象的;
列表(list)、哈希(hash)、集合(set)、有序集合(zset)底层实现都用到了压缩列表结构,并且使用压缩列表结构的条件都是在元素个数比较少、字节长度较短的情况下;
四种数据对象使用压缩列表的优点:
(1)节约内存,减少内存开销,Redis是内存型数据库,所以一定情况下减少内存开销是非常有必要的。
(2)减少内存碎片,压缩列表的内存块是连续的,并分配内存的次数一次即可。
(3)压缩列表的新增、删除、查找操作的平均时间复杂度是O(N),在N再一定的范围内,这个时间几乎是可以忽略的,并且N的上限值是可以配置的。
(4)四种数据对象都有两种编码结构,灵活性增加。
标签:font 时间复杂度 使用命令 value 字符 idt 复杂 应用 键值对
原文地址:https://www.cnblogs.com/qmillet/p/12494469.html