标签:命令 创建ca 启用 blog sysconf sdn balancer touch probe

在开始部署 k8s 高可用集群时,请先参考k8s高可用环境部署系统准备
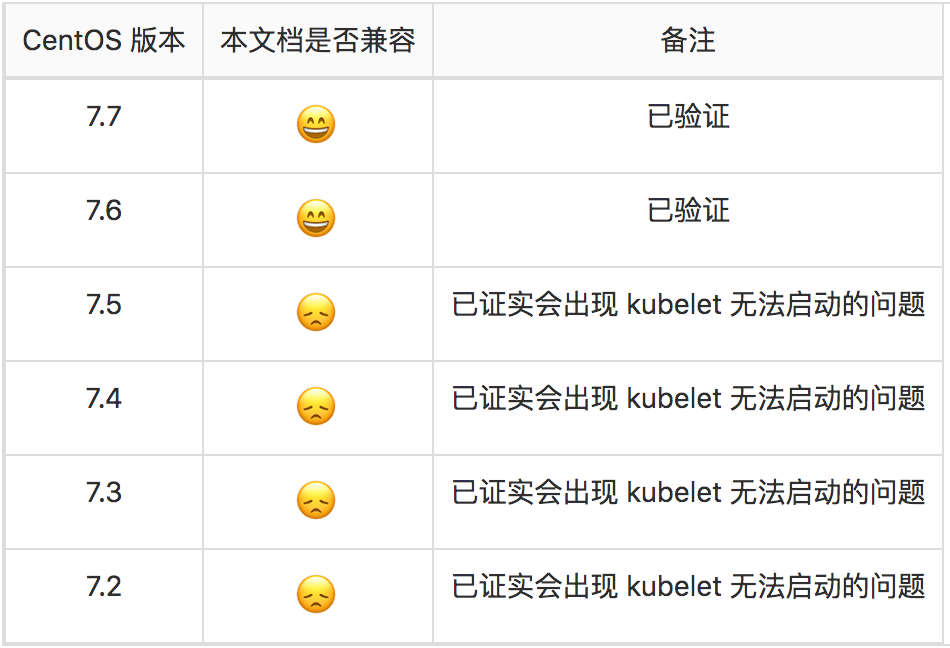
集群部署前系统环境装备,请参考k8s高可用环境部署系统准备.md
本次高可用集群基本参照官网步骤进行部署,官网给出了两种拓扑结构:堆叠control plane node和external etcd node,本文基于第一种拓扑结构进行部署,使用Keepalived + HAProxy搭建高可用Load balancer,完整的拓扑图如下:

单个mastre节点将部署keepalived、haproxy、etcd、apiserver、controller-manager、schedule六种服务,load balancer集群和etcd集群仅用来为kubernetes集群集群服务,不对外营业。如果必要,可以将load balancer或者etcd单独部署,为kubernetes集群提供服务的同时,也可以为其他有需要的系统提供服务,比如下面这样的拓扑结构:

说明??:这种拓扑结构也对应external etcd node~
本文仅部署master节点,使用kubeadm部署worker节点非常简单,不在赘述,环境清单:
服务器 主机IP 主机名字 功能
k8s-master01 192.168.246.193 master01 master+etcd+keepalived+HaProxy
k8s-master02 192.168.246.194 master02 master+etcd+keepalived+HaProxy
k8s-master03 192.168.246.195 master03 master+etcd+keepalived+HaProxy镜像清单:
docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy v1.17.3 ae853e93800d 4 weeks ago 116MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager v1.17.3 b0f1517c1f4b 4 weeks ago 161MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver v1.17.3 90d27391b780 4 weeks ago 171MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler v1.17.3 d109c0821a2b 4 weeks ago 94.4MB
registry.cn-hangzhou.aliyuncs.com/google_containers/coredns 1.6.5 70f311871ae1 4 months ago 41.6MB
calico/node v3.9.2 14a380c92c40 5 months ago 195MB
calico/cni v3.9.2 c0d73dd53e71 5 months ago 160MB
calico/kube-controllers v3.9.2 7f7ed50db9fb 5 months ago 56MB
calico/pod2daemon-flexvol v3.9.2 523f0356e07b 5 months ago 9.78MB
registry.cn-hangzhou.aliyuncs.com/google_containers/pause 3.1 da86e6ba6ca1 2 years ago 742kB主要软件清单:
我们在这里使用外部 etcd 节点,这里 etcd 所在的节点就是master01和master02。
新版的k8s,etcd节点已经可以完美和master节点共存于同一台服务器上;
etcd有3种方式安装(独立安装、docker方式、k8s内部集成);
(1)下载证书生成工具
#etcd三台机器安装创建证书所需软件
curl -o /usr/local/bin/cfssl https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
curl -o /usr/local/bin/cfssljson https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
curl -o /usr/local/bin/cfssl-certinfo https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
#cfssl授权
chmod +x /usr/local/bin/cfssl*(2)创建CA
#以下操作在 etcd1 机器执行
