标签:enabled get graph 保存 %s 下载 pyopenssl normal using
爬虫框架是实现爬虫功能的一个软件结构和功能组件集合
爬虫框架是一个半成品,能够帮助用户实现专业网络爬虫
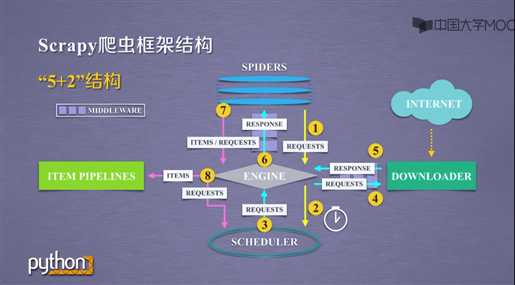
控制所有模块之间的数据流
根据条件触发事件
根据请求下载网页
Scheduler(不需要用户修改)
对所有爬取请求进行调度管理
目的:实施Engine、Scheduler、和Downloader之间进行用户可配置的控制
功能:修改、丢弃、新增请求或响应
用户可以编写配置代码
解析Downloader返回的响应(Response)
产生爬取项(scrapy item)
产生额外的爬取请求(Request)
需要用户编写配置代码
以流水线方式处理Spider产生的爬取项
由一组操作顺序组成,类似流水线,每个操作是一个Item Pipelines类型
可能操作包括:清理、检验和查重爬取项中的HTML数据、将数据存储到数据库
目的:对请求和爬取项的再处理
功能:修改、丢弃、新增请求或爬取项
用户可以编写配置代码
两者都可以进行页面请求和爬取,Python爬虫的两个重要技术路线
两者可用性都好,文档丰富,入门简单
两者都没有处理JS、提交表单、应对验证码等功能(可扩展)
| Request | Scrapy |
| 页面级爬虫 | 网站级爬虫 |
| 功能库 | 框架 |
| 并发性考虑不足,性能较差 | 并发性好,性能较高 |
| 重点在于页面下载 | 重点在于爬虫结构 |
| 定制灵活 | 一般定制灵活,深度定制困难 |
| 上手十分简单 | 入门稍难 |
Scrapy是为持续运行设计的专业爬虫框架,提供操作的Scrapy命令行
1 scrapy <command> [options] [args]
| 命令 | 说明 | 格式 |
| startproject | 创建一个新工程 | scrapy startproject<name>[dir] |
| genspider | 创建一个爬虫 | scrapy genspider[options]<name><domain> |
| settings | 获取爬虫配置信息 | scrapy settings[options] |
| crawl | 运行一个爬虫 | scrapy crawl<spider> |
| list | 列出工程中所有爬虫 | scrapy list |
| shell | 启动URL调式命令行 | scrapy shell[url] |
命令行语句
1 scrapy startproject python123demo #新建一个“python123demo”工程名的爬虫工程
工程目录为D:\Codes\Python>
1 D:\Codes\Python>scrapy startproject python123demo 2 New Scrapy project ‘python123demo‘, using template directory ‘d:\codes\python\venv\lib\site-packages\scrapy\templates\project‘, created in: 3 D:\Codes\Python\python123demo 4 5 You can start your first spider with: 6 cd python123demo 7 scrapy genspider example example.com
python123demo/ 外层目录
scrapy.cfg 部署Scrapy爬虫的配置文件
python123demo/ Scrapy框架的用户自定义Python代码
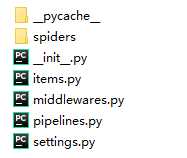
_init_.py 初始化脚本
Items.py Items代码模板(继承类)
middlewares.py Middlewares代码模板(继承类)
pipelines.py Pipelines代码模板(继承类)
settings.py Scrapy爬虫的配置文件
spiders/ Spiders代码模板目录(继承类)
_init_.py 初始文件,无需修改
_pycache_/ 缓存目录,无需修改
命令行语句
1 1 cd python123demo #打开python123demo文件夹 2 2 scrapy genspider demo python123.io #创建爬虫
先打开文件目录,再进行产生爬虫
1 D:\Codes\Python>cd python123demo 2 3 (venv) D:\Codes\Python\python123demo>scrapy genspider demo python123.io 4 Created spider ‘demo‘ using template ‘basic‘ in module: 5 python123demo.spiders.demo
此时在spiders文件夹下会生成一个demo.py文件
内容为
1 # -*- coding: utf-8 -*- 2 import scrapy 3 4 5 class DemoSpider(scrapy.Spider): 6 name = ‘demo‘ 7 allowed_domains = [‘python123.io‘] 8 start_urls = [‘http://python123.io/‘] 9 10 def parse(self, response): 11 pass
parse()用于处理响应,解析内容形成字典,发现新的URL爬取请求
修改demo.py内容
1 # -*- coding: utf-8 -*- 2 import scrapy 3 4 5 class DemoSpider(scrapy.Spider): 6 name = ‘demo‘ 7 #allowed_domains = [‘python123.io‘] 8 start_urls = [‘http://python123.io/ws/demo.html‘] 9 10 def parse(self, response): 11 fname = response.url.split(‘/‘)[-1] 12 with open(fname,‘wb‘) as f: 13 f.write(response.body) #将返回的内容保存为文件 14 self.log(‘Saved file %s.‘% fname)
命令行
1 scrapy crawl demo
运行爬虫
