标签:为我 持久性 提交 存储管理 iso cat img 字段表 资源

作者 |?李响、张磊
从 2019 年初开始,阿里巴巴云原生应用平台团队开始逐步在整个阿里经济体内,基于标准应用定义与交付模型进行应用管理产品与项目统一架构升级的技术工作。
事实上,早在 2018 年末,当 Kubernetes 项目正式成为阿里巴巴的应用基础设施底盘之后,阿里内部以及阿里云产品线在应用管理领域的碎片化问题就开始日渐凸显出来。
尤其是在云原生生态日新月异的今天,阿里巴巴与阿里云的应用管理产品架构(包括阿里内部 PaaS 和云上 PaaS 产品),如何以最佳姿态拥抱云原生生态、如何以最高效的技术手段借助生态日新月异的能力构建出更强大的 PaaS 服务,而不是重复造轮子甚至和生态“背道而驰”,很快就成为了阿里团队亟待解决的重要技术难题。
但棘手的是,这个问题并不是简单把 PaaS 迁移或者集成到 Kubernetes 上来就能够解决的:PaaS 与 Kubernetes 之间,从来就没有存在这样一条清晰的分界线,可是 Kubernetes 本身又并不是面向最终用户设计的。
如何既让全公司的研发和运维充分享受云原生技术体系革新带来的专注力与生产力提升,又能够让现有 PaaS 体系无缝迁移、接入到 Kubernetes 大底盘当中,还要让新的 PaaS 体系把 Kubernetes 技术与生态的能力和价值最大程度的发挥出来,而不是互相“屏蔽”甚至“打架”?这个“既要、又要、还要”的高标准要求,才是解决上述 “Kubernetes vs PaaS” 难题的关键所在。
在 2019 年 10 月,阿里巴巴宣布联合微软共同推出开放应用模型项目(Open Application Model - OAM),正是阿里进行自身应用管理体系标准化与统一架构升级过程中,逐步演进出来的一项关键技术。
所谓“应用模型”,其实是一个专门用来对云原生应用本身和它所需运维能力进行定义与描述的标准开源规范。所以对于 Kubernetes 来说,OAM 即是一个标准的“应用定义”项目(类比已经不再活跃的 Kubernetes Application CRD 项目),同时也是一个专注于封装、组织和管理 Kubernetes 中各种“运维能力”、以及连接“运维能力”与“应用”的平台层项目。而通过同时提供“定义应用”和“组织管理应用的运维能力”这两大核心功能,OAM 项目自然成为了阿里巴巴进行统一应用架构升级和构建下一代 PaaS/Serverless 过程中“当仁不让”的关键路径。
此外,OAM 模型并不负责应用和能力的具体实现,从而确保了它们都是由 Kubernetes 本身直接提供的 API 原语和控制器实现。所以, OAM 也成为了当前阿里构建 Kubernetes 原生 PaaS 的一项主要手段。
在 OAM 中,一个应用程序包含三个核心理念:
阿里巴巴在 OAM 这个项目中融入了大量互联网规模场景中管理 Kubernetes 集群和公共云产品方面的实际经验,特别是阿里从原先不计其数的内部应用 CRD 转向基于 OAM 的标准应用定义过程中的诸多收获。作为工程师,我们从过去的失败和错误中吸取教训,不断开拓创新、发展壮大。
在本文中,我们将会详细分享 OAM 项目背后的动机和推动力,希望能够帮助更多人更好地了解这个项目。
<br />我们是阿里巴巴的“基础设施运维人员”,或者说 Kubernetes 团队。具体来说,我们负责开发、安装和维护各种 Kubernetes 级别的功能。具体工作包括但不限于维护大规模的 K8s 集群、实现控制器/Operator,以及开发各种 K8s 插件。在公司内部,我们通常被称为“平台团队(Platform Builder)”。
不过,为了与兄弟团队区分,即那些在我们之上基于 K8s 构建的 PaaS 工程人员区分,我们在本文中将自称为“基础设施运维人员(Infra Operator)”。过去几年里,我们已通过 Kubernetes 取得了巨大成功,并在使用过程中通过出现的问题获取了宝贵的经验教训。
