标签:优化 nbsp bsp 撰写 html_ with open int 下载 open
本次过程仅供学习参考,请遵守相关法律法规。
首先我们分析网站:https://www.mzitu.com/all/
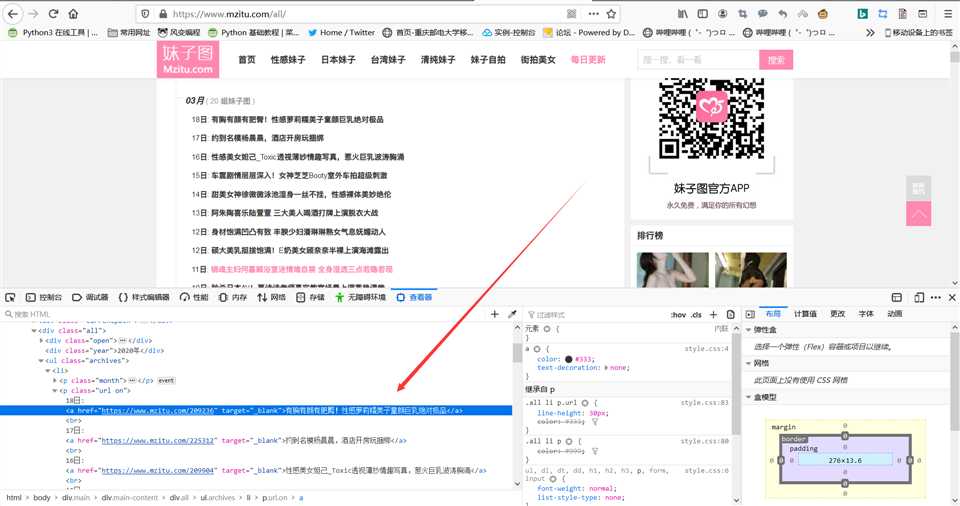
不难发现,这个页面上包含了大量的图片链接,可以说是特别方便我们爬取图片的,这是件好事。那么我们继续分析
这是第一页的地址
这是第二页的,所以我们爬取的时候只需要在链接后面增加“/num”即可
那么我们先来爬取首页的内容
import requests import re #爬取首页 url = ‘https://www.mzitu.com/all/‘ header = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0‘ } response = requests.get(url, headers = header).text print(response)
我们可以得到以下

ok 接下来我们需要从中提取我们想要的链接
#使用正则表达式提取需要的链接
req = ‘<br>.*?日: <a href="(.*?)" target="_blank">(.*?)</a>‘
urls = re.findall(req,response)
for url,pic_name in urls:
print(url,pic_name)
这样我们就获得了我们需要的链接了

那么接来下我们需要知道的是每个链接里面到底有多少页呢
我们进一步分析网页观察页面源码我们可以发现
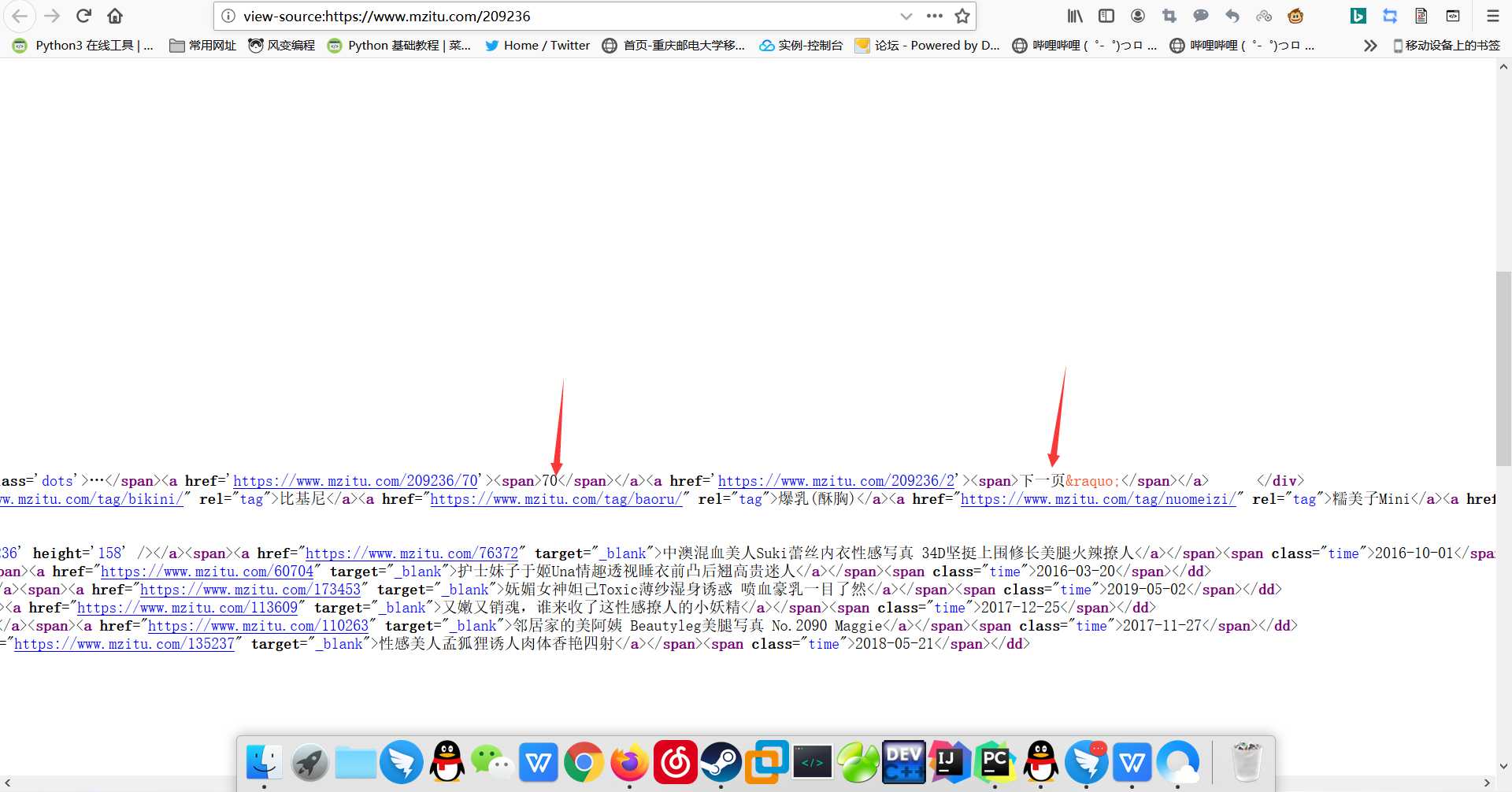
我们可以从页面中提取到最后一页的内容
req = ‘<br>.*?日: <a href="(.*?)" target="_blank">(.*?)</a>‘ urls = re.findall(req,response) for url,pic_name in urls: print(url,pic_name) #获取每个url内的总页面数目 html = requests.get(url, headers=header).text req_last = "<a href=‘.*?‘><span>«上一组</span></a><span>1</span><a href=‘.*?‘><span>2</span></a><a href=‘.*?‘><span>3</span></a><a href=‘.*?‘><span>4</span></a><span class=‘dots‘>…</span><a href=‘.*?‘><span>(.*?)</span></a><a href=‘.*?‘><span>下一页»</span></a> </div>" last_num = re.findall(req_last,html) print(last_num) exit()