mkdir -p /etc/kubernetes/pki/etcd
cd /etc/kubernetes/pki/etcd
#创建 CA 配置文件(ca-config.json)
#我们可以创建一个初始的ca-config.json文件,如:cfssl print-defaults config > ca-config.json,然后对其进行修改。
cat >ca-config.json <<EOF
{
"signing": {
"default": {
"expiry": "876000h"
},
"profiles": {
"etcd": {
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
],
"expiry": "876000h"
}
}
}
}
EOF
#对上面的字段进行说明
"ca-config.json":可以定义多个 profiles,分别指定不同的过期时间、使用场景等参数;后续在签名证书时使用某个 profile;
"signing":表示该证书可用于签名其它证书;生成的 ca.pem 证书中 CA=TRUE;
"server auth":表示client可以用该 CA 对server提供的证书进行验证;
"client auth":表示server可以用该CA对client提供的证书进行验证;
#创建 CA 证书签名请求(ca-csr.json)
cat >ca-csr.json <<EOF
{
"CN": "etcd",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "shanghai",
"L": "shanghai",
"O": "etcd",
"OU": "System"
}
]
}
EOF
#对上面的字段进行说明
"CN":Common Name,etcd 从证书中提取该字段作为请求的用户名 (User Name);浏览器使用该字段验证网站是否合法;
"O":Organization,etcd 从证书中提取该字段作为请求用户所属的组 (Group);
这两个参数在后面的kubernetes启用RBAC模式中很重要,因为需要设置kubelet、admin等角色权限,那么在配置证书的时候就必须配置对了,具体后面在部署kubernetes的时候会进行讲解。
"在etcd这两个参数没太大的重要意义,跟着配置就好。"
#生成 CA 证书和私钥
cfssl gencert -initca ca-csr.json | cfssljson -bare ca
#证书文件说明
* 生成 "ca.csr ca-key.pem ca.pem" 三个文件
* ca.pem 根证书公钥文件
* ca-key.pem 根证书私钥文件
* ca.csr 证书签名请求,用于交叉签名或重新签名
* ca-config.json 使用cfssl工具生成其他类型证书需要引用的配置文件
* ca.pem用于签发后续其他的证书文件,因此ca.pem文件需要分发到集群中的每台服务器上去(3)创建etcd证书
#创建etcd的TLS认证证书
#创建 etcd证书签名请求(etcd-csr.json)
cd /etc/kubernetes/pki/etcd
cat > etcd-csr.json <<EOF
{
"CN": "etcd",
"hosts": [
"192.168.246.193",
"192.168.246.194",
"192.168.246.195",
"master01",
"master02",
"master03"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "shanghai",
"L": "shanghai",
"O": "etcd",
"OU": "System"
}
]
}
EOF
#生成 etcd证书和私钥
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=etcd etcd-csr.json | cfssljson -bare etcd(4)etcd免密认证和证书拷贝
#etcd三台机器执行
#三台机器免密认证
ssh-copy-id root@<etcd1-ip-address>
ssh-copy-id root@<etcd2-ip-address>
ssh-copy-id root@<etcd3-ip-address>
#etcd2&etcd3执行
mkdir -p /etc/kubernetes/pki/etcd
cd /etc/kubernetes/pki/etcd
scp root@192.168.246.193:/etc/kubernetes/pki/etcd/ca.pem .
scp root@192.168.246.193:/etc/kubernetes/pki/etcd/ca-key.pem .
