标签:模型 节点 文件中 strong 架构 一起 war list vim
RabbitMQ集群架构模式那么对于Rabbitmq是单点应用来说,如果rabbitmq整个消息mq都会摊掉,所有在mq的消息高可用部分,就显得尤为重要了,那么在mq中提供了四种集群架构方案:
1、主备模式 (Warren)
2、镜像模式 (Mirror)
3、远程模式 (Shovel)
4、多活模式 (Federation)
在我们开发中最直接的模式就是主备模式:主要实现RabbitMQ的高可用集群,一般在并发和数据量不高的情况下,这种模型非常的好用且简单,主备模式也称为Warren模式
也就是一主一备,对于集群来说至少有两台服务器,那么这两台服务器一台在工作,一台在闲置,注意,这个的主备和我们之前的主从是不一样的,主从的话是一台作为主服务器,一台作为从服务器,虽然这两台是数据同步,主负责读写,而从只负责只读,而主备是一台工作一台闲着,如果一台服务器宕机了,那么备服务器切换过来,可能的话,这种对于负载均衡的话一台只忙着干活,一台只闲着,这种的生产中用的也很少,这种会造成我们资源的一个浪费。
镜像模式:集群模式非常经典的就是Mirror镜像模式,保证100%数据不丢失,在实际工作中也是用的最多的,而且实现集群也非常简单,一般互联网大厂都会构建这种镜像集群模式,原理主要是在主备的基础上进行了扩展,集群中所有的节点设备都是同步的,每一个队列,交换机里面的配置信息和我们的数据都是同步的,对于这些镜像在底层同时进行工作,前面的话采用一个负载均衡器,采用nginx或者haproxy也好,进行负载均衡。
远程模式:远程模式可以实现双活的一种模式,简称Shovel模式,所谓Shovel就是我们可以把消息进行不同数据中心的复制工作,我们可以跨地域的让两个MQ集群互联,比如说一个集群,我们都会放在一个机房里面,那么如果北京的机房出现了一些事故停电,或者自然灾害,那么这个集群都会宕机了,那么在我们对数据要求极高的大型应用我们需要设置多活或者双活的模式,也就是要搭建多个数据中心,或者多套集群,那么这些集群可以一个会放在上海,一个放在北京,还有应放在广州,三个集群数据都是同步的,中间有任何一个集群出现了问题,马上灵活的切换,那么这三个集群都是可以访问的话,我们可能会按照距离,或者访问速度来进行优先选择哪组集群,或者数据中心进行访问,所有多活模式,在银行开发的时候一般也叫做容灾的机制,至少构建两套集群放在不同的地域,一个有问题了,立马进行切换,不至于整个系统宕机,这就是多活模式,在多活模式中MQ也提供了相应的实现方式,早期使用的Shovel模式,这个模式是mq自带的一种模式,主要就是可以把消息在不同的数据中心进行负载分发,主要就是可以实现跨地域的让两个mq集群进行互联。
那么这个shovel模式需要统一的版本,网络达到一个什么样的水平,配置的话也是有些复杂,这种的话目前已经淘汰了,在真正的数据复制的情况下,会使用多活模式。
多活模式:这种模式也是实现异地数据复制的主流模式,这种模式是依赖rabbimq的fedrtation插件的模式
本身不是mq自带的东西,是在mq上进行了扩展,而这种扩展是实现的可靠的AMQP的数据通信,因此配置起来也比较容易,相当于配置简单化之后的shovel
配置
mq和erlang版本
RabbitMQ使用Erlang开发
Erlang([‘?:l??])是一种通用的面向并发的编程语言, Erlang是一个结构化,动态类型编程语言,内建并行计算支持。
使用Erlang来编写分布式应用要简单的多,Erlang运行时环境是一个虚拟机,有点像Java虚拟机,这样代码一经编译,同样可以随处运行。
下载地址:https://www.rabbitmq.com/download.html
直接下载最新的rabbitmq到本地
rabbitmq还需要依赖erlang的运行环境
https://www.erlang-solutions.com/resources/download.html