1 D:\Codes\Python\python123demo>scrapy crawl demo 2 2020-03-19 11:25:40 [scrapy.utils.log] INFO: Scrapy 2.0.0 started (bot: python123demo) 3 2020-03-19 11:25:40 [scrapy.utils.log] INFO: Versions: lxml 4.5.0.0, libxml2 2.9.5, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 19.10.0, Python 3.8.1 (tags/v3.8.1:1b293b6, Dec 18 2019, 22:39:24) [MSC v.1916 32 bit (Intel)], pyOpenSSL 19.1.0 (OpenSSL 1.1.1d 4 10 Sep 2019), cryptography 2.8, Platform Windows-10-10.0.18362-SP0 5 2020-03-19 11:25:40 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor 6 2020-03-19 11:25:41 [scrapy.crawler] INFO: Overridden settings: 7 {‘BOT_NAME‘: ‘python123demo‘, 8 ‘NEWSPIDER_MODULE‘: ‘python123demo.spiders‘, 9 ‘ROBOTSTXT_OBEY‘: True, 10 ‘SPIDER_MODULES‘: [‘python123demo.spiders‘]} 11 2020-03-19 11:25:41 [scrapy.extensions.telnet] INFO: Telnet Password: dbe958957137573b 12 2020-03-19 11:25:41 [scrapy.middleware] INFO: Enabled extensions: 13 [‘scrapy.extensions.corestats.CoreStats‘, 14 ‘scrapy.extensions.telnet.TelnetConsole‘, 15 ‘scrapy.extensions.logstats.LogStats‘] 16 2020-03-19 11:25:42 [scrapy.middleware] INFO: Enabled downloader middlewares: 17 [‘scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware‘, 18 ‘scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware‘, 19 ‘scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware‘, 20 ‘scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware‘, 21 ‘scrapy.downloadermiddlewares.useragent.UserAgentMiddleware‘, 22 ‘scrapy.downloadermiddlewares.retry.RetryMiddleware‘, 23 ‘scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware‘, 24 ‘scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware‘, 25 ‘scrapy.downloadermiddlewares.redirect.RedirectMiddleware‘, 26 ‘scrapy.downloadermiddlewares.cookies.CookiesMiddleware‘, 27 ‘scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware‘, 28 ‘scrapy.downloadermiddlewares.stats.DownloaderStats‘] 29 2020-03-19 11:25:42 [scrapy.middleware] INFO: Enabled spider middlewares: 30 [‘scrapy.spidermiddlewares.httperror.HttpErrorMiddleware‘, 31 ‘scrapy.spidermiddlewares.offsite.OffsiteMiddleware‘, 32 ‘scrapy.spidermiddlewares.referer.RefererMiddleware‘, 33 ‘scrapy.spidermiddlewares.urllength.UrlLengthMiddleware‘, 34 ‘scrapy.spidermiddlewares.depth.DepthMiddleware‘] 35 2020-03-19 11:25:42 [scrapy.middleware] INFO: Enabled item pipelines: 36 [] 37 2020-03-19 11:25:42 [scrapy.core.engine] INFO: Spider opened 38 2020-03-19 11:25:42 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min) 39 2020-03-19 11:25:42 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023 40 2020-03-19 11:25:42 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://python123.io/robots.txt> from <GET http://python123.io/robots.txt> 41 2020-03-19 11:25:42 [scrapy.core.engine] DEBUG: Crawled (404) <GET https://python123.io/robots.txt> (referer: None) 42 2020-03-19 11:25:42 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://python123.io/ws/demo.html> from <GET http://python123.io/ws/demo.html> 43 2020-03-19 11:25:42 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://python123.io/ws/demo.html> (referer: None) 44 2020-03-19 11:25:42 [demo] DEBUG: Saved file demo.html. 45 2020-03-19 11:25:42 [scrapy.core.engine] INFO: Closing spider (finished) 46 2020-03-19 11:25:42 [scrapy.statscollectors] INFO: Dumping Scrapy stats: 47 {‘downloader/request_bytes‘: 892, 48 ‘downloader/request_count‘: 4, 49 ‘downloader/request_method_count/GET‘: 4, 50 ‘downloader/response_bytes‘: 1901, 51 ‘downloader/response_count‘: 4, 52 ‘downloader/response_status_count/200‘: 1, 53 ‘downloader/response_status_count/301‘: 2, 54 ‘downloader/response_status_count/404‘: 1, 55 ‘elapsed_time_seconds‘: 0.644698, 56 ‘finish_reason‘: ‘finished‘, 57 ‘finish_time‘: datetime.datetime(2020, 3, 19, 3, 25, 42, 983695), 58 ‘log_count/DEBUG‘: 5, 59 ‘log_count/INFO‘: 10, 60 ‘response_received_count‘: 2, 61 ‘robotstxt/request_count‘: 1, 62 ‘robotstxt/response_count‘: 1, 63 ‘robotstxt/response_status_count/404‘: 1, 64 ‘scheduler/dequeued‘: 2, 65 ‘scheduler/dequeued/memory‘: 2, 66 ‘scheduler/enqueued‘: 2, 67 ‘scheduler/enqueued/memory‘: 2, 68 ‘start_time‘: datetime.datetime(2020, 3, 19, 3, 25, 42, 338997)} 69 2020-03-19 11:25:42 [scrapy.core.engine] INFO: Spider closed (finished)
捕获的页面存储在demo.html中
1 import scrapy 2 3 class DemoSpider(scrapy.Spider): 4 name = ‘demo‘ 5 6 def start_requests(self): 7 urls = [ 8 ‘http://python123.io/ws/demo.html‘ 9 ] 10 for url in urls: 11 yield scrapy.Request(url = url,callback = self.parse) 12 13 def parse(self, response): 14 fname = response.url.split(‘/‘)[-1] 15 with open(fname,‘wb‘) as f: 16 f.write(response.body) 17 self.log(‘Saved file %s.‘% fname)
start_requests(self)函数是一个生成器,当url数过多时,可以带来较好的资源占用
yield<--->生成器
生成器是一个不断产生值得函数
包含yield语句的函数是一个生成器
生成器每次产生一个值(yield语句),函数被冻结,被唤醒后再产生一个值
生成器写法
1 def gen(n): #定义gen()函数 2 for i in range(n): 3 yield i**2 4 5 for i in gen(5): 6 print(i," ",end = "") 7 0 1 4 9 16
生成器相比一次列出所有内容来说,更节省存储空间、响应更迅速、使用更灵活
普通写法
1 def square(n): #定义square()函数 2 ls = [i**2 for i in range(n)] 3 return ls 4 5 for i in range(5): 6 print(i," ",end = "") 7 0 1 2 3 4
普通写法将所有结果都存入一个列表中,占用空间大且耗时,不利于程序运行
class scrapy.http.Request()
Request对象表示一个HTTP请求
由Spider生成,由Downloader执行
| 属性或方法 | 说明 |
| .url | Request对应的请求URL地址 |
| .method | 对应的请求方法,’GET’’POST’等 |
| .headers | 字典类型风格的请求头 |
| .body | 请求内容主体,字符串类型 |
| .meta | 用户添加的扩展信息,在Scrapy内部模块间传递信息使用 |
| .copy() | 复制该请求 |
class scrapy.http.Response()
Response对象表示一个HTTP响应
由Downloader生成,由Spider处理
| 属性或方法 | 说明 |
| .url | Response对应的URL地址 |
| .status | HTTP状态码,默认是200 |
| .headers | Response对应的头部信息 |
| .body | Response对应的内容信息,字符串类型 |
| .flags | 一组标记 |
| .request | 产生Response类型对应的Request对象 |
| .copy() | 复制该响应 |
class scrapy.item.Item()
Item对象表示一个HTML页面中提取的信息内容
由Spider生成,由Item Pipeline处理
Item类型字典类型,可以按照字典类型操作
Scrapy爬虫支持多种HTML信息提取方法
Beautiful Soup
lxml
re
XPath Selector
CSS Selector
CSS Selector的基本使用
1 <HTML>.css(‘a::attr(href)’).extract()
CSS Selector由W3C组织维护并规范
资料来源:北京理工大学,嵩天,MOOC
标签:enabled get graph 保存 %s 下载 pyopenssl normal using
原文地址:https://www.cnblogs.com/huskysir/p/12522781.html