scp root@192.168.246.193:/etc/kubernetes/pki/etcd/etcd.pem .
scp root@192.168.246.193:/etc/kubernetes/pki/etcd/etcd-key.pem .
scp root@192.168.246.193:/etc/kubernetes/pki/etcd/ca-config.json .(5)etcd集群部署
#etcd三台机器安装etcd可执行文件
mkdir -p /data/sys/var/etcd
chmod -R 777 /data/sys/var/etcd
ln -s /data/sys/var/etcd /var/lib/etcd
export ETCD_VERSION=v3.4.4
curl -sSL https://github.com/coreos/etcd/releases/download/${ETCD_VERSION}/etcd-${ETCD_VERSION}-linux-amd64.tar.gz | tar -xzv --strip-components=1 -C /usr/local/bin/
#配置etcd三台机器执行
#创建etcd环境配置文件
touch /etc/etcd.env
echo "PEER_NAME=master01" >> /etc/etcd.env #另外两台就是master02/03
echo "PRIVATE_IP=192.168.246.193" >> /etc/etcd.env #另外两台就是192.168.246.194/195
cat /etc/systemd/system/etcd.service
[Unit]
Description=etcd
Documentation=https://github.com/coreos/etcd
Conflicts=etcd.service
Conflicts=etcd2.service
[Service]
EnvironmentFile=/etc/etcd.env
Type=notify
Restart=always
RestartSec=5s
LimitNOFILE=40000
TimeoutStartSec=0
ExecStart=/usr/local/bin/etcd --name ${PEER_NAME} --data-dir /var/lib/etcd --listen-client-urls https://${PRIVATE_IP}:2379 --advertise-client-urls https://${PRIVATE_IP}:2379 --listen-peer-urls https://${PRIVATE_IP}:2380 --initial-advertise-peer-urls https://${PRIVATE_IP}:2380 --cert-file=/etc/kubernetes/pki/etcd/etcd.pem --key-file=/etc/kubernetes/pki/etcd/etcd-key.pem --client-cert-auth --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.pem --peer-cert-file=/etc/kubernetes/pki/etcd/etcd.pem --peer-key-file=/etc/kubernetes/pki/etcd/etcd-key.pem --peer-client-cert-auth --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.pem --initial-cluster <etcd1>=https://<etcd1-ip-address>:2380,<etcd2>=https://<etcd2-ip-address>:2380,<etcd3>=https://<etcd3-ip-address>:2380 --initial-cluster-token my-etcd-token --initial-cluster-state new
[Install]
WantedBy=multi-user.target
说明:
* 将<etcd1><etcd2><etcd3>改为对应节点的hostname
* 将<etcd1-ip-address><etcd2-ip-address><etcd3-ip-address>改为对应节点的通讯ip
#启动etcd集群
systemctl daemon-reload
systemctl start etcd
systemctl enable etcd
systemctl status etcd -l
#etcd集群服务的信息
mkdir /etc/kubernetes/scripts
cd /etc/kubernetes/scripts
cat etcd.sh
HOST_1=192.168.246.193
HOST_2=192.168.246.194
HOST_3=192.168.246.195
ENDPOINTS=$HOST_1:2379,$HOST_2:2379,$HOST_3:2379
#etcd集群健康信息
etcdctl --endpoints=$ENDPOINTS --cacert=/etc/kubernetes/pki/etcd/ca.pem --cert=/etc/kubernetes/pki/etcd/etcd.pem --key=/etc/kubernetes/pki/etcd/etcd-key.pem endpoint health
#etcd集群状态信息
etcdctl --endpoints=$ENDPOINTS --cacert=/etc/kubernetes/pki/etcd/ca.pem --cert=/etc/kubernetes/pki/etcd/etcd.pem --key=/etc/kubernetes/pki/etcd/etcd-key.pem --write-out=table endpoint status
#etcd集群成员信息
etcdctl --endpoints=$ENDPOINTS --cacert=/etc/kubernetes/pki/etcd/ca.pem --cert=/etc/kubernetes/pki/etcd/etcd.pem --key=/etc/kubernetes/pki/etcd/etcd-key.pem member list -w table
#执行上面脚本打印如下sh etcd.sh
192.168.246.193:2379 is healthy: successfully committed proposal: took = 18.14859ms
192.168.246.194:2379 is healthy: successfully committed proposal: took = 23.323287ms
192.168.246.195:2379 is healthy: successfully committed proposal: took = 26.20336ms
+----------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| 192.168.246.193:2379 | eff04b7e9f6dffe1 | 3.4.4 | 29 kB | false | false | 15 | 15 | 15 | |
| 192.168.246.194:2379 | 5f2f927b4eb48281 | 3.4.4 | 25 kB | true | false | 15 | 15 | 15 | |
