标签:*** profile 生效 data- 通信 inf 登录 source head
***对于大数据这块相信大家对linux有一定的认识,所有对创建虚拟机那块就不给予详细的说明了。
1.系统环境
平台:VMware Workstation pro
系统:centos 7
Hadoop版本: Apache Hadoop 3.0.0
本次实验是搭建一台master和两台node节点。因为我们主要的目的是想让大家了解一下Hadoop伪分布式的搭建流程,如果说大家的电脑小于8G的话,那就每台节点就大概开个1.5G左右,也是为了大家有一个好的体验。
[root@master ~]# hostnamectl set-hostname master
[root@master ~]# vi /etc/sysconfig/selinux
修改 SELINUX=disabled
[root@master ~]# setenforce 0
[root@master ~]# getenforce
[root@master ~]# vi /etc/hosts
添加:
192.168.200.111 master
192.168.200.112 node1
192.168.200.113 node2
**每台节点都要配置
配置的目的是master节点到另外两个node节点通信、传输无障碍。
[root@master ~]# ssh-keygen -t rsa(一路按回车完成密钥生成)
[root@master ~]#cd .ssh/
[root@master .ssh]# ls
id_rsa id_rsa.pub
(进行公钥复制)
[root@master .ssh]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
(修改authorized_keys文件的权限)
[root@master .ssh]# chmod 600 ~/.ssh/authorized_keys
[root@master .ssh]# ls -l
total 16
-rw-------. 1 root root 393 Mar 15 10:19 authorized_keys
-rw-------. 1 root root 1675 Mar 15 10:18 id_rsa
-rw-r--r--. 1 root root 393 Mar 15 10:18 id_rsa.pub
(将专用密钥添加到 ssh-agent 的高速缓存中)
[root@master .ssh]# ssh-agent bash
[root@master .ssh]# ssh-add ~/.ssh/id_rsa
(将authorized_keys复制到node1和node2节点的根目录下)
[root@master .ssh]# scp ~/.ssh/authorized_keys zkpk@node1:~/
[root@master .ssh]# scp ~/.ssh/authorized_keys zkpk@node2:~/
在node1节点进行操作
[root@node1 ~]# ssh-keygen -t rsa
[root@node1 ~]# mv authorized_keys ~/.ssh/
node2节点和node1节点的操作一样的
在master节点验证免密是否成功
[root@master .ssh]# ssh node1
Last login: Thu Mar 19 06:56:50 2020 from 192.168.200.1
[root@node1 ~]#
[root@master .ssh]# ssh node2
Last login: Thu Mar 19 06:56:58 2020 from 192.168.200.1
[root@node2 ~]#
如果和什么的返回的结果成功了,否则就仔细检查一下上述步骤。
?
?
1. 将JDK压缩包通过secureFX传到master节点的opt目录下。
2. 选择一个路径创建一个bigdata文件夹,笔者选择的是opt下面。
[root@master opt]# ls
bigdata centos hadoop-3.0.0.tar.gz jdk-8u161-linux-x64.tar.gz
解压JDK压缩包
[root@master opt]# tar -zxvf jdk-8u161-linux-x64.tar.gz
[root@master opt]# mv jdk1.8.0_161 bigdata/(把解压得到的jdk1.8.0_161移动到bigdata里面)
[root@master bigdata]# ls
jdk1.8.0_161
(配置Java环境变量)
[root@master bigdata]# vi /etc/profile
添加:
export JAVA_HOME="/opt/bigdata/jdk1.8.0_161" (这里填的是你的jdk1.8.0_161的绝对路径)
export PATH=$JAVA_HOME/bin:$PATH
使环境变量生效并且验证
[root@master bigdata]# source /etc/profile
[root@master bigdata]# java -version
java version "1.8.0_161"
Java(TM) SE Runtime Environment (build 1.8.0_161-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.161-b12, mixed mode)
3.拷贝master节点的jdk到node1和node2上面,并且按相同的方式配置Java环境变量
[root@master /]# scp -r /opt/bigdata/ node1:/opt/
[root@master /]# scp -r /opt/bigdata/ node2:/opt/
1.通过secureFX把Hadoop压缩包上传至/opt/bigdata目录,并且解压压缩包。
[root@master /]# cd /opt/
[root@master opt]# ls
bigdata hadoop-3.0.0.tar.gz jdk-8u161-linux-x64.tar.gz
[root@master opt]# tar -zxvf hadoop-3.0.0.tar.gz
[root@master opt]# mv hadoop-3.0.0 bigdata 把解压得到的hadoop-3.0.0 目录拷贝到bigdata目录里
[root@master opt]# cd bigdata
[root@master bigdata]#ls
hadoop-3.0.0 jdk1.8.0_161
