标签:返回值 安全 override int 适用于 二叉树 string hash lse
1.1 hashMap
1.2 hashTable
1.3 LinkedHashMap
1.4 TreeMap
1.5 ConcurrentHashMap
2.1 HashMap:底层基于数组+链表(红黑树),非线程安全,允许有空的键和值;
2.2 HashTable:底层基于哈希表实现的,线程安全,不允许有空的键和值;
2.3 HashMap继承自AbstractMap类,,而HashTable是继承自Dictionary类;
2.4 HashTable的初始容量为11,之后每次扩容,容量就变成了原来的2n+1;
2.5 HashMap的初始容量为16,之后每次扩容,容量就变成了原来的2倍;
hashCode():顶级父类object当中的方法,返回值类型为int类型的值,根据一定的规则生成一个数组,数组保存的就是hash值;
equals():顶级父类object当中的方法,根据一定的比较规则,判断对象是否一致;
底层一般逻辑:
1.判断两个对象的内存地址是否一样;
2.非空判断和class类型判断;
3.强转;
4.对象中的字段一一匹配;
package com.wn.Test02;
import java.util.Objects;
public class Title {
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public boolean equals(Object o) {
//判断两个对象的内存地址是否一样
if (this == o) return true;
//非空判断和class类型判断
if (o == null || getClass() != o.getClass()) return false;
//强转
Title title = (Title) o;
//对象中的字段一一匹配
return id == title.id &&
Objects.equals(name, title.name);
}
@Override
public int hashCode() {
return Objects.hash(id, name);
}
}
HashMap:底层采用数组+链表结构,可以实现快速的存储和检索,但是数据时无序的,适用于在map当中插入删除或者获取元素;
TreeMap:存储结构是一个平衡二叉树,具体实现方式为红黑树,默认采用自然排序,可以自定义排序规则,但是需要实现Comparator,能够便捷的实现内部元素的各种排序,但是性能比HashMa差,适用于按照具体自然排序和自定义排序规则;
Map是一组键值对的结构,具有极快的查找速度;
Set核心就是保存不重复的元素,存储一组唯一的对象;
Set当中每一种实现都对应Map;
HashSet对应的底层就是new HashMap,TreeSet对应的底层就是new TreeMap;
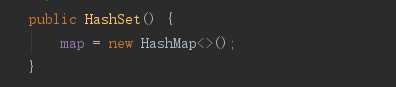
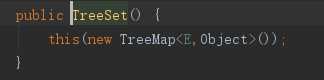
6.1 TreeMap排序
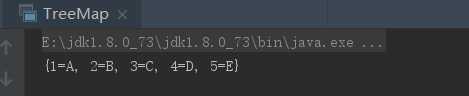
TreeMap只能根据key进行排序,TreeMap本身是个二叉树,元素的顺序是由key的值决定的;
按照自然排序可以采用TreeMap;
package com.wn.Test02;
import java.util.Map;
public class TreeMap {
public static void main( String[] args ){
java.util.TreeMap<String, String> map = new java.util.TreeMap<String,String>();
map.put("1","A");
map.put("2","B");
map.put("3","C");
map.put("4","D");
map.put("5","E");
System.out.println(map);
}
}
6.2 HashMap排序
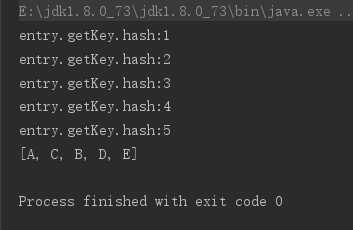
HashMap本身是没有顺序的,不能直接对其进行排序;
要排序,只能先转成list;
package com.wn.Test02;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
public class HashMapTest {
public static void main( String[] args ){
HashMap<Integer,String> map = new HashMap<Integer,String>();
map.put(1,"A");
map.put(3,"B");
map.put(2,"C");
map.put(4,"D");
map.put(5,"E");
ArrayList<Object> list = new ArrayList<>();
for (Map.Entry<Integer,String> entry:map.entrySet()){
System.out.println("entry.getKey.hash:"+entry.getKey().hashCode());
list.add(entry.getValue());
}
System.out.println(list);
}
}
6.3 LinkedHashMap排序
插入顺序,遍历LinkedHashMap时,先得到的记录肯定是先插入的;
package com.wn.Test02;
import java.util.*;
public class LinkedListTest {
public static void main( String[] args ){
LinkedHashMap<String, String> map = new LinkedHashMap<>();
for (int i=0;i<10;i++){
map.put("key"+i,"value"+i);
}
map.get("key"+3);
for (String value:map.keySet()){
System.out.println(value);
}
}
}
添加规则是可以使用LinkedHashMap;
7.1 多线程环境下,可以使用concurrent包下有一个ConcurrentHashMap,它使用分段锁来保证线程安全;
7.2 Collections.synchronizedMap保证线程安全,效率比HashTable高;

标签:返回值 安全 override int 适用于 二叉树 string hash lse
原文地址:https://www.cnblogs.com/wnwn/p/12503600.html