| 192.168.246.195:2379 | 93be7c874982c2c6 | 3.4.4 | 25 kB | false | false | 15 | 15 | 15 | |
+----------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
+------------------+---------+----------+------------------------------+------------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+----------+------------------------------+------------------------------+------------+
| 5f2f927b4eb48281 | started | master02 | https://192.168.246.194:2380 | https://192.168.246.194:2379 | false |
| 93be7c874982c2c6 | started | master03 | https://192.168.246.195:2380 | https://192.168.246.195:2379 | false |
| eff04b7e9f6dffe1 | started | master01 | https://192.168.246.193:2380 | https://192.168.246.193:2379 | false |
+------------------+---------+----------+------------------------------+------------------------------+------------+此处的keeplived的主要作用是为haproxy提供vip(192.168.246.200),在三个haproxy实例之间提供主备,降低当其中一个haproxy失效的时对服务的影响。主要步骤如下:
三台master机器均是如下操作!
(1)安装keepalived
yum install -y keepalived
(2)配置keepalived
cd /etc/keepalived
mv keepalived.conf keepalived.conf_bak
cat > /etc/keepalived/keepalived.conf << EOF
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
}
vrrp_script check_haproxy {
script "killall -0 haproxy"
interval 3
weight -2
fall 10
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51
priority 250 #优先级保持唯一,这里master01为250,master02为200,master03为150
advert_int 1
authentication {
auth_type PASS
auth_pass 35f18af7190d51c9f7f78f37300a0cbd
}
virtual_ipaddress {
192.168.246.200
}
track_script {
check_haproxy
}
}
EOF
#上面配置文件说明
*记得修改上面配置文件priority
* killall -0 根据进程名称检测进程是否存活
* master01节点为***MASTER***,其余节点为***BACKUP***
* priority各个几点到优先级相差50,范围:0~250(非强制要求),数值越大优先级越高~
(3)启动并检测服务
systemctl enable keepalived.service
systemctl start keepalived.service
systemctl status keepalived.service
#我们在master01主节点上,看下ip信息
ip address show ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:66:1a:10 brd ff:ff:ff:ff:ff:ff
inet 192.168.246.193/24 brd 192.168.246.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.246.200/32 scope global ens33
valid_lft forever preferred_lft forever此处的haproxy为apiserver提供反向代理,haproxy将所有请求轮询转发到每个master节点上。相对于仅仅使用keepalived主备模式仅单个master节点承载流量,这种方式更加合理、健壮。
三台机器均是如下步骤:
(1)安装HaProxy
yum install -y haproxy
(2)配置haproxy
cd /etc/haproxy
mv haproxy.cfg haproxy.cfg_bak
cat > /etc/haproxy/haproxy.cfg << EOF
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
# to have these messages end up in /var/log/haproxy.log you will
# need to:
#
# 1) configure syslog to accept network log events. This is done
# by adding the ‘-r‘ option to the SYSLOGD_OPTIONS in
# /etc/sysconfig/syslog
#
# 2) configure local2 events to go to the /var/log/haproxy.log
# file. A line like the following can be added to
# /etc/sysconfig/syslog
#
# local2.* /var/log/haproxy.log
#
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the ‘listen‘ and ‘backend‘ sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
#---------------------------------------------------------------------
# kubernetes apiserver frontend which proxys to the backends
#---------------------------------------------------------------------
frontend kubernetes-apiserver
mode tcp
bind *:16443
option tcplog
default_backend kubernetes-apiserver
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend kubernetes-apiserver
mode tcp
balance roundrobin
