标签:参数 颜色 science htm 维度 包括 关联 href sem
内容来源:
https://jakevdp.github.io/PythonDataScienceHandbook/00.00-preface.html
机器学习是用数据科学的计算能力和算法能力去弥补统计方法的不足,其最终结果是为那些目前既没有高效的理论支持、又没有高效的计算方法的统计推理与数据探索问题提供解决方法。
机器学习本质上就是借助数学模型理解数据,即在模型上调整可以观测数据的参数来预测并解释新的观测数据。
机器学习一般可以分为两类:有监督学习(supervised learning)和无监督学习(unsupervised learning)。
有监督学习是指对数据的若干特征与若干标签(类型)之间的关联性进行建模的过程,只要模型被确定,就可以应用到新的未知数据上。
有监督学习可以进一步分类为分类(classification)任务与回归(regression)任务。
在分类任务中,标签都是离散值;而在回归任务中,标签都是连续值。
无监督学习是指对不带任何标签的数据特征进行建模,通常被看成是一种‘让数据自己介绍自己‘的过程。
无监督学习包括聚类(clustering)任务和降维(dimensionality reduction)任务。
聚类算法可以将数据分成不同的组别,而降维算法追求用更简洁的方式表现数据。
半监督学习(semi-supervised learning)方法,介于有监督学习与无监督学习之间。
半监督学习方法通常可以在数据标签不完整时使用。
数据点都有两个特征,在平面上数据点的位置(x,y),颜色表示的类型标签
其中的模型就是一条可以分类的直线,模型参数是直线的位置与方向的数值
可以用现有数据训练模型,来对一个新的不带标签的数据分类。
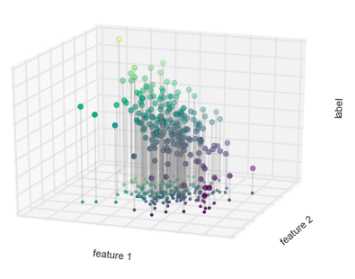
每个数据点有两个特征,数据点的颜色表示每个点的连续标签
用简单线性回归模型作出假设,如果我们把标签看成是第三个维度,那么就可以将数据拟合成一个平面方程。
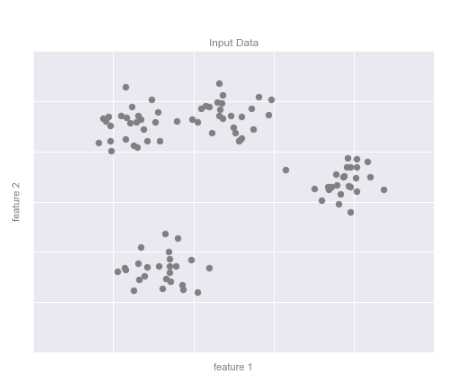
数据被聚类算法自动分成若干离散的组别
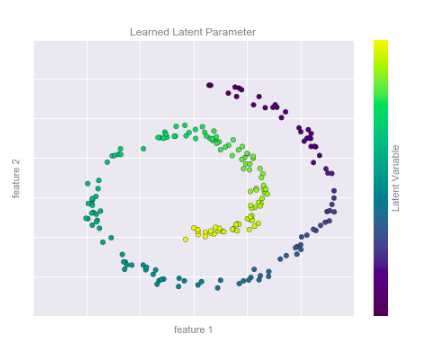
降维需要从数据集本身的结构推断标签和其他信息,其实就是在保证高维数据质量的条件下从中抽取出一个低维数据集
可以训练带标签的数据以预测新数据标签的模型
可以预测两个或多个离散分类标签的模型
可以预测连续标签的模型
识别无标签数据结构的模型
检测、识别数据显著组别的模型
从高维数据中检测、识别低维数据结构的模型
标签:参数 颜色 science htm 维度 包括 关联 href sem
原文地址:https://www.cnblogs.com/nuochengze/p/12516035.html