选择centos,找到22.2.5最新的版本下载到本地
[root@m2 mq-soft]# ls
esl-erlang_22.2.8-1~centos~7_amd64.rpm rabbitmq-server-3.8.3-1.el7.noarch.rpm关闭防火墙:
#systemctl stop firewalld
#systemctl disable firewalld关闭selinux:
#sed -i ‘s/enforcing/disabled/‘ /etc/selinux/config # 永久
#setenforce 0 # 临时2台安装好Rabbitmq的Centos环境,启动的时候使用后台启动
后台启动mq命令:rabbitmq-server -detached
这里我是提前部署好的MQ,如果想知道怎么部署MQ可以看上一篇文章
修改hostnamectl set-hostname m1/m2
加入主机列表 vim /etc/hosts
[root@localhost ~]# more /etc/hosts
192.168.30.27 m1
192.168.30.29 m2mq对主机名非常的敏感,即使使用hostnamectl set-hostname m1主机名之后不重启的话也是造成集群的不通信的问题
reboot重启
二、复制.erlang.cookie
.erlang.cookie是erlang分布式的token文件,集群内所有设备要
持有相同的.erlang.cookie文件才允许彼此通信。
也就是相当于你有学生证它也有学生证,你们就是学生,那么就可以一起上学,也就是一个token文件
找到这个.cookie结尾的文件,里面看到的是一个字符串,也就是两个主机需要持有相同的erlang的cookie文件才能进行彼此通信
[root@m1 ~]# find / -name *.cookie
/var/lib/rabbitmq/.erlang.cookie
[root@m1 ~]# more /var/lib/rabbitmq/.erlang.cookie
ZCSNJQYQPNPPLIYWOVBJ进行拷贝,将cookie文件拷贝过去
m1 # scp /var/lib/rabbitmq/.erlang.cookie root@192.168.30.24:/var/lib/rabbitmq/
root@192.168.30.24‘s password: 在两台电脑上执行chmod进行授权,400对拥有者才能读取
m1 chmod 400 /var/lib/rabbitmq/.erlang.cookie
m2 chmod 400 /var/lib/rabbitmq/.erlang.cookie 三、配置镜像集群
在m2服务器上执行下面的命令将与m1服务器进行复制
– rabbitmqctl stop_app 暂停服务
– rabbitmqctl join_cluster rabbit@m1 加入到m1的集群
– rabbitmqctl start_app 启动服务
– rabbitmqctl cluster_status 验证集群结果
终止与启动应用
rabbitmqctl start_app 启动应用
rabbitmqctl stop_app 终止应用
在mq2上操作
[root@m2 ~]# rabbitmqctl stop_app
Stopping rabbit application on node rabbit@m2 ...
[root@m2 ~]# rabbitmqctl join_cluster rabbit@m1
Clustering node rabbit@m2 with rabbit@m1
[root@m2 ~]# rabbitmqctl start_app
Starting node rabbit@m2 ...
[root@m2 ~]# rabbitmqctl cluster_status