server master01 192.168.246.193:6443 check #更改对应的主机名和IP
server master02 192.168.246.194:6443 check #更改对应的主机名和IP
server master03 192.168.246.195:6443 check #更改对应的主机名和IP
#---------------------------------------------------------------------
# collection haproxy statistics message
#---------------------------------------------------------------------
listen stats
bind *:1080
stats auth admin:awesomePassword
stats refresh 5s
stats realm HAProxy\ Statistics
stats uri /admin?stats
EOF
#说明:
* 所有master节点上的配置完全相同
* haproxy日志配置方法和细节可参考[HaProxy安装和常用命令](https://blog.51cto.com/wutengfei/2467351)
(3)启动并检测服务
systemctl enable haproxy.service
systemctl start haproxy.service
systemctl status haproxy.service
ss -lnt | grep -E "16443|1080"
LISTEN 0 128 *:1080 *:*
LISTEN 0 128 *:16443 *:*三台机器均是如下操作:
(1)设置kubernetes的yum源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
yum clean all
yum makecache fast
(2)安装kubelet kubeadm kubectl
yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
(3)启动kubelet.service并设置开机启动
systemctl enable kubelet.service
systemctl start kubelet.service
systemctl status kubelet.service
说明:这时如果状态是“loaded”,暂时可以不用管~当然我们也可以排查下为什么kubelet是loaded状态:
执行 journalctl -xefu kubelet 发现“error failed to read kubelet config file "/var/lib/kubelet/config.yaml", error: open /var/lib/kubelet/config.yaml: no such file or directory”。kubeadm init 初始化信息后,我们看一下初始化过程发现自动创建了 "/var/lib/kubelet/config.yaml" 这个文件。
(4)编辑hosts文件,添加如下内容
cat /etc/hosts
192.168.246.200 cluster.kube.com
192.168.246.193 master01
192.168.246.194 master02
192.168.246.195 master03以下操作在master01节点进行:
(1)编辑kubeadm配置文件
mkdir -p /etc/kubernetes/my-conf
cd /etc/kubernetes/my-conf
cat >config.yaml <<EOF
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
kubernetesVersion: 1.17.3
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers
etcd:
external:
endpoints:
- https://192.168.246.193:2379
- https://192.168.246.194:2379
- https://192.168.246.195:2379
caFile: /etc/kubernetes/pki/etcd/ca.pem
certFile: /etc/kubernetes/pki/etcd/etcd.pem
keyFile: /etc/kubernetes/pki/etcd/etcd-key.pem
networking:
podSubnet: 10.244.0.0/16
apiServer:
certSANs:
- "cluster.kube.com"
controlPlaneEndpoint: "cluster.kube.com:16443"
EOF
(2)启动集群,获得返回命令用来加入集群
kubeadm init --config=config.yaml
注意下面初始化成功之后的信息,如下:
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join cluster.kube.com:16443 --token 6uxfh3.urwz7noyhnvee4iz --discovery-token-ca-cert-hash sha256:6a06960763e5b2a7689b1f936a438e4fb369c0eab1d1f49964a166ec02966c57 --control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join cluster.kube.com:16443 --token 6uxfh3.urwz7noyhnvee4iz --discovery-token-ca-cert-hash sha256:6a06960763e5b2a7689b1f936a438e4fb369c0eab1d1f49964a166ec02966c57
(3)认证linux用户操作权限
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
(4)查看节点
kubectl get node
NAME STATUS ROLES AGE VERSION
master01 NotReady master 9m51s v1.17.3
(5)查看集群状态
kubectl get cs
NAME STATUS MESSAGE ERROR
etcd-2 Healthy {"health":"true"}
etcd-1 Healthy {"health":"true"}
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}
(6)动态查看 kube-system 命名空间下的pod
kubectl get pod -n kube-system -o wide -w 或 watch kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-7f9c544f75-wsjxq 0/1 Pending 0 11m <none> <none> <none> <none>
coredns-7f9c544f75-xvhjc 0/1 Pending 0 11m <none> <none> <none> <none>
kube-apiserver-master01 1/1 Running 0 11m 192.168.246.193 master01 <none> <none>