我们使用正则将所需要的最后一页的页码提取出来即可获得结果

那么接下来就是拼接url了
我们尝试在原本的第一页的url后添加“/1”发现也可以进入我们需要的页面这大大降低了代码量
#将列表转化为int for k in last_num: k=k k = int(k) #拼接url for i in range(1,k): url_pic = url + ‘/‘ + str(i) print(url_pic) exit()
ps:这里的“exit()”是为了方便测试程序只要获得一个主url下的地址即可 后面将会删去
我们可以得到下面的链接

这些链接打开都是有效的但是我们打开的并不直接是图片的url
所以我们还要进一步对信息进行筛选,再优化一下代码
#将列表转化为int for k in last_num: k=k k = int(k) #拼接url for i in range(1,k): url_pic = url + ‘/‘ + str(i) headerss = { ‘User-Agent‘: ‘"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36"‘, ‘Referer‘: url_pic, ‘Host‘: ‘www.mzitu.com‘ } html_pic_last = requests.get(url_pic, headers=headerss).text req_last_pic = ‘<div class=.*?><p><a href=.*? ><img src="(.*?)" alt=.*? width=.*? height=.*? /></a></p>‘ req_pic_url = re.findall(req_last_pic,html_pic_last) for link in req_pic_url: link = link links = str(link) print(links) image_content = requests.get(links, headerss).content print(image_content) # with open("image/" + pic_name+ str(i) + ".jpg", "wb") as f: # f.write(image_content) exit()
可是经过测试,发现保存下来的图片无法打开,检查发现再最后一步下载图片的时候发生了403错误:服务器拒绝访问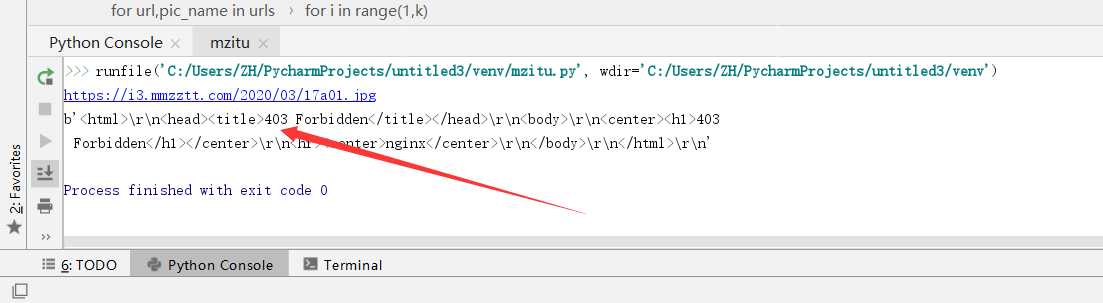
我试着换了herder可是还是不行,所以GG了!
