标签:form 包括 教育 dom values col weight 房产 type
该赛题使用公开数据的问卷调查结果,选取其中多组变量
包括个体变量(性别、年龄、地域、职业、健康、婚姻与政治面貌等等)
家庭变量(父母、配偶、子女、家庭资本等等)
社会态度(公平、信用、公共服务等等)
来预测其对幸福感的评价
将提供的训练数据的幸福度标签独立出来,并将除了幸福度标签的训练数据和待测试的数据合并
这样就省去既要处理训练数据又要处理测试数据的冗余,一次解决
df_train = pd.read_csv("happiness_train_complete.csv",encoding="ansi")
df_test = pd.read_csv("happiness_test_complete.csv",encoding="ansi")
y_train = df_train['happiness']
df_train.drop(["happiness"],axis=1,inplace=True)
df_all = pd.concat((df_train,df_test),axis=0)查看幸福度标签的分布情况:
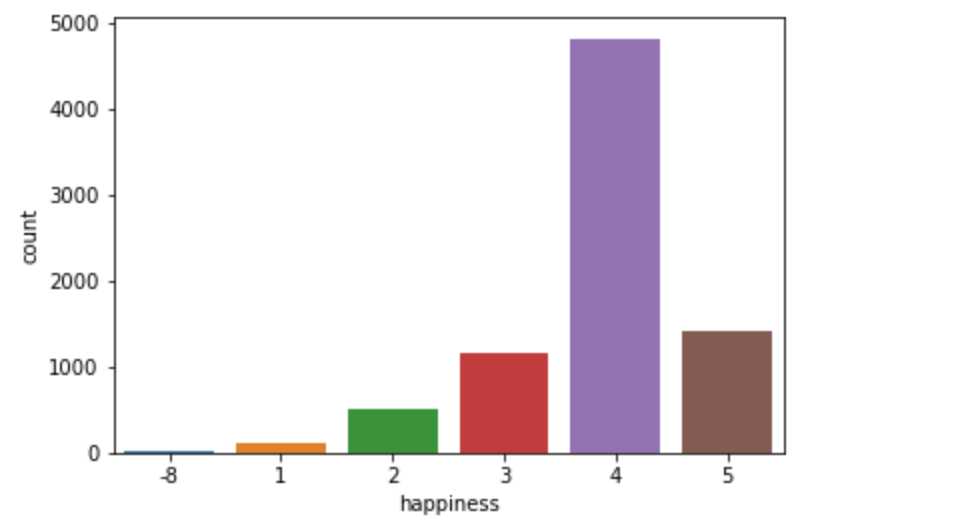
其中-8指无法回答,也就意味着不知道自己是幸福或者还是不幸福
因此,将其当做幸福度的中间值来处理
y_train = y_train.map(lambda x:3 if x==-8 else x)然后统计各个属性的缺失情况
total = df_all.isnull().sum().sort_values(ascending=False)
percent = (df_all.isnull().sum()/df_all.isnull().count()).sort_values(ascending=False)
missing_data = pd.concat([total,percent], axis=1, keys=['total', 'percent'])
missing_data[missing_data['percent']>0]前期处理完成
数据预处理的措施:删除缺失过多的属性;对缺失少的属性进行填充
删除缺失值高达60%的属性:
df_all.drop( [‘edu_other‘,‘invest_other‘,‘property_other‘,‘join_party‘,
‘s_work_type‘,‘s_work_status‘,‘work_status‘,
‘work_yr‘,‘work_manage‘,‘work_type‘,],axis=1,inplace=True)
然后在对缺失值低于60%的值进行填充
#配偶情况
#全部缺失值填充为0 因为这些缺失值是因为没有结婚而导致的
df_all['s_political'].fillna(0,inplace=True)
df_all['s_hukou'].fillna(0,inplace=True)
df_all['s_income'].fillna(0,inplace=True)
df_all['s_birth'].fillna(0,inplace=True)
df_all['s_edu'].fillna(0,inplace=True)
df_all['s_work_exper'].fillna(0,inplace=True)
#教育情况
#全部缺失值填充为0 由没有受过教育而导致的
df_all['edu_status'].fillna(0,inplace=True)
df_all['edu_yr'].fillna(0,inplace=True)
#社交情况
#缺失值是由于社交不频繁造成的,全部缺失值填充为7
df_all['social_friend'].fillna(7,inplace=True)
df_all['social_neighbor'].fillna(7,inplace=True)
# 婚姻情况
df_all['marital_now'].fillna(2015,inplace=True)
df_all['marital_1st'].fillna(2015,inplace=True)
# 家庭收入
#family_income只有一条空记录,用平均值填充
df_all['family_income'].fillna(df_all['family_income'].mean(),inplace=True)
# 户口情况 缺失值是由于没有户口造成的,全部缺失值填充为4
df_all['hukou_loc'].fillna(4,inplace=True)
#孩子情况 全部填充为0,因为没有孩子
df_all['minor_child'].fillna(0,inplace=True)
print(len(df_all))对一些分布不均匀或者相关性较差的属性删除,并同时构造一些新特征
先删除一些特征,这些特征分布及其不均匀且相关性也差
宗教不均匀
sns.countplot(x='religion', data=df_all)
df_all.drop(['religion','religion_freq'],axis=1,inplace=True)房产不均匀,只保留property_1和property_2
df_all.drop(['property_0','property_3','property_4','property_5',
'property_6','property_7','property_8'],axis=1,inplace=True)保险不均匀 全都删除
df_all.drop(['insur_1','insur_2','insur_3','insur_4'],axis=1,inplace=True)基本没人投资 全部删除
df_all.drop(['invest_0','invest_1','invest_2','invest_3','invest_4',
'invest_5'],axis=1,inplace=True)删除父母亲的政治面貌
df_all.drop(['f_political','m_political'],axis=1,inplace=True)根据现有属性,构造一些新特征,或者对属性进行泛化
对所处阶层的负值进行替换
df_all['class'] = df_all['class'].map(lambda x:5 if x==-8 else x)按照小学,初中,高中等常见教育等级进行划分
因为所给数据的教育等级粒度太细,故进一步泛化
def edu_split(x):
if x in [1,2,14]:
return 0
elif x in [3]:
return 1
elif x in [4]:
return 2
elif x in [5,7,8]:
return 3
elif x in [6]:
return 4
elif x in [9,10]:
return 5
elif x in [11,12]:
return 6
elif x in[13]:
return 7
df_all["edu"]=df_all["edu"].map(edu_split)因为不同的时间会有不同的感受
故把一天的时间分段
def hour_cut(x):
if 0<=x<6:
return 0
elif 6<=x<8:
return 1
elif 8<=x<12:
return 2
elif 12<=x<14:
return 3
elif 14<=x<18:
return 4
elif 18<=x<21:
return 5
elif 21<=x<24:
return 6
df_all["hour_cut"]=df_all["hour"].map(hour_cut)出生年代划分
def birth_split(x):
if(x<1920):
return 0
if 1920<=x<=1930:
return 1
elif 1930<x<=1940:
return 2
elif 1940<x<=1950:
return 3
elif 1950<x<=1960:
return 4
elif 1960<x<=1970:
return 5
elif 1970<x<=1980:
return 6
elif 1980<x<=1990:
return 7
elif 1990<x<=2000:
return 8
df_all["birth_s"]=df_all["birth"].map(birth_split)构造新特征 BMI 人体肥胖指数
并对新特征进行分类
def get_fat(x):
if(x<0):
return 1
elif(x>0 and x<18.5):
return 1
elif(x>=18.5 and x<=23.9):
return 2
elif(x>=24 and x<=26.9):
return 3
elif(x>26.9 and x<29.9):
return 4
else:
return 5
df_all['bmi]= df_all['weight_jin']/2)/(df_all['height_cm']/100)**2
df_all["fat"] = df_all["bmi"].map(get_fat)对收入进行分级 按照2015的标准
收入分级
def get_income_class(x):
if(x<=0):
return 0
if 0< x < 2800:
return 1
elif 2800<= x <10000:
return 2
elif 10000 <= x <27000:
return 3
elif 27000<= x <100000:
return 4
else : return 5对省份进行分级
def province_split(x):
if x in [6,1,12,28,13]:
return 0
elif x in [24,29,26,2,8,22,21]:
return 1
elif x in [16,31]:
return 2
elif x in [9,7,15,11,18,30,27,19]:
return 3
elif x in [23,5,10,4,3,17,4]:
return 4# 使用z-score方法 对数量值数据进行规范化
numeric_cols=['height_cm','s_income','house','family_income','family_m'
,'son','daughter','minor_child','inc_exp','public_service_1',
'public_service_2','public_service_3','public_service_4',
'public_service_5','public_service_6','public_service_7',
'public_service_8','public_service_9','aver_area','mar_yr']
# 再对标称数据进行规范化
numeric_cols_means=df_all.loc[:,numeric_cols].mean()
numeric_cols_std=df_all.loc[:,numeric_cols].std()
df_numeric=(df_all.loc[:,numeric_cols]-numeric_cols_means)/numeric_cols_std使用lgb和xgbootst进行融合
#lgb的参数设定
param = {'boosting_type': 'gbdt',
'num_leaves': 20,
'min_data_in_leaf': 19,
'objective':'regression',
'max_depth':9,
'learning_rate': 0.01,
"min_child_samples": 30,
"feature_fraction": 0.91,
"bagging_freq": 1,
"bagging_fraction": 0.75,
"bagging_seed": 11,
"metric": 'mse',
"lambda_l1": 0.15,
"verbosity": -1}
# xgb的参数设定
xgb_params = {"booster":'gbtree','eta': 0.01, 'max_depth': 5, 'subsample': 0.7,
'colsample_bytree': 0.6, 'objective': 'reg:linear', 'eval_metric': 'rmse',
'silent': True, 'nthread': 8}
#采用stacking 融合lgb和xgb这两个模型
train_stack = np.vstack([oof_lgb,oof_xgb]).transpose()
test_stack = np.vstack([predictions_lgb,predictions_xgb]).transpose()
folds_stack = RepeatedKFold(n_splits=5, n_repeats=2, random_state=2018)
oof_stack = np.zeros(train_stack.shape[0])
predictions = np.zeros(test_stack.shape[0])
for fold_, (trn_idx, val_idx) in enumerate(folds_stack.split(train_stack,y_train)):
print("fold {}".format(fold_))
trn_data, trn_y = train_stack[trn_idx], y_train[trn_idx]
val_data, val_y = train_stack[val_idx], y_train[val_idx]
clf_3 = linear_model.BayesianRidge()
#clf_3 =linear_model.Ridge()
clf_3.fit(trn_data, trn_y)
oof_stack[val_idx] = clf_3.predict(val_data)
predictions += clf_3.predict(test_stack) / 10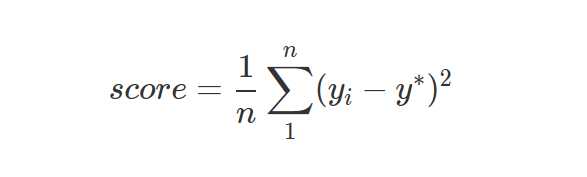
模型融合后,训练score是0.45887818
线上0.46316
代码见github
标签:form 包括 教育 dom values col weight 房产 type
原文地址:https://www.cnblogs.com/ASE265/p/12521044.html