kube-controller-manager-master01 1/1 Running 0 11m 192.168.246.193 master01 <none> <none>
kube-proxy-fr84w 1/1 Running 0 11m 192.168.246.193 master01 <none> <none>
kube-scheduler-master01 1/1 Running 0 11m 192.168.246.193 master01 <none> <none>
(7)执行命令查看kubeadmin的配置
kubeadm config view 结果如下:
apiServer:
certSANs:
- cluster.kube.com
extraArgs:
authorization-mode: Node,RBAC
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: cluster.kube.com:16443
controllerManager: {}
dns:
type: CoreDNS
etcd:
external:
caFile: /etc/kubernetes/pki/etcd/ca.pem
certFile: /etc/kubernetes/pki/etcd/etcd.pem
endpoints:
- https://192.168.246.193:2379
- https://192.168.246.194:2379
- https://192.168.246.195:2379
keyFile: /etc/kubernetes/pki/etcd/etcd-key.pem
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.17.3
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16
serviceSubnet: 10.96.0.0/12
scheduler: {}scp root@192.168.246.193:/etc/kubernetes/pki/ca.crt /etc/kubernetes/pki/
scp root@192.168.246.193:/etc/kubernetes/pki/ca.key /etc/kubernetes/pki/
scp root@192.168.246.193:/etc/kubernetes/pki/sa.key /etc/kubernetes/pki/
scp root@192.168.246.193:/etc/kubernetes/pki/sa.pub /etc/kubernetes/pki/
kubeadm join cluster.kube.com:16443 --token 6uxfh3.urwz7noyhnvee4iz --discovery-token-ca-cert-hash sha256:6a06960763e5b2a7689b1f936a438e4fb369c0eab1d1f49964a166ec02966c57 --control-plane在 master01 节点部署插件,网络插件有两种,选择其一即可。calico和flannel,本次使用的calico网络插件:
(1)使用calico网络插件
mkdir -p /etc/kubernetes/manifests/my.conf/network-utils
curl -o /etc/kubernetes/manifests/my.conf/network-utils https://docs.projectcalico.org/v3.3/getting-started/kubernetes/installation/hosted/rbac-kdd.yaml
curl -o /etc/kubernetes/manifests/my.conf/network-utils https://kuboard.cn/install-script/calico/calico-3.9.2.yaml
kubectl apply -f /etc/kubernetes/manifests/my.conf/network-utils/rbac-kdd.yaml
kubeadm config view #获取podSubnet
export POD_SUBNET=10.244.0.0/16
sed -i "s#192\.168\.0\.0/16#${POD_SUBNET}#" calico-3.9.2.yaml
kubectl apply -f /etc/kubernetes/manifests/my.conf/network-utils/calico-3.9.2.yaml
(2)使用flannel网络插件
curl -o /etc/kubernetes/manifests/my.conf/network-utils https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f /etc/kubernetes/manifests/my.conf/network-utils/kube-flannel.yml
#查看集群节点状态
kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
master01 Ready master 16h v1.17.3 192.168.246.193 <none> CentOS Linux 7 (Core) 3.10.0-1062.el7.x86_64 docker://19.3.8
master02 Ready master 16h v1.17.3 192.168.246.194 <none> CentOS Linux 7 (Core) 3.10.0-1062.el7.x86_64 docker://19.3.8
master03 Ready master 16h v1.17.3 192.168.246.195 <none> CentOS Linux 7 (Core) 3.10.0-1062.el7.x86_64 docker://19.3.8
#查看状态
kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
calico-kube-controllers-dc6cb64cb-492mv 1/1 Running 2 166m 10.244.241.70 master01 <none> <none>
calico-node-74zf2 1/1 Running 2 166m 192.168.246.193 master01 <none> <none>
calico-node-krmmj 1/1 Running 3 166m 192.168.246.195 master03 <none> <none>
calico-node-l5k2p 1/1 Running 2 166m 192.168.246.194 master02 <none> <none>
coredns-7f9c544f75-9h92k 1/1 Running 2 16h 10.244.241.71 master01 <none> <none>
coredns-7f9c544f75-rn4fj 1/1 Running 2 16h 10.244.241.72 master01 <none> <none>
kube-apiserver-master01 1/1 Running 34 16h 192.168.246.193 master01 <none> <none>