2.配置Hadoop的环境变量
[root@master ~]# vi /etc/profile
添加:
export HADOOP_HOME=/opt/bigdata/hadoop-3.0.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
激活环境变量
[root@master bigdata]# source /etc/profile
验证配置是否成功
[root@master bigdata]# hadoop version
Hadoop 3.0.0
Source code repository https://git-wip-us.apache.org/repos/asf/hadoop.git -r c25427ceca461ee979d30edd7a4b0f50718e6533
Compiled by andrew on 2017-12-08T19:16Z
Compiled with protoc 2.5.0
From source with checksum 397832cb5529187dc8cd74ad54ff22
This command was run using /opt/bigdata/hadoop-3.0.0/share/hadoop/common/hadoop-common-3.0.0.jar
一共需要修改五个文件。
1.在/opt/bigdata/hadoop-3.0.0/etc/hadoop/路径下,找到hadoop-env.sh
[root@master hadoop]# vi hadoop-env.sh
配置: export JAVA_HOME=/opt/bigdata/jdk1.8.0_161 这里的JAVA_HOME必须配置绝对路径
?
2.[root@master hadoop]# vi core-site.xml
添加:
configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.temp.dir</name>
<value>/opt/bigdata/hadoop-3.0.0/tmp</value>
</property>
</configuration>
?
3.[root@master hadoop]# vi hdfs-site.xml
添加:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/bigdata/hadoop-3.0.0/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/bigdata/hadoop-3.0.0/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:9001</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
</configuration>
?
4.[root@master hadoop]# vi mapred-site.xml
添加:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property> <name>mapred.job.tracker.http.address</name>
<value>0.0.0.0:50030</value>
</property>
<property> <name>mapred.task.tracker.http.address</name>
<value>0.0.0.0:50060</value>
</property>
<property>
<name>mapreduce.applicaton.classpath</name>
<value>
/opt/bigdata/hadoop-3.0.0/etc/hadoop,
/opt/bigdata/hadoop-3.0.0/share/hadoop/common/*,
/opt/bigdata/hadoop-3.0.0/share/hadoop/common/lib/*,
/opt/bigdata/hadoop-3.0.0/share/hadoop/hdfs/*,
/opt/bigdata/hadoop-3.0.0/share/hadoop/hdfs/lib/*
/opt/bigdata/hadoop-3.0.0/share/hadoop/mapreduce/*,
/opt/bigdata/hadoop-3.0.0/share/hadoop/yarn/*,
/opt/bigdata/hadoop-3.0.0/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
?
5.[root@master hadoop]# vi yarn-site.xml
添加:
<configuration>
<!-- Site specific YARN configuration properties -->
<property> <name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property> <name>yarn.resourcemanager.webapp.address</name>
<value>master:8099</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/opt/bigdata/hadoop-3.0.0/etc/hadoop:/opt/bigdata/hadoop-3.0.0/share/hadoop/common/lib/*:/opt/bigdata/hadoop-3.0.0/share/hadoop/common/*:/opt/bigdata/hadoop-3.0.0/share/hadoop/hdfs:/opt/bigdata/hadoop-3.0.0/share/hadoop/hdfs/lib/*:/opt/bigdata/hadoop-3.0.0/share/hadoop/hdfs/*:/opt/bigdata/hadoop-3.0.0/share/hadoop/mapreduce/*:/opt/bigdata/hadoop-3.0.0/share/hadoop/yarn:/opt/bigdata/hadoop-3.0.0/share/hadoop/yarn/lib/*:/opt/bigdata/hadoop-3.0.0/share/hadoop/yarn/*
</value>
</property>
</configuration>
?
6.配置workers
root@master hadoop]# vi workers
添加:
node1
node2
?