附上目前为止全部源码
import requests import re #爬取首页 url_head = ‘https://www.mzitu.com/all/‘ header = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0‘, ‘Referer‘ :‘https://www.mzitu.com‘ } response = requests.get(url_head, headers = header).text #使用正则表达式提取需要的链接 req = ‘<br>.*?日: <a href="(.*?)" target="_blank">(.*?)</a>‘ urls = re.findall(req,response) for url,pic_name in urls: #获取每个url内的总页面数目 html = requests.get(url, headers=header).text req_last = "<a href=‘.*?‘><span>«上一组</span></a><span>1</span><a href=‘.*?‘><span>2</span></a><a href=‘.*?‘><span>3</span></a><a href=‘.*?‘><span>4</span></a><span class=‘dots‘>…</span><a href=‘.*?‘><span>(.*?)</span></a><a href=‘.*?‘><span>下一页»</span></a> </div>" last_num = re.findall(req_last,html) #将列表转化为int for k in last_num: k=k k = int(k) #拼接url for i in range(1,k): url_pic = url + ‘/‘ + str(i) headerss = { ‘User-Agent‘: ‘"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36"‘, ‘Referer‘: url_pic, } html_pic_last = requests.get(url_pic, headers=headerss).text req_last_pic = ‘<div class=.*?><p><a href=.*? ><img src="(.*?)" alt=.*? width=.*? height=.*? /></a></p>‘ req_pic_url = re.findall(req_last_pic,html_pic_last) for link in req_pic_url: link = link links = str(link) print(links) image_content = requests.get(links, headerss).content print(image_content) # with open("image/" + pic_name+ str(i) + ".jpg", "wb") as f: # f.write(image_content) exit() exit()
分析了一下我的代码 发现
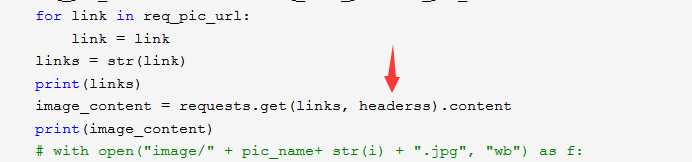
这里的headers没有给出定义,可能因为这个出现了bug 我修改了一下
image_content = requests.get(links, headers = headerss).content