kube-apiserver-master02 1/1 Running 14 15h 192.168.246.194 master02 <none> <none>
kube-apiserver-master03 1/1 Running 15 15h 192.168.246.195 master03 <none> <none>
kube-controller-manager-master01 1/1 Running 36 16h 192.168.246.193 master01 <none> <none>
kube-controller-manager-master02 1/1 Running 22 15h 192.168.246.194 master02 <none> <none>
kube-controller-manager-master03 1/1 Running 16 15h 192.168.246.195 master03 <none> <none>
kube-proxy-5xmv8 1/1 Running 7 15h 192.168.246.195 master03 <none> <none>
kube-proxy-pfslb 1/1 Running 5 16h 192.168.246.194 master02 <none> <none>
kube-proxy-pxdsn 1/1 Running 4 16h 192.168.246.193 master01 <none> <none>
kube-scheduler-master01 1/1 Running 41 16h 192.168.246.193 master01 <none> <none>
kube-scheduler-master02 1/1 Running 17 15h 192.168.246.194 master02 <none> <none>
kube-scheduler-master03 1/1 Running 15 15h 192.168.246.195 master03 <none> <none>到这里 k8s 高可用master部分就已经部署好了~
如果遇到上面报错,这里提供一个处理方法:
#下载和安装calicoctl工具,注意calico版本
cd /usr/local/bin
curl -O -L https://github.com/projectcalico/calicoctl/releases/download/v3.9.2/calicoctl
chmod +x calicoctl
#编辑配置文件/etc/calico/calicoctl.cfg
mkdir /etc/calico
因为我们使用的是内部etcd集群,所以需要对calicoctl进行配置,使其能读取calico配置信息。
cat > /etc/calico/calicoctl.cfg << EOF
apiVersion: projectcalico.org/v3
kind: CalicoAPIConfig
metadata:
spec:
datastoreType: "kubernetes"
kubeconfig: "/root/.kube/config"
EOF
如果你使用的是外部etcd集群,这里提供个模版可参考:
apiVersion: projectcalico.org/v3
kind: CalicoAPIConfig
metadata:
spec:
datastoreType: "etcd"
etcdEndpoints: "https://192.168.246.193:2379,https://192.168.246.194:2379,https://192.168.246.195:2379"
etcdKeyFile: "/etc/kubernetes/pki/etcd/etcd-key.pem"
etcdCertFile: "/etc/kubernetes/pki/etcd/etcd.pem"
etcdCACertFile: "/etc/kubernetes/pki/etcd/ca.pem"
#calicoctl常用命令
(1)calicoctl get node #查看网络节点
NAME
master01
master02
master03
(2)calicoctl node status #节点网络状态
Calico process is running.
IPv4 BGP status
+-----------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+-----------------+-------------------+-------+----------+-------------+
| 192.168.246.193 | node-to-node mesh | up | 05:08:38 | Established |
| 192.168.246.194 | node-to-node mesh | up | 05:08:38 | Established |
+-----------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
#使用calicoctl工具查看有问题的节点
calicoctl node status #有问题的节点状态
Calico process is running.
IPv4 BGP status
+-----------------+-------------------+-------+----------+---------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+-----------------+-------------------+-------+----------+---------+
| 192.168.246.194 | node-to-node mesh | start | 03:29:06 | Passive |
+-----------------+-------------------+-------+----------+---------+
IPv6 BGP status
No IPv6 peers found.
#使用calicoctl工具来对calico进行更改
(1)查看问题节点的yaml文件
calicoctl get node master03 -o yaml
(2)calicoctl get node master03 -o yaml > calicomaster03.yaml
vim calicomaster03.yaml
将ip更改正确
calicoctl apply -f calicomaster03.yaml
kubectl get po -n kube-system
可以看到calico-node的节点都正常启动master01创建集群时的返回命令贴入从机命令行执行,如果忘记可从master01重新获取
获取方法:在master01上执行
kubeadm token create --print-join-command
说明:默认情况下,通过kubeadm create token创建的 token ,过期时间是24小时。可以运行 kubeadm token create --ttl 0生成一个永不过期的 token,参考文档kubeadm token。
(3)使用Kubeadm + HAProxy + Keepalived部署高可用Kubernetes集群
(4)Keepalived+Haproxy实现高可用负载综合实验、
(6)k8s教程
标签:命令 创建ca 启用 blog sysconf sdn balancer touch probe
原文地址:https://blog.51cto.com/wutengfei/2478495