7.将配置好的hadoop复制到node1和node2
[root@master bigdata]# scp -r hadoop-3.0.0/ node1:/opt/bigdata
[root@master bigdata]# scp -r hadoop-3.0.0/ node2:/opt/bigdata
1.在/opt/bigdata/hadoop-3.0.0/sbin路径下找到start-dfs.sh和stop-dfs.sh
[root@master sbin]# vi start-dfs.sh
添加:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
两个脚本文件添加的内容一样
2.然后找到start-yarn.sh和stop-yarn.sh
添加:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
1.关闭防火墙
[root@master ~]# systemctl stop firewalld.service
[root@master ~]# systemctl disable firewalld.service
2.首次启动需要格式化命名节点
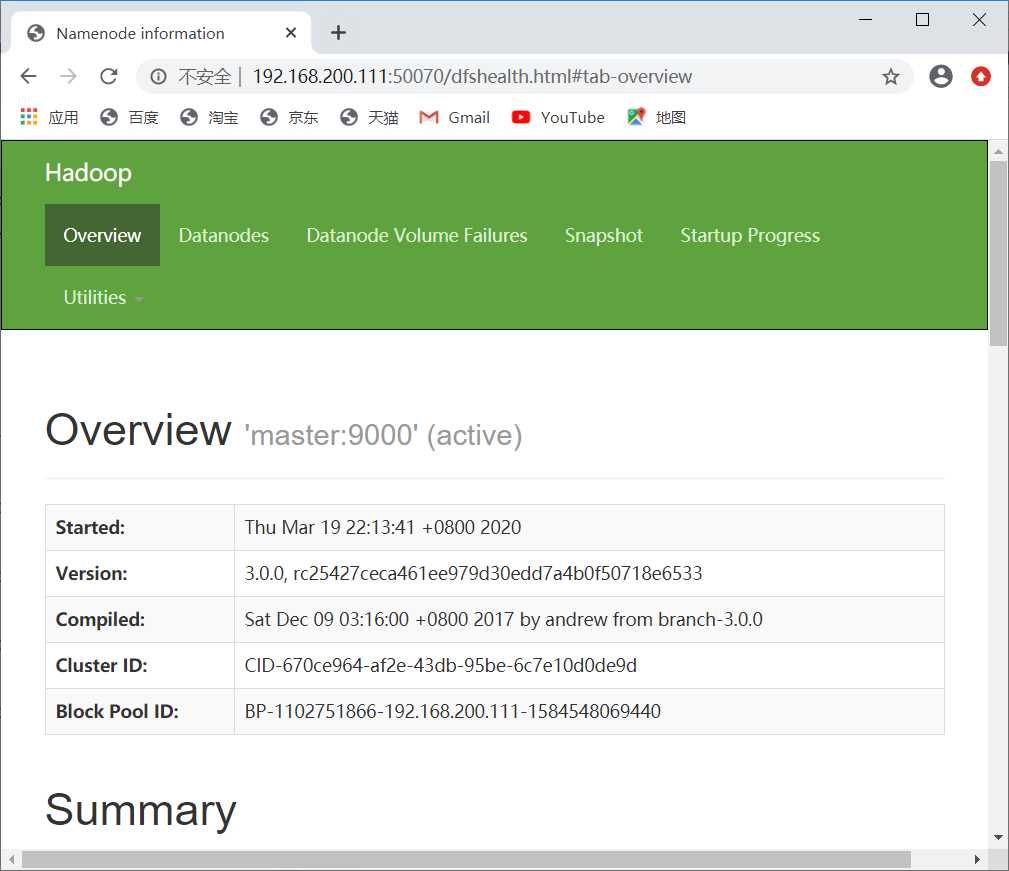
[root@master ~]# hadoop namenode -format
3.启动
[root@master ~]# start-all.sh
Starting namenodes on [master]
Last login: Thu Mar 19 10:06:13 EDT 2020 from 192.168.200.1 on pts/2
Starting datanodes
Last login: Thu Mar 19 10:13:28 EDT 2020 on pts/2
Starting secondary namenodes [node1]
Last login: Thu Mar 19 10:13:31 EDT 2020 on pts/2
Starting resourcemanager
Last login: Thu Mar 19 10:13:46 EDT 2020 on pts/2
Starting nodemanagers
Last login: Thu Mar 19 10:13:56 EDT 2020 on pts/2
4.检验在各个节点jps下的进程
[root@master ~]# jps
2753 NameNode
3505 Jps
3155 ResourceManager
[root@node1 ~]# jps
2658 Jps
2500 DataNode
2617 NodeManager
2557 SecondaryNameNode
[root@node2 ~]# jps
2741 Jps
2569 NodeManager
2509 DataNode

标签:*** profile 生效 data- 通信 inf 登录 source head
原文地址:https://www.cnblogs.com/lfz0/p/12530817.html