标签:print 编码 converter 进制 pre decode 等于 seve base
当SIM800L模块工作在文本模式(AT+CMGF=1),使用AT+CMGR=1读取的非中文短信会直接返回内容,中文短信会显示16进制值,比如:
+CMGL: 1,"REC UNREAD","10655000531001147525","","20/03/15,16:01:31+32" 30104F174FE160A054C965C56E3830115C0A656C76844F1A5458FF0C60A876849A8C8BC17801662FFF1A003100370031003900370038FF0C67096548671F003100305206949FFF0C8BF75728987597624E2D586B51996B649A8C8BC17801FF0C8FDB884C540E7EED64CD4F5C3002 // 短信内容为:【众信悠哉旅游】尊敬的会员,您的验证码是:171978,有效期10分钟,请在页面中填写此验证码,进行后续操作。
当AT+CSDH=1时,会返回更详细的资料:
+CMGR: <stat>,<oa>[,<alpha>],<scts>[,<tooa>,<fo>,<pid>,<dcs>,<sca>,<tosca>,<length>]<CR><LF><data>
当AT+CSDH=0时(模块默认值),只会返回:
+CMGR: <stat>,<oa><CR><LF><data>
STM32单片机将短信内容通过SIM800L发送到我们服务器后端时, 如果是中文短信需要将16进制值转换成中文字符串。
如何在JAVA中转换? 根据【参考资料1】中我们得知,可以用DatatypeConverter类中的parseHexBinary方法:
String input = "30104F174FE160A054C965C56E383011"; byte[] bytes = DatatypeConverter.parseHexBinary(input); String result = new String(bytes); System.out.println(result);
然后我就测试了,发现乱码。。。
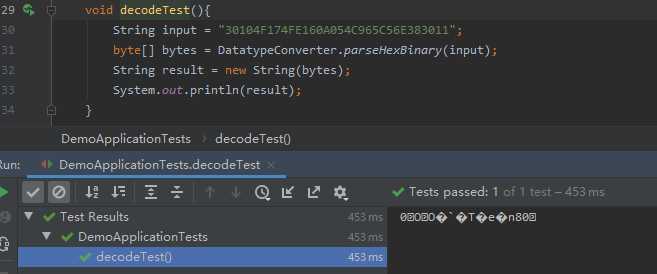
查看String类的构造方法【参考资料2】发现可以输入一个字节数组和一个指定的字符集解码,然后我尝试了"UTF-8","GBK",都不行,仍然是乱码。
然后我就去查了String构造方法中的Charset参数【参考资料3】,发现Charset类中这几类标准字符集:
Charset Description US-ASCII Seven-bit ASCII, a.k.a. ISO646-US, a.k.a. the Basic Latin block of the Unicode character set ISO-8859-1 ISO Latin Alphabet No. 1, a.k.a. ISO-LATIN-1 UTF-8 Eight-bit UCS Transformation Format UTF-16BE Sixteen-bit UCS Transformation Format, big-endian byte order UTF-16LE Sixteen-bit UCS Transformation Format, little-endian byte order UTF-16 Sixteen-bit UCS Transformation Format, byte order identified by an optional byte-order mark
然后就想了,怎么确定SIM800L模块返回的16进制值用的是哪种编码呢?
