标签:info 爬虫 strip 内容 col 爬取 end from baidu
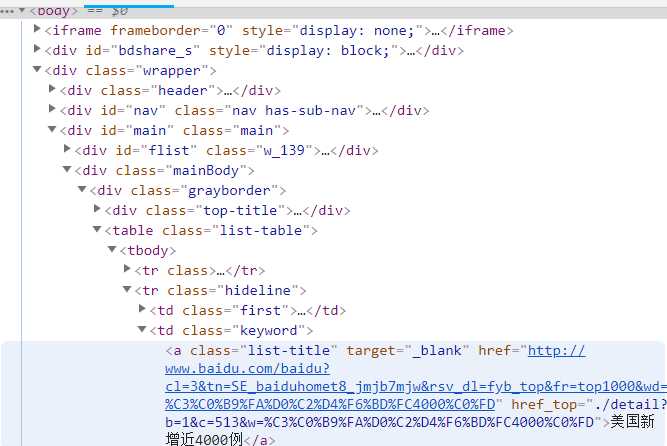
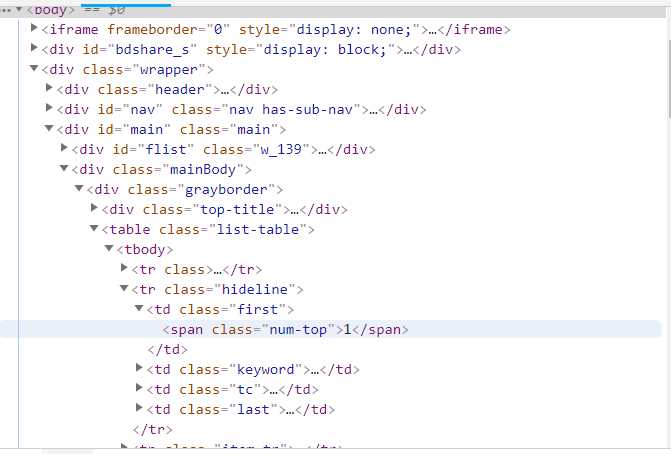
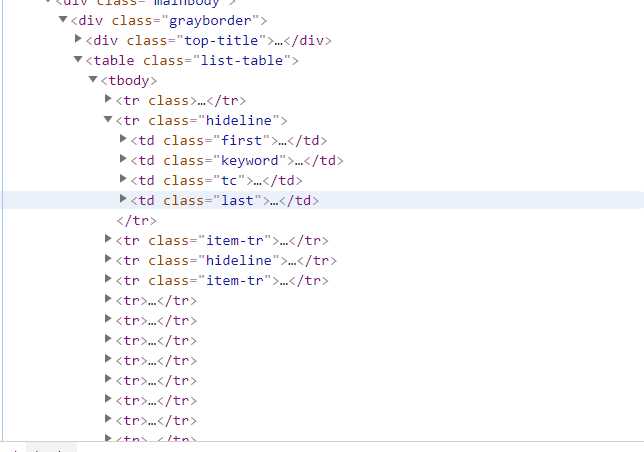
1 import requests 2 from bs4 import BeautifulSoup 3 import pandas as pd 4 #获取html网页 5 url = ‘http://top.baidu.com/buzz.php?p=top10&tdsourcetag=s_pctim_aiomsg&qq-pf-to=pcqq.c2c?‘ 6 kv = {‘user-agent‘: ‘Mozilla/5.0‘}#伪装爬虫 7 r = requests.get(url,timeout = 30,headers=kv) 8 r.raise_for_status() 9 r.encoding = r.apparent_encoding 10 r.text#获取源代码 11 html=r.text 12 soup=BeautifulSoup(html,‘html.parser‘) 13 #解析网页,提取内容 14 a = []#创建空列表 15 b = [] 16 for x in soup.find_all(class_="list-title")[:10]: 17 a.append(x.get_text().strip()) 18 for y in soup.find_all(class_="icon-rise")[:10]: 19 b.append(y.get_text().strip()) 20 text =[a,b] 21 print(text) 22 c=pd.DataFrame(text,index=["标题","热度"]) 23 print(c.T)
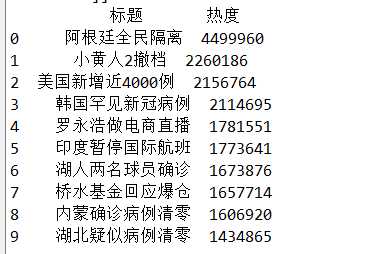
标签:info 爬虫 strip 内容 col 爬取 end from baidu
原文地址:https://www.cnblogs.com/yyy6265/p/12534257.html