这样测试一下
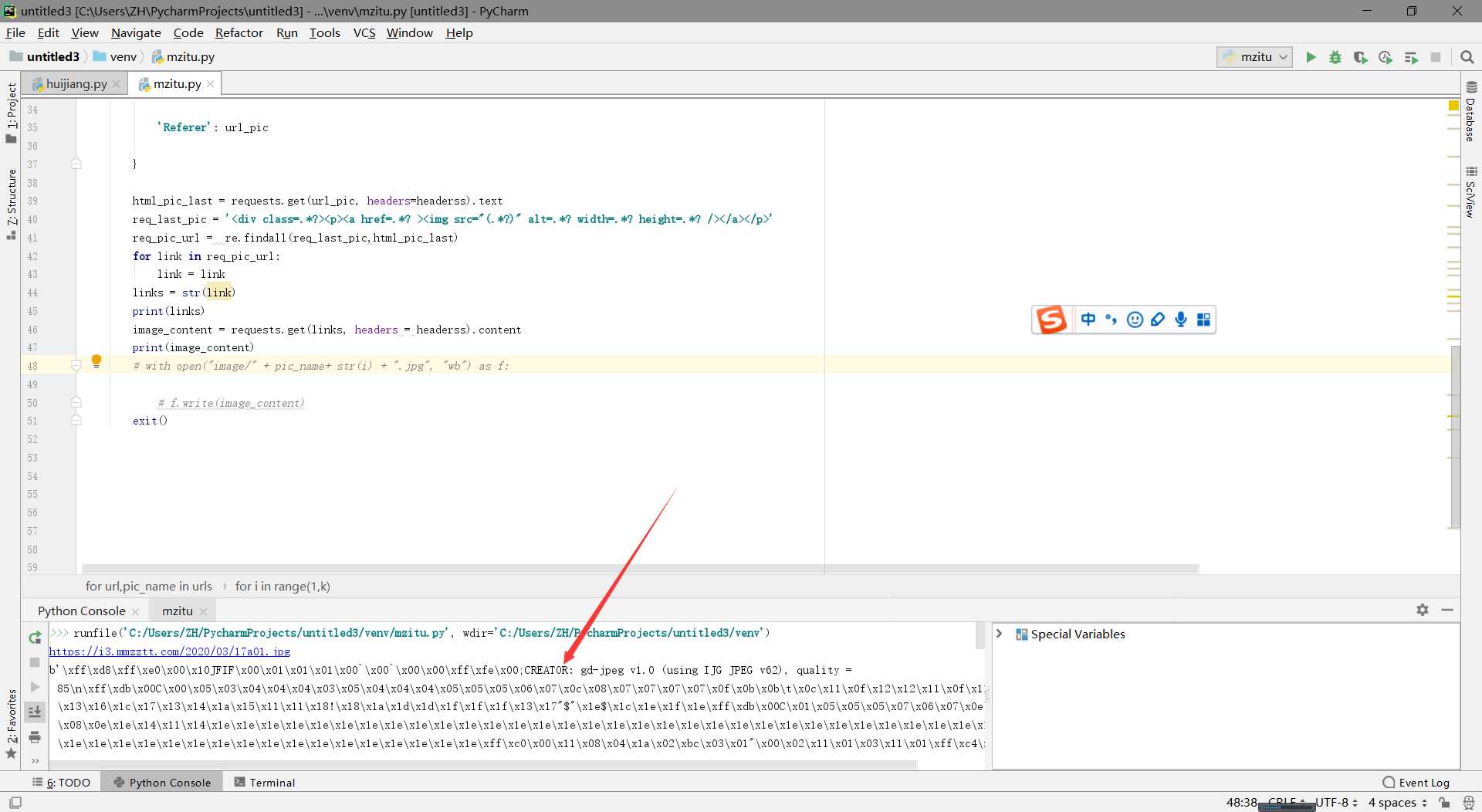
我们成功了!
完善代码
import requests import re #爬取首页 url_head = ‘https://www.mzitu.com/all/‘ header = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0‘, ‘Referer‘ :‘https://www.mzitu.com‘ } response = requests.get(url_head, headers = header).text #使用正则表达式提取需要的链接 req = ‘<br>.*?日: <a href="(.*?)" target="_blank">(.*?)</a>‘ urls = re.findall(req,response) for url,pic_name in urls: #获取每个url内的总页面数目 html = requests.get(url, headers=header).text req_last = "<a href=‘.*?‘><span>«上一组</span></a><span>1</span><a href=‘.*?‘><span>2</span></a><a href=‘.*?‘><span>3</span></a><a href=‘.*?‘><span>4</span></a><span class=‘dots‘>…</span><a href=‘.*?‘><span>(.*?)</span></a><a href=‘.*?‘><span>下一页»</span></a> </div>" last_num = re.findall(req_last,html) #将列表转化为int for k in last_num: k=k k = int(k) #拼接url for i in range(1,k): url_pic = url + ‘/‘ + str(i) headerss = { ‘User-Agent‘: ‘"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36"‘, ‘Referer‘: url_pic } html_pic_last = requests.get(url_pic, headers=headerss).text req_last_pic = ‘<div class=.*?><p><a href=.*? ><img src="(.*?)" alt=.*? width=.*? height=.*? /></a></p>‘ req_pic_url = re.findall(req_last_pic,html_pic_last) for link in req_pic_url: link = link links = str(link) print(links) image_content = requests.get(links, headers = headerss).content #保存图片 with open("image/" + pic_name+ str(i) + ".jpg", "wb") as f: f.write(image_content)
增加一点用户体验后的代码