<br />毫无疑问,我们为阿里巴巴电商业务维护着世界上最大、最复杂的 Kubernetes 集群,这些集群:
同时,我们还协助支持着阿里云的 Kubernetes 服务(ACK),该服务类似于面向外部客户的其他公有云 Kubernetes 产品,其中包含大量集群(约 1 万个),不过通常均为小型或中型的集群。我们的内部和外部客户在工作负载管理方面的需求和用例非常多样化。
与其他互联网公司类似,阿里巴巴的技术栈由基础设施运维人员、应用运维人员和业务研发人员合作完成。业务研发和应用运维人员的角色可以概括如下:
以代码形式传递业务价值。大多数业务研发都对基础设施或 K8s 不甚了解,他们与 PaaS 和 CI 流水线交互以管理其应用程序。业务研发人员的生产效率对公司而言价值巨大。
为业务研发人员提供有关集群容量、稳定性和性能的专业知识,帮助业务研发人员大规模配置、部署和运行应用程序(例如,更新、扩展、恢复)。请注意,尽管应用运维人员对 K8s 的 API 和功能具有一定了解,但他们并不直接在 K8s 上工作。在大多数情况下,他们利用 PaaS 系统为业务研发人员提供基础 K8s 功能。在这种情况下,许多应用运维人员实际上也是 PaaS 工程人员。
总之,像我们这样的基础设施运维人员为应用运维人员提供服务,他们随之为业务研发人员提供服务。
综上所述,这三方显然拥有不同的专业知识,但他们却需要协调一致以确保顺利工作。这在 Kubernetes 的世界里可能很难实现!
我们将在下面的章节中介绍不同参与方的痛点,但简而言之,我们面临的根本问题是不同参与方之间缺乏一种标准化的方法来进行高效而准确的交互。这会导致低效的应用程序管理流程,甚至导致运行失败。
而标准应用模型正是我们解决此问题的关键方法。
Kubernetes 具有高度的可扩展性,使得基础设施运维人员能够随心所欲地构建自己的运维功能。但 Kubernetes 巨大的灵活性也是一把双刃剑:这些功能的用户(即应用运维人员)会遇到一些棘手的问题。
举例来说,在阿里巴巴,我们开发了 CronHPA CRD 以根据 CRON 表达式扩展应用程序。当应用程序的水平扩展策略希望在白天和晚上有所不同时,这非常有用。CronHPA 是一种可选功能,仅在集群中按需部署。
CronHPA 的 yaml 示例如下所示:
apiVersion: “app.alibaba.com/v1”
kind: CronHPA
metadata:
name: cron-scaler
spec:
timezone: America/Los_Angeles
schedule:
- cron: ‘0 0 6 * * ?’
minReplicas: 20
maxReplicas: 25
- cron: ‘0 0 19 * * ?’
minReplicas: 1
maxReplicas: 9
template:
spec:
scaleTargetRef:
apiVersion: apps/v1
name: php-apache
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50这是一个典型的 Kubernetes 自定义资源(CRD),可以直接安装使用。
但是,当我们把这些功能交付出去,应用运维人员开始使用诸如 CronHPA 等自定义插件时,他们很快就遇到麻烦了:
应用运维人员经常抱怨这些插件功能的使用方法(也就是 spec) 分布的非常随意。它有时位于 CRD 中,有时位于 ConfigMap 中,有时又位于某个随机位置的配置文件中。此外,他们还感到非常困惑:为什么 K8s 中很多插件(例如,CNI 和 CSI 插件)的 CRD 并不是对应的能力(例如:网络功能和存储功能)描述,而只是那些插件本身的安装说明?