反推吧,我用中文字符串生成这六种编码方式的字节数组,然后将字节数组转换成字符串。
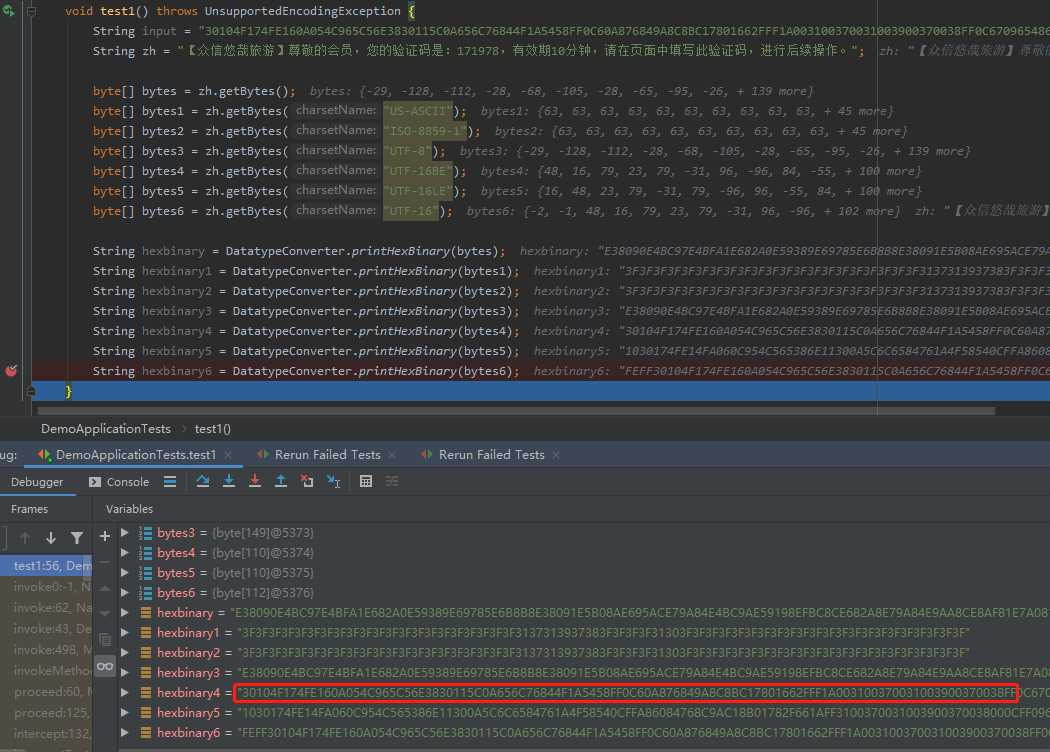
发现采用的就是 "UTF-16BE",然后我将前面的代码加入指定字符集后测试成功:
String input = "30104F174FE160A054C965C56E383011"; byte[] bytes = DatatypeConverter.parseHexBinary(input); String result = new String(bytes,"UTF-16BE"); System.out.println(result);
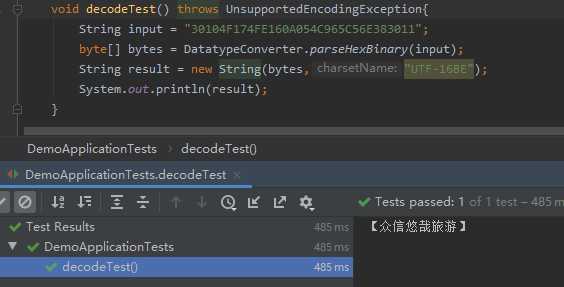
然后我就想看看他们三是啥关系:UTF-16BE UTF-16LE UTF-16,根据【参考资料4】
UTF-16BE:utf-16 big-endian 大端序,也称大尾序
UTF-16LE:utf-16 little-endian 小端序,也称小尾序
