标签:class 参数 asc 期望 range com symbol values for
最近给同学帮忙的时候需要按一个时间(日期)范围内的数据进行一些统计和处理,而且期望这个时间范围是一个可以修改的参数,这里顺便记录和分享一下。数据不方便放上来,这里就自己随便模拟一些数据出来。
主要使用要pandas和datetime这两个库。我们先生成模拟数据
import pandas as pd import datetime df = pd.DataFrame( { ‘Symbol‘:[‘A‘,‘A‘,‘A‘, ‘B‘, ‘B‘, ‘C‘, ‘C‘, ‘C‘] , ‘Msg‘:[‘AAA‘,‘AAA‘,‘AAC‘, ‘BBB‘, ‘BBC‘, ‘CCC‘, ‘CCC‘, ‘CCD‘] , ‘Date‘:[‘02/20/2015‘,‘01/15/2016‘,‘02/21/2015‘, ‘02/24/2015‘,‘03/01/2015‘, ‘02/22/2015‘,‘01/17/2015‘,‘03/21/2015‘] } )
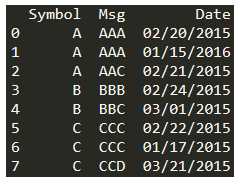
① 先将日期转变为pandas中的日期类型,排序方式为升序。为了后面能根据时间范围筛选数据,还需要将索引设置为日期。
df[‘Date‘] =pd.to_datetime(df.Date) df = df.sort_values(by=‘Date‘, ascending=True) df.index = df[‘Date‘]
② 利用 datetime.timedelta 自动计算。假设我们需要以7天为单位来处理数据,我们设置好起始时间,然后利用 datetime.timedelta 帮助我们计算终止时间(7天后的日期)。然后取出这范围内的数据即可。
start = datetime.datetime.strptime(str(df[‘Date‘][0]), ‘%Y-%m-%d %H:%M:%S‘) end = start + datetime.timedelta(days=7) df[start: end]
③ 基本的使用就是上面那个样子,现在我们写个函数来自动取出每个时间范围内的数据就可以了,我们还需要知道数据集的时间跨度,以设置循环次数。
import math delta = 7 # 处理的时间范围 day_num = (df[‘Date‘].max() - df[‘Date‘].min()).days # 数据集的时间跨度 loop_num = math.ceil(day_num / delta) # 计算循环次数 start = datetime.datetime.strptime(str(df[‘Date‘][0]), ‘%Y-%m-%d %H:%M:%S‘) end = start + datetime.timedelta(days=delta) for _ in range(loop_num): df_period = df[start: end] print(‘处理%s至%s‘ % (start, end)) start = end end += datetime.timedelta(days=delta)
timedelta 支持的时间单位如下图所示,可以根据实际情况和需要进行选择,更改单位时注意循环上限即可。
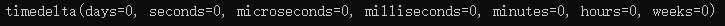
标签:class 参数 asc 期望 range com symbol values for
原文地址:https://www.cnblogs.com/dogecheng/p/12494424.html