应用运维人员对某项运维能力是否已在集群中准备就绪毫无把握,尤其是当该能力是新开发的插件提供时更是如此。基础设施运维人员和应用运维人员之间需要进行多轮沟通,才能澄清这些问题。
除上述可发现性问题外,还有一个与可管理性相关的额外难题。
K8s 集群中的运维能力之间的关系可以概括为以下三类:
正交和可组合能力相对安全。然而,互相冲突的功能可能导致意外/不可预测的行为。
这里的问题在于, Kubernetes 很难事先向应用运维人员发送冲突警告。因此,他们可能会对同一应用程序使用彼此冲突的两个运维能力。而当实际发生冲突时,解决冲突会产生高昂的成本,在极端情况下,这些冲突会导致灾难性的故障。当然,在管理平台能力时,应用运维人员显然不希望面临“头顶悬着达摩克里斯之剑”的情况,因此希望找到一种更好的方法来提前避免冲突情况。
应用运维人员如何发现和管理可能相互冲突的运维能力?换而言之,作为基础设施运维人员,我们能否为应用运维人员构建可发现且易管理的运维能力呢?
在 OAM 中,我们通过“运维特征(Trait)”来描述和构建具备可发现性和可管理性的平台层能力。
这些平台层能力实质上是应用程序的运维特征,而这正是 OAM 中“Trait”这个名称的来历。
在阿里的 K8s 集群中,大多数 Trait 都由基础设施运维人员定义,并使用 Kubernetes 中的自定义控制器实现,例如:
请注意, Trait 并不等同于 K8s 插件。比如:一个集群可具有多个网络相关 Trait ,如“动态 QoS ?Trait ”、“带宽控制 Trait ”和“流量镜像 Trait ”,这些 Trait 均由一个 CNI 插件提供。
实际上, Trait 安装在 K8s 集群中,并供应用运维人员使用。将能力作为 Trait 呈现时,应用运维人员使用简单的 kubectl get 命令即可发现当前集群支持的运维能力:
$ kubectl get traitDefinition
NAME AGE
cron-scaler 19m
auto-scaler 19m上面的示例显示此集群支持两种 “scaler” 能力。用户可以将需要基于 CRON 的扩展策略的应用程序部署到该集群。
Trait 提供给定运维能力的结构化描述。
这使应用运维人员通过简单的 kubectl describe 命令即可轻松准确地理解特定能力,而不必深入研究其 CRD 或文档。能力描述包括“此 Trait 适用于何种工作负载”和“它的使用方式”等。
例如,kubectl describe traitDefinition cron-scaler:
apiVersion: core.oam.dev/v1alpha2
kind: TraitDefinition
metadata:
name: cron-scaler
spec:
appliesTo:
- core.oam.dev/v1alpha1.ContainerizedWorkload
definitionRef:
name: cronhpas.app.alibaba.com请注意,在 OAM 中, Trait 通过 definitionRef 引用 CRD 来描述其用法,同时也与 K8s 的 CRD 解耦。
Trait 采用了规范与实现分离的设计,同样一个 Trait 的 spec,可以被不同平台不同环境完全基于不同的技术来实现。通过引用的方式,实现层既可以对接到一个已有实现的 CRD,也可以对接到一个统一描述的中间层,底下可插拔的对接不同的具体实现。考虑到 K8s 中的一个特定的能力比如 Ingress 可能有多达几十种实现,这种规范与实现分离的思想会非常有用。Trait 提供了统一的描述,可帮助应用运维人员准确理解和使用能力。
应用运维人员通过使用 ApplicationConfiguration(将在下一部分中详细介绍),对应用程序配置一个或多个已安装的 Trait 。ApplicationConfiguration 控制器将处理 Trait 冲突(如果有)。
我们以此示例 ApplicationConfiguration 为例:
apiVersion: core.oam.dev/v1alpha2
kind: ApplicationConfiguration
metadata:
name: failed-example
spec:
components:
- name: nginx-replicated-v1
traits:
- trait:
apiVersion: core.oam.dev/v1alpha2
kind: AutoScaler
spec:
minimum: 1
maximum: 9
- trait:
apiVersion: app.alibabacloud.com/v1
kind: CronHPA
spec:
timezone: "America/Los_Angeles"
schedule: "0 0 6 * * ?"
