标签:margin gray host 复选框 正则表达式 了解 format 存储 保存
之前分享的 [日志分析]Graylog2采集Nginx日志 主动方式 这篇文章介绍了Graylog如何通过Graylog Collector Sidecar来采集nginx日志。
由于日志是未经处理的,所以类似$remote_addr $request_time $upstream_addr $upstream_response_time的字段并没有解析出来,而是都显示在默认的message中,很不利于我们今后的分析工作。
为了解决这个问题,就引入了graylog另一个非常强大的功能 Extractors ,Extractors 翻译过来叫提取器,顾名思义,就是将原始日志的各个字段通过正则匹配的方式提取并保存到相对应的字段中。
针对这次nginx的字段提取,我着重讲一下Extractors的Grok pattern用法。这是日常生产处理原始日志 ,最常用的一种方式。
(1)先去查看nginx配置文件的log_format选项:
log_format access ‘$remote_addr - [$time_local] $request_time $upstream_addr $upstream_response_time "$request_method $scheme://$host$request_uri" $status $body_bytes_sent "$http_referer" "$http_user_agent" "$http_x_forwarded_for"‘;
(2)根据log_format的输出格式编写相应的正则表达式,简单讲解一下以^%{IP:remote_addr} 为例,^代表日志开头,大括号里面的IP代表名为IP的grok pattern,可以在System/Grok pattern中查到,冒号后边就是你要存储的字段名称为remote_addr 。
^%{IP:remote_addr} - \[%{HTTPDATE:time_local}\] %{DATA:request_time} %{DATA:upstream_addr} %{DATA:upstream_response_time} \"%{NOTSPACE:method} %{NOTSPACE:url}\" %{NOTSPACE:status} %{DATA:body_bytes_sent} %{DATA:http_referer} \"%{DATA:http_user_agent}\"\s+\"%{DATA:http_x_forwarded_for}\"
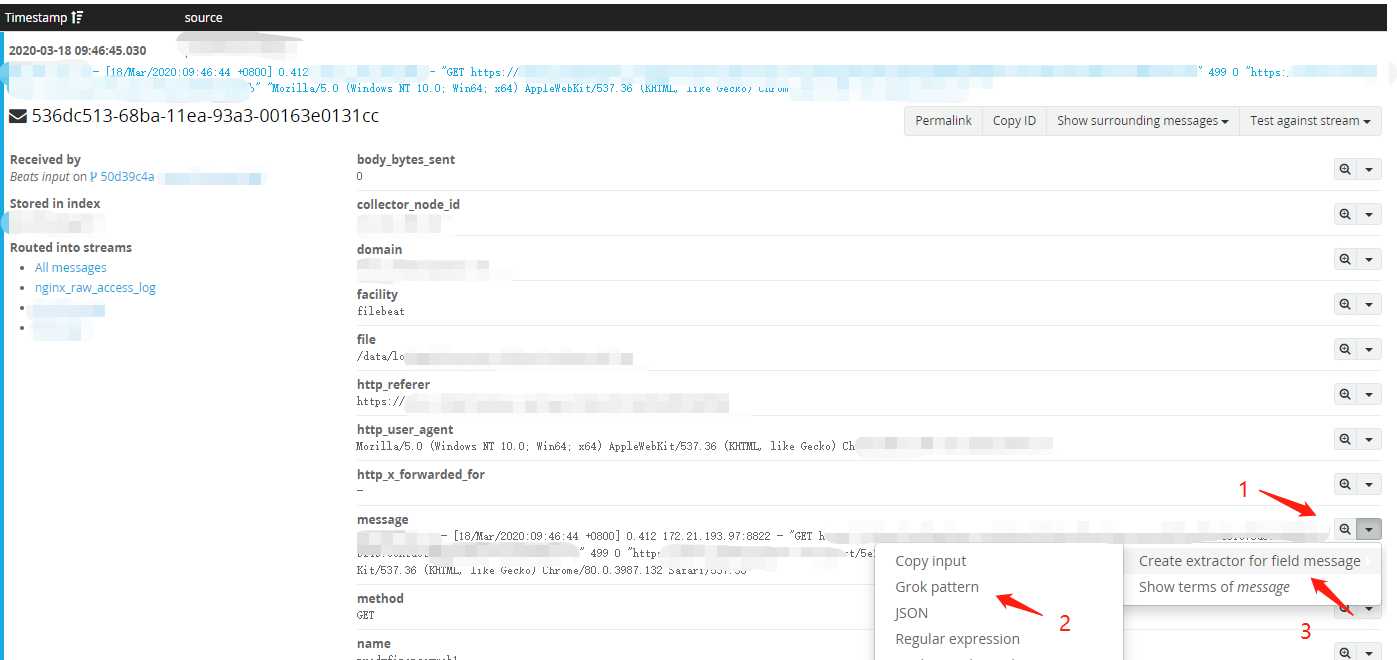
(3) 在导航栏Search 选择一条nginx日志,在message字段右边,点击小三角选择 Grok pattern -> Creat extractor for field message 到Extractors 页面。
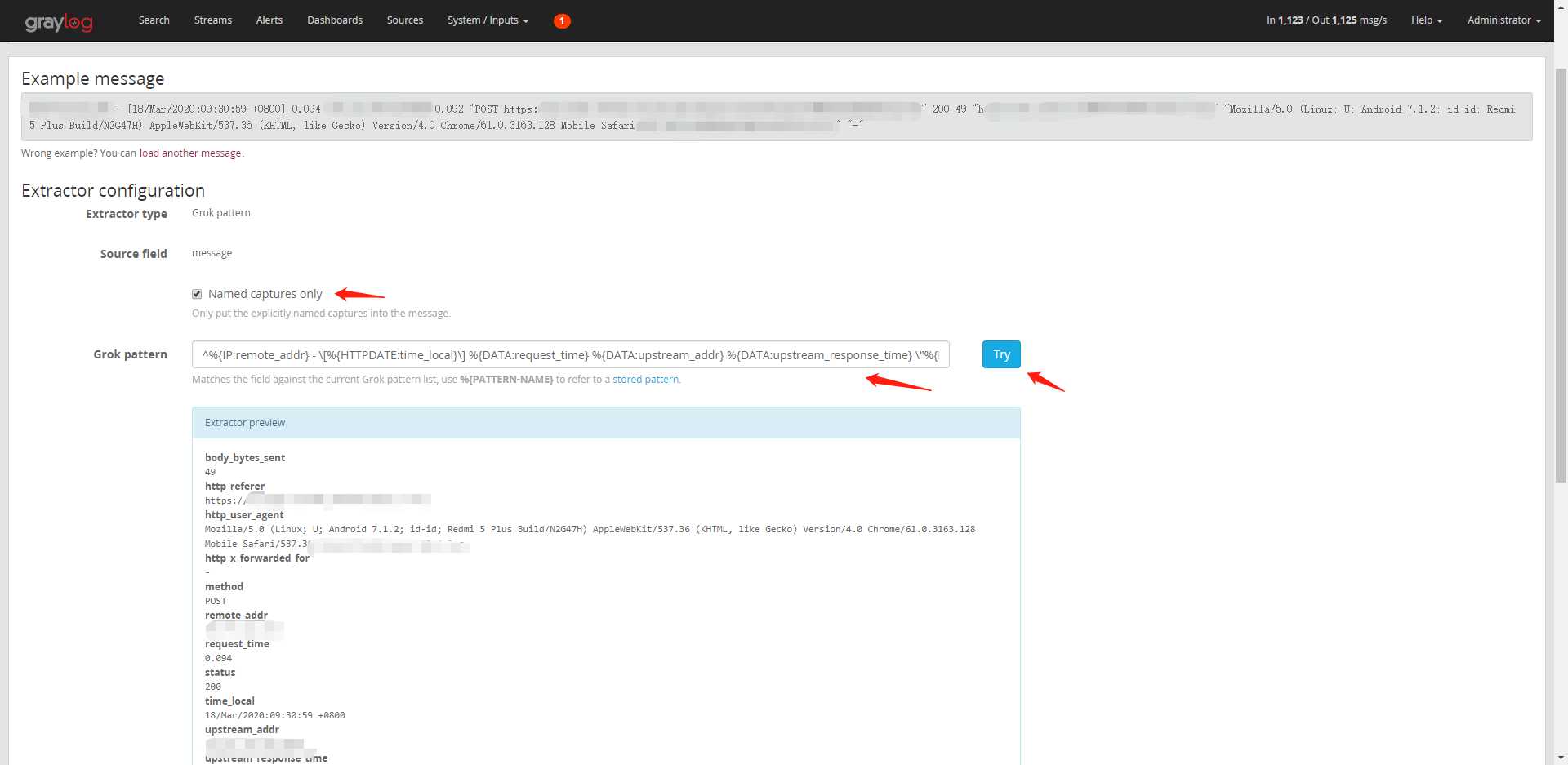
(2)选中Named captures only复选框,Grok pattern填入正则,点击Try可以看到解析后的笑果,相应的字段已经解析出来了。

标签:margin gray host 复选框 正则表达式 了解 format 存储 保存
原文地址:https://www.cnblogs.com/graylog/p/12515667.html