UTF-16: 基于不同的平台默认使用以上两种尾序,比如苹果Mac系统中 UTF-16 = UTF-16BE;Windows和Linux中 UTF-16 = UTF-16LE。
上两张直观的图【来源】

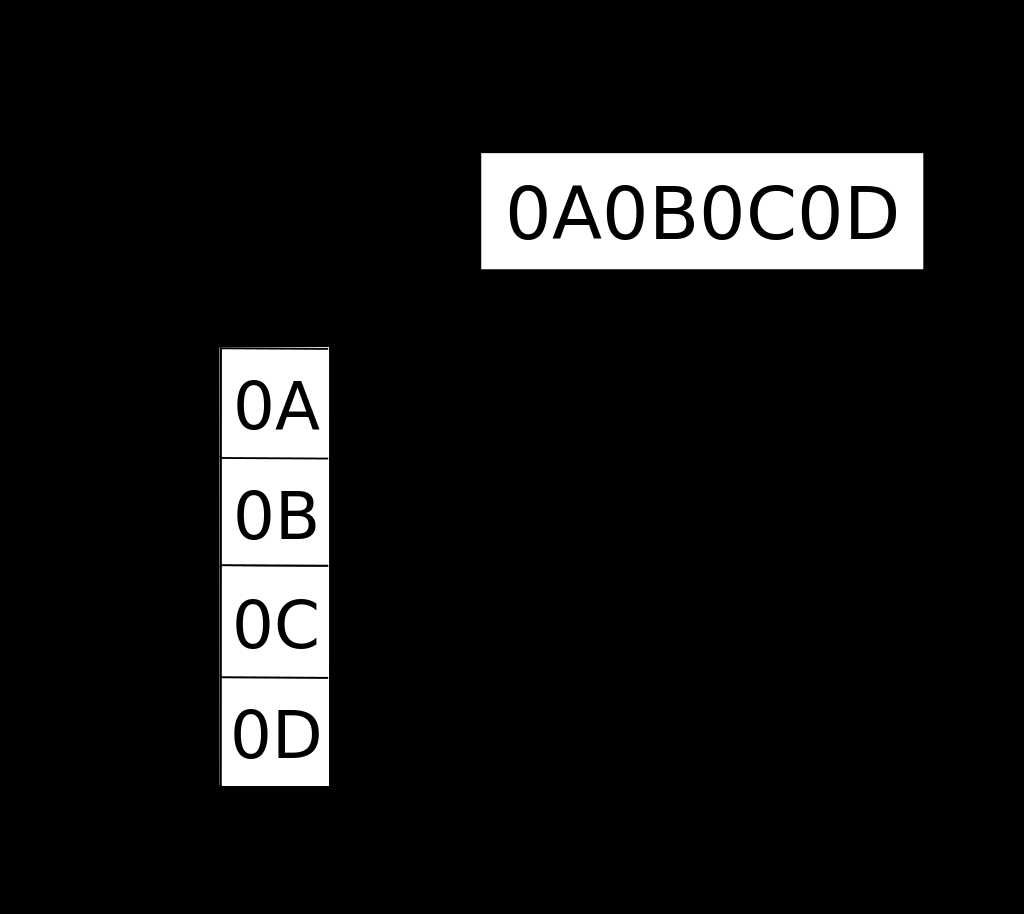
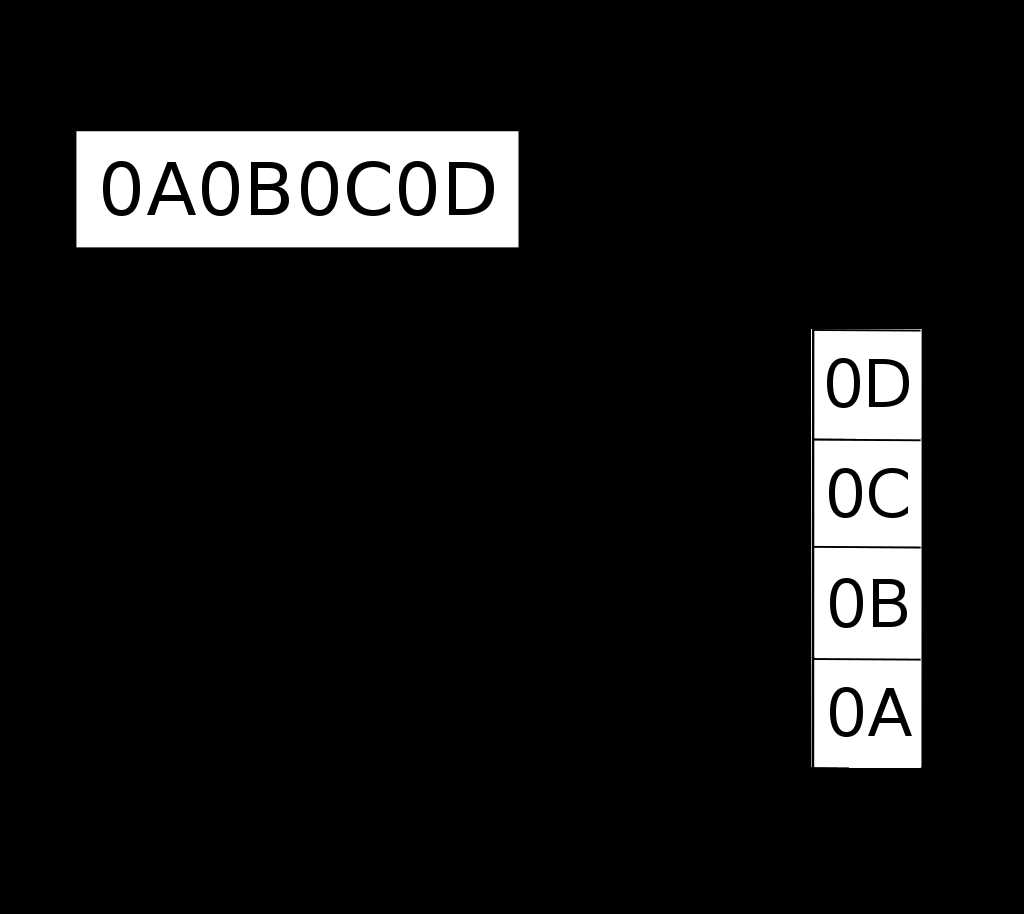
看到UTF-16 和UCS-2的关系才想起来,SIM800的中文编码就是采用的UCS-2
UTF-16可看成是UCS-2的父集。在没有辅助平面字符(surrogate code points)前,UTF-16与UCS-2所指的是同一的意思。但当引入辅助平面字符后,就称为UTF-16了。现在若有软件声称自己支持UCS-2编码,那其实是暗指它不能支持在UTF-16中超过2字节的字集。对于小于0x10000的UCS码,UTF-16编码就等于UCS码。
然后我就回过头去测试了一下 "UTF-16"字符集 发现也OK
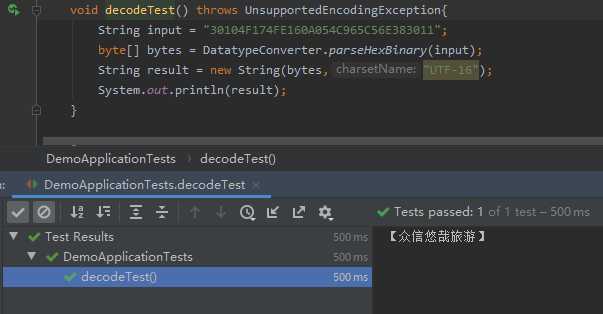
根据【这里】的资料说明,Java平台中UTF-16默认使用大端序,所以指定UTF-16字符集也可以成功解码。
参考资料1:https://www.baeldung.com/java-base64-encode-and-decode
参考资料2:https://docs.oracle.com/javase/7/docs/api/java/lang/String.html
参考资料3:https://docs.oracle.com/javase/7/docs/api/java/nio/charset/Charset.html
参考资料4:https://zh.wikipedia.org/wiki/UTF-16
参考资料5:https://zh.wikipedia.org/wiki/%E5%AD%97%E8%8A%82%E5%BA%8F#%E5%A4%A7%E7%AB%AF%E5%BA%8F
标签:print 编码 converter 进制 pre decode 等于 seve base
原文地址:https://www.cnblogs.com/1x11/p/12507175.html