cpu: 50
...在 OAM 中,ApplicationConfiguration 控制器必须保证这些 Trait 之间的兼容性,如果不能满足要求,应用的部署就会立刻失败。所以,当运维人员将上述 YAML 提交给 Kubernetes 时,由于“Trait 冲突”,OAM 控制器将会报告部署失败。这就使得应用运维人员能够提前知道有运维能力冲突,而不是在部署失败后大惊失色。
总的来说,我们团队不提倡提供冗长的维护规范和运维指南(它们根本无法防止应用运维人员出错),我们倾向于是使用 OAM ?Trait 来对外暴露基于 Kubernetes 的可发现和可管理的运维能力。这使我们的应用运维人员能够“快速失败”,并满怀信心地组合运维能力来构建无冲突的应用运维解决方案,这就像玩“乐高积木”一样简单。
Kubernetes 的 API 对象并不关心自己的使用者到底是运维还是研发。这意味着任何人都可能对一个 Kubernetes API 对象中的任何字段负责。这也称为“all-in-one”的 API,它使得新手很容易上手。
但是,当具有不同关注点的多个团队必须在同一个 Kubernetes 集群上展开协作时,特别是当应用运维人员和业务研发人员需要在相同 API 对象上展开协作时,all-in-one API 缺点就会凸显出来。
让我们先来看一个简单的 Deployment YAML 文件:
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
deploy: example
template:
metadata:
labels:
deploy: example
spec:
containers:
- name: nginx
image: nginx:1.7.9
securityContext:
allowPrivilegeEscalation: false在我们的集群中,应用运维人员与业务研发人员需要面对面开会来填写这个 yaml 文件。这种合作既耗时又复杂,但我们别无选择。原因何在?
显而易见,这里最直接的方法是让业务研发人员自己填写 Deployment yaml。但是,业务研发人员可能会发现 Deployment 里的某些字段与他们的关注点没有丝毫关联。例如:
有多少业务研发人员知道 allowPrivilegeEscalation 是什么意思?
事实上,很少有业务研发人员知道,在生产环境里,这个字段务必要设置为 false (默认是 true),才能确保应用程序在宿主机中具有合理的权限。在实践中,这个字段只能应用运维人员配置。而现实是,一旦把整个 Deployment 暴露给业务研发填写,这些字段最终就会沦为“猜谜游戏”,甚至完全被业务研发人员忽视。
如果你了解 K8s 的话,就一定会发现 K8s 中有大量的 API 字段很难说清楚到底是应该由研发还是运维来填写。
例如,当业务研发人员设置 Deployment 的 replicas:3 时,他会假设该数字在应用程序生命周期中固定不变。
但是,大多数业务研发人员并不知道 Kubernetes 的 HPA 控制器可以接管该字段,并可能会根据 Pod 负载改变 replicas 的值。这种由系统自动化流程带来的变更很容易导致问题:这意味着当业务研发人员想要更改副本数时,他对 replicas 的修改可能根本不会生效。
在此种情况下,一个 Kubernetes 的 YAML 文件就不能表示工作负载的最终状态,从业务研发人员角度而言,这非常令人困惑。我们曾尝试使用 fieldManager 来处理此问题,但 fieldManager 进行冲突解决的过程仍颇具挑战性,因为我们很难弄清这些冲突方的修改目的。
如上所示,当使用 K8s API 时,业务研发人员和运维人员的关注点会不可避免地被混在一起。这使得多个参与方可能很难基于同一个 API 对象展开协作。
此外,我们也发现,阿里内部的很多应用程序管理系统(如 PaaS)并不愿意暴露 K8s 的全部能力,显然他们并不希望向业务研发人员暴露更多的 Kubernetes 概念。
对于上述问题,最简单的解决方案是在业务研发人员和运维人员之间划一条“明确的界限”。例如,我们可以仅允许业务研发人员设置 Deployment yaml 的一部分字段(这正是阿里很多 PaaS 曾经采用的办法)。但是,这种“割裂研发与运维”的解决方案可能并不奏效。
在很多情况下,业务研发人员都希望运维人员听取他们的一些关于运维的“意见”。
例如,假定业务研发人员为应用程序定义了 10 个参数,然后他们发现应用运维人员可能会覆盖这些参数以适配不同的运行环境的差异。那么问题来了:业务研发如何才能做到仅允许运维人员修改其中特定的 5 个参数?