import requests import re #爬取首页 sum = 0 url_head = ‘https://www.mzitu.com/all/‘ header = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0‘, ‘Referer‘ :‘https://www.mzitu.com‘ } response = requests.get(url_head, headers = header).text #使用正则表达式提取需要的链接 req = ‘<br>.*?日: <a href="(.*?)" target="_blank">(.*?)</a>‘ urls = re.findall(req,response) for url,pic_name in urls: #获取每个url内的总页面数目 html = requests.get(url, headers=header).text req_last = "<a href=‘.*?‘><span>«上一组</span></a><span>1</span><a href=‘.*?‘><span>2</span></a><a href=‘.*?‘><span>3</span></a><a href=‘.*?‘><span>4</span></a><span class=‘dots‘>…</span><a href=‘.*?‘><span>(.*?)</span></a><a href=‘.*?‘><span>下一页»</span></a> </div>" last_num = re.findall(req_last,html) #将列表转化为int for k in last_num: k=k k = int(k) #拼接url for i in range(1,k): url_pic = url + ‘/‘ + str(i) headerss = { ‘User-Agent‘: ‘"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36"‘, ‘Referer‘: url_pic } html_pic_last = requests.get(url_pic, headers=headerss).text req_last_pic = ‘<div class=.*?><p><a href=.*? ><img src="(.*?)" alt=.*? width=.*? height=.*? /></a></p>‘ req_pic_url = re.findall(req_last_pic,html_pic_last) for link in req_pic_url: link = link links = str(link) print(‘成功下载地址‘+links+"的图片") sum = sum +1 image_content = requests.get(links, headers = headerss).content #保存图片 with open("image/" + pic_name+ str(i) + ".jpg", "wb") as f: f.write(image_content) print("一共下载了"+str(sum)+"张图片")
让我们来看看最后的成果吧
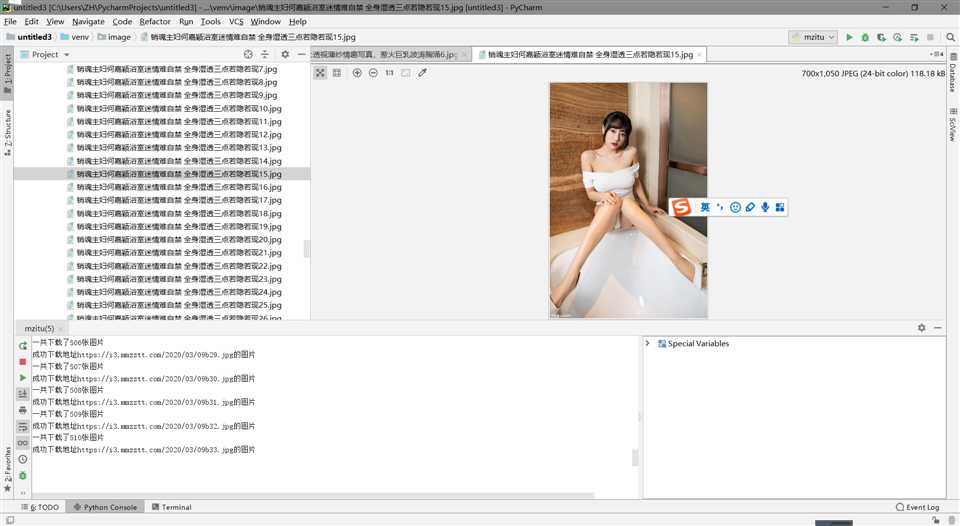
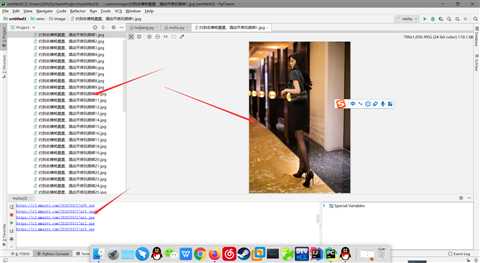
本文由作者亲自撰写,如有不足各位大佬提出来,如需转载请标明出处,谢谢
标签:优化 nbsp bsp 撰写 html_ with open int 下载 open
原文地址:https://www.cnblogs.com/mrkr/p/12521641.html