标签:each urllib 循环 ima 爬取 目标 png from beautiful
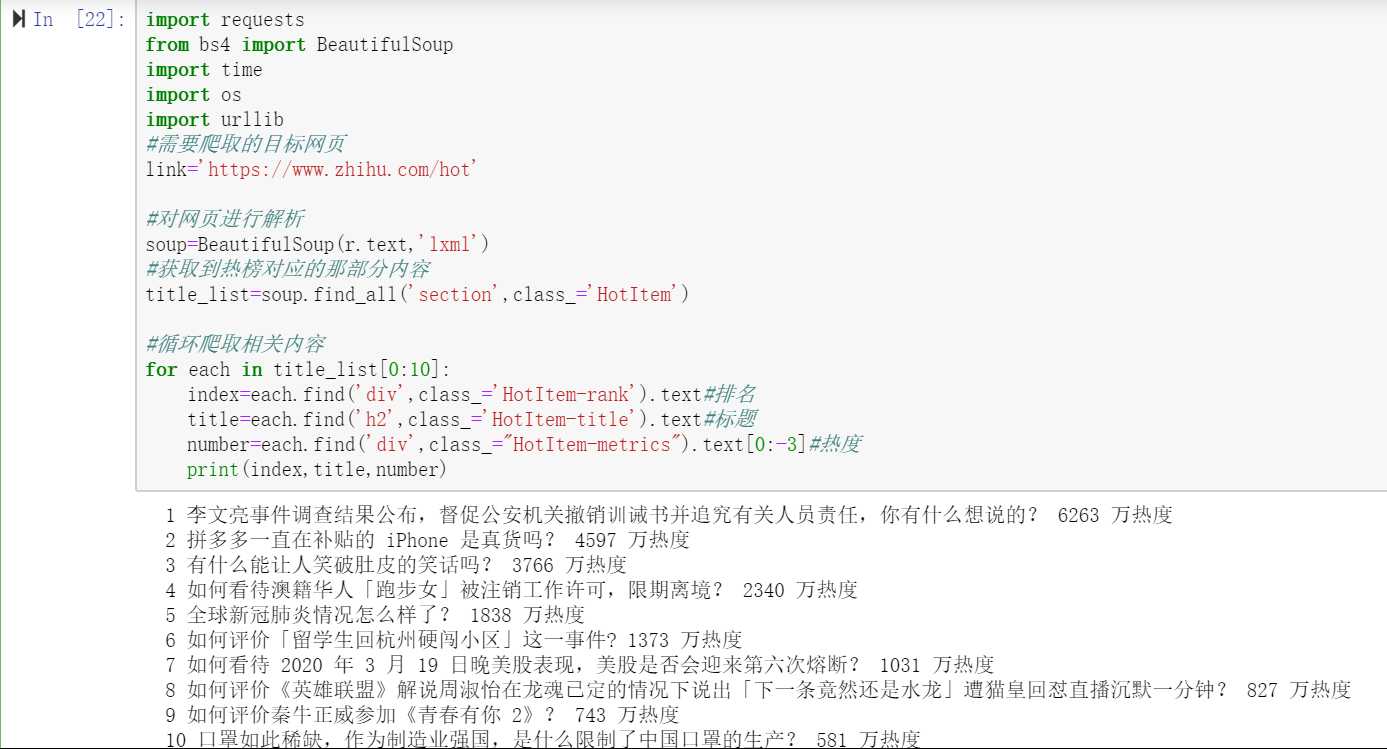
import requests
from bs4 import BeautifulSoup
import time
import os
import urllib
#需要爬取的目标网页
link=‘https://www.zhihu.com/hot‘
#对网页进行解析
soup=BeautifulSoup(r.text,‘lxml‘)
#获取到热榜对应的那部分内容
title_list=soup.find_all(‘section‘,class_=‘HotItem‘)
#循环爬取相关内容
for each in title_list[0:10]:
index=each.find(‘div‘,class_=‘HotItem-rank‘).text#排名
title=each.find(‘h2‘,class_=‘HotItem-title‘).text#标题
number=each.find(‘div‘,class_="HotItem-metrics").text[0:-3]#热度
print(index,title,number)
标签:each urllib 循环 ima 爬取 目标 png from beautiful
原文地址:https://www.cnblogs.com/c---y/p/12529865.html