实际上,如果采用“割裂研发与运维”应用管理流程,要传达业务研发人员的运维意见将变得难上加难。这样类似的例子有许多,业务研发人员可能希望表述很多关于他们的应用程序的信息:
上述所有这些请求都是合理的,因为只有业务研发人员才是最了解应用程序的那个人。这就提出了一个我们亟待解决的重要问题:我们的 Kubernetes 能否既为业务研发和运维人员提供单独的 API,同时又允许业务研发人员有效传达自己对运维的诉求?
在 OAM 中,我们从逻辑上对 K8s 的 API 对象进行了拆分,并且做到了既使得业务研发人员能够填写属于自己的那些字段,同时又能有条理地向运维人员传达诉求。
定义你的应用程序,而不是仅仅描述它。
<br />在 OAM 中,Component(组件) 就是一个完全面向业务研发人员设计的、用于定义应用程序而不必考虑其运维详细信息的载体。一个应用程序包含一个或多个 Component 。例如,一个网站应用可以由一个 Java web 组件和一个数据库组件组成。
以下是业务研发人员为 Nginx 部署定义的 Component 示例:
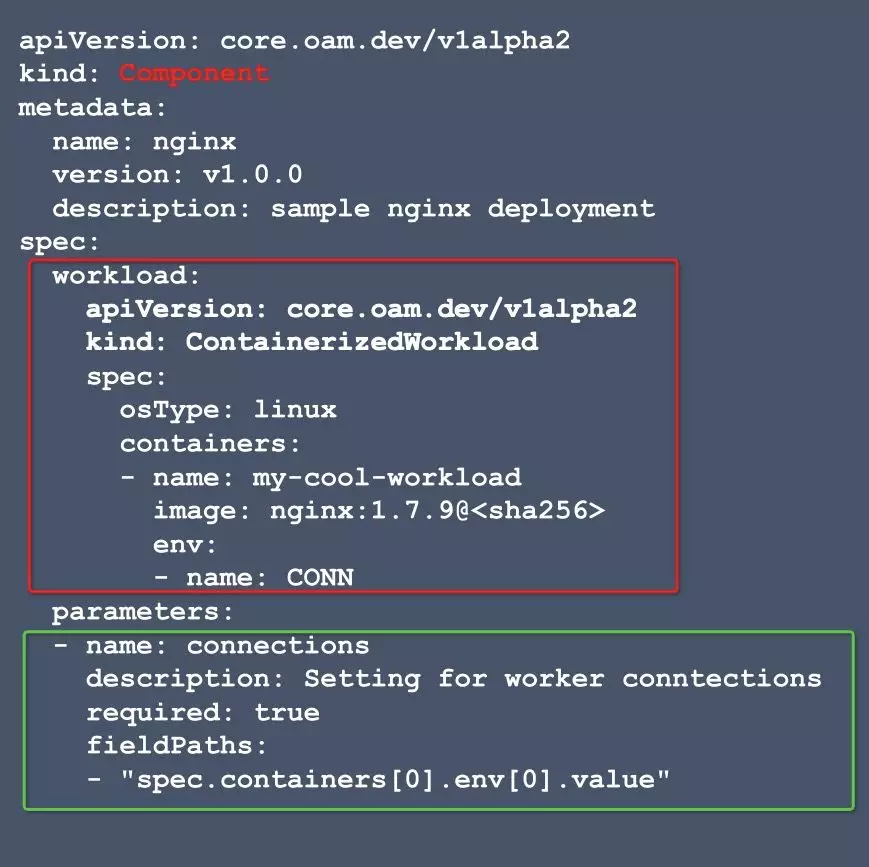
OAM 中的 Component 包含两个部分:
在 Component 中,workload 字段可以直接向运维人员传达业务研发人员关于如何运行其应用程序的说明。同时,OAM 围绕容器应用定义了一种核心工作负载 ContainerizedWorkload,涵盖了云原生应用程序的典型模式。
与此同时,OAM 可以通过定义扩展工作负载来自由声明用户自己的工作负载类型。在阿里巴巴,我们在很大程度上依赖于扩展工作负载来使业务研发人员定义阿里云服务 Component ,例如,阿里云函数计算 Component 等。
请注意,在上面的示例中,业务研发人员不再需要设置副本数;因为这并不是他所关注的字段:他选择让 HPA 或应用运维人员完全控制副本数的值。
总体来说,Component 允许业务研发人员使用自己的方式定义应用程序的声明式描述,但同时也为他/她提供了随时向运维人员准确传达意见或信息的能力。这些信息包括对运维的诉求,例如,“如何运行此应用程序”和“可重写参数”。
最终,通过引用 Component 名称并对它绑定 Trait ,运维人员就可以使用 ApplicationConfiguration 来实例化应用程序。
使用 Component 和 ApplicationConfiguration 的示例协作工作流:
这个 app-config.yaml 文件的内容如下所示:
apiVersion: core.oam.dev/v1alpha1
kind: ApplicationConfiguration
metadata:
name: my-awesome-app
spec:
components:
- componentName: nginx
parameterValues:
- name: connections
value: 4096
traits:
- trait:
apiVersion: core.oam.dev/v1alpha2
kind: AutoScaler
spec:
minimum: 1
maximum: 9
- trait:
apiVersion: app.aliaba.com/v1
kind: SecurityPolicy
spec:
allowPrivilegeEscalation: false我们来重点说明以上 ApplicationConfiguration YAML 中的一些详细信息:
parameterValues —— 供运维人员使用,用于将 connections 值重写为 4096,在该组件中,该值最初为 1024。请注意,运维人员必须填写整数 4096,而不是字符串 "4096",因为此字段的 schema 已在 Component 中明确定义;
Trait ?AutoScaler —— 供运维人员使用,用于将 autoscaler ?Trait (如 HPA)绑定给 Component 。因此,其副本数将完全由 autoscaler 控制;
实质上,ApplicationConfiguration 的主要功能,就是让应用运维人员(或系统)了解和使用业务研发人员传达的信息,然后自由的为 Component 组合绑定不同的运维能力以相应实现其最终的运维目的。
综上所述,我们使用 OAM 的主要目标是解决应用程序管理中的以下问题:
所以说,对于阿里巴巴来说,OAM 其实是阿里巴巴 Kubernetes 团队提出的一种 Application CRD 规范,从而使得所有参与者可以采用结构化的标准方法来定义应用程序及其运维能力。
阿里巴巴开发 OAM 的另一个强大动力,则是在混合云和多环境中进行软件分发与交付。随着 Google Anthos 和 Microsoft Arc 的出现,我们已然看到 Kubernetes 正成为新的 Android,并且云原生生态系统的价值正迅速转移到应用层的趋势。我们将在以后讨论这一主题。
本文中的实际使用案例由阿里云原生团队和蚂蚁金服共同提供。
目前,OAM 规范和模型实际已解决许多现有问题,但它的路程才刚刚开始。例如,我们正在研究使用 OAM 处理组件依赖关系、在 OAM 中集成 Dapr 工作负载等。
我们期待在 OAM 规范及其 K8s 实现方面与社区展开协作。OAM 是一个中立的开源项目,其所有贡献者都应遵循非营利性基金会的 CLA。
目前,阿里巴巴团队正在上游贡献和维护这套技术,如果大家有什么问题或者反馈,也非常欢迎与我们在上游或者钉钉联系。
参与方式:

作者简介
李响,阿里云资深技术专家。他在阿里巴巴从事集群管理系统工作,并协助推动阿里巴巴集团内的 Kubernetes 采用。在效力于阿里巴巴之前,李响曾是 CoreOS Kubernetes 上游团队的负责人。他还是 etcd 和 Kubernetes Operator 的创建者。
张磊,阿里云高级技术专家。他是 Kubernetes 项目的维护者之一。张磊目前在阿里的 Kubernetes 团队工作,其工作领域包括 Kubernetes 和云原生应用管理系统。
云原生应用平台诚邀?Kubernetes / Serverless / PaaS / 应用交付领域专家( P6-P8 )加盟:
简历立刻回复,2~3 周出结果,简历投递:jianbo.sjb AT alibaba-inc.com。

“阿里巴巴云原生关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术圈。”
标签:为我 持久性 提交 存储管理 iso cat img 字段表 资源
原文地址:https://blog.51cto.com/13778063/2478772