Cluster status of node rabbit@m2 ...
Basics
Cluster name: rabbit@m1
Disk Nodes
rabbit@m1
rabbit@m2
Running Nodes
rabbit@m1
rabbit@m2
Versions
rabbit@m1: RabbitMQ 3.8.3 on Erlang 22.2.8
rabbit@m2: RabbitMQ 3.8.3 on Erlang 22.2.8查看已经注册进来,一般生产中的话,要不就是禁用这个guest用户,要不就是跟它修改一个比较复杂的密码

创建test查看m2也会同步进来
一般在程序中我们需要连接一个IP地址,那么这个地方就需要这么一个负载均衡去实现,这里我们使用HAproxy去实现
四、镜像模式遇到的问题
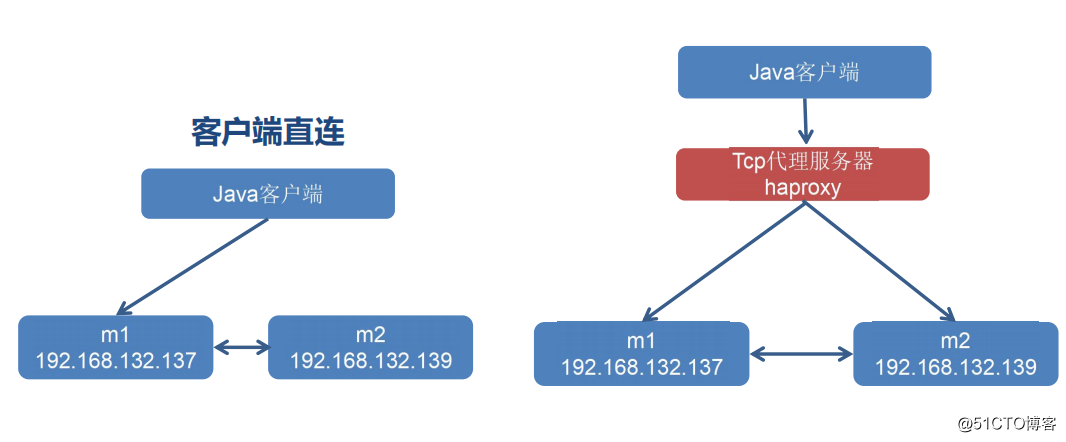
当配好两个mq的时候,对于客户端也就是java当我们去连接的时候就需要一个统一的入口来进行系统或者消息直接的调用,也就是需要连接哪台服务器进行数据的处理,如果是这种情况的话,当m1挂的话,我们就需要手动的去修改Java客户端的地址了,另外还有有一个问题就是m1猛干活,m2闲着没事做,而对我们的资源利用也是不合理的,那么负载均衡器就应运而生了。
而当有haproxy的时候它会将这个请求进行具体的转发到m1或者m2上进行分工,比如安装简单的算法轮询模式,将任务进行均摊,这样资源就会被合理的利用了,对于Java客户端直接可以配置proxy的地址了,而haproxy可以通过心跳的感知哪些服务器是可以发送消息的,比如遇到m2的机器宕机了,它就会自动的将我们的服务退出,来使用其他的节点也进行提供服务
HAProxy 代理服务器
HAProxy 是一款提供高可用性、负载均衡以及基于TCP(第四层)
和HTTP(第七层)应用的代理软件,支持虚拟主机,它是免费、
快速并且可靠的一种解决方案。
RabbitMQ集群镜像模式中,HAProxy用于做Tcp,提供节点负载
均衡(LB-LoadBalance)与故障发现。
安装haproxyyum -y install haproxy
配置文件的地址
[root@haproxy ~]# find / -name haproxy.cfg
/etc/haproxy/haproxy.cfg编译配置文件
#---------------------------------------------------------------------
#common defaults that all the ‘listen‘ and ‘backend‘ sections will
#use if not designated in their block
#---------------------------------------------------------------------
下面的不要了,然后配置以下内容
#对MQ集群进行监听对MQ的集群的监听HAproxy配置地址我放在了仓库中,有需要的需要将公钥发给我
git clone git@gitee.com:zhaocheng172/rabbitmq-haproxy.git生效配置文件[root@haproxy ~]# haproxy -f /etc/haproxy/haproxy.cfg
连接haproxy访问地址是上面设置的连接密码rabbitmq,这里在配置文件中去登录的密码,和url地址
登录进来可以看到我们的MQ进行监控到了,如果使用JAVA发送系统调用的消息之后那么就会进行消息的提供与消费。
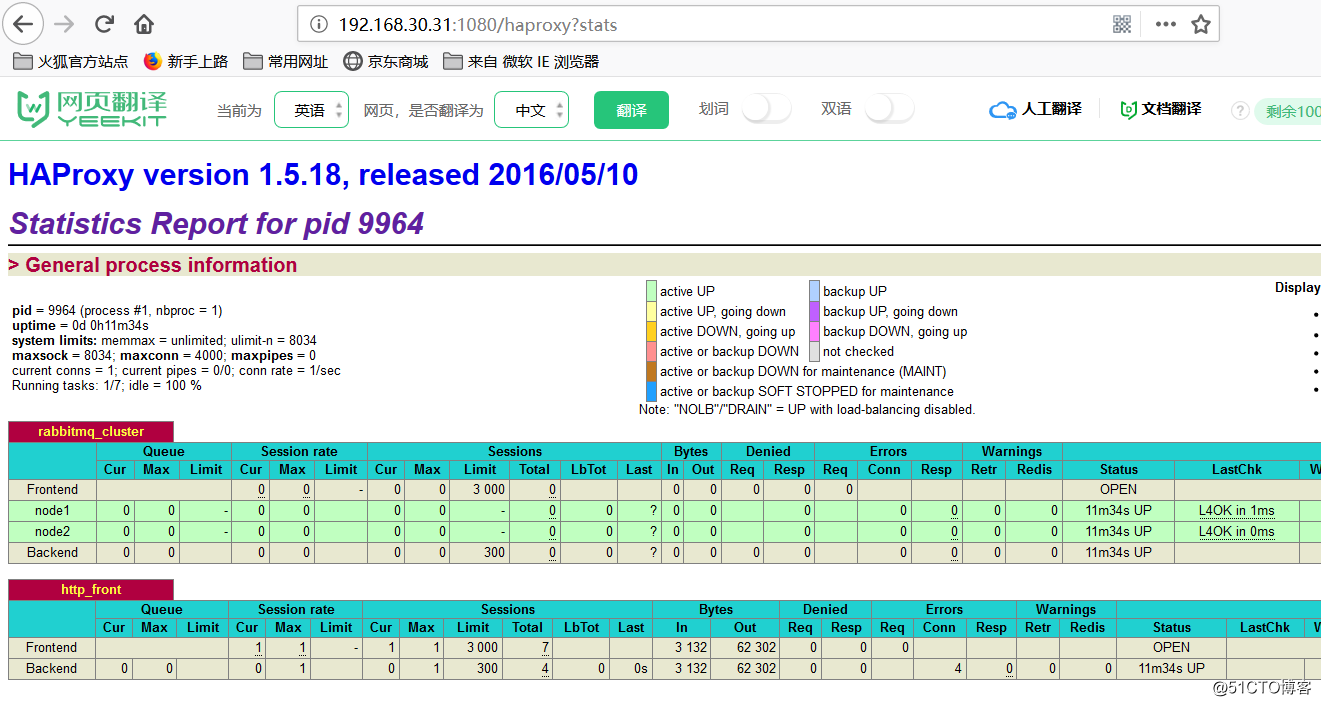
RabbitMQ集群架构之使用Haproxy实现高可用负载均衡
标签:模型 节点 文件中 strong 架构 一起 war list vim
原文地址:https://blog.51cto.com/14143894/2478187