标签:调整 图像 输出 结果 摘要 测试数据 word2vec clu 标签
CVPR2020论文解析:视频分类Video Classification
Rethinking Zero-shot Video Classification: End-to-end Training for Realistic Applications

论文链接:https://arxiv.org/pdf/2003.01455.pdf
摘要
深度学习(deep learning,DL)是在大型数据集上进行训练的,它可以将视频准确地分为数百个不同的类。然而,视频数据的注释是昂贵的。Zero-shot学习(ZSL)提出了一种解决方案。ZSL只训练一次模型,并将其推广到类不在训练数据集中的新任务。提出了第一种用于视频分类的ZSL端到端算法。训练程序基于最新视频分类文献的见解,并使用可训练的3D CNN来学习视觉特征。这与以前的视频ZSL方法不同,后者使用预先训练的特征抽取器。扩展了当前的基准测试范式:以前的技术旨在使测试任务在训练时未知,但没有达到这个目标。本文鼓励跨训练和测试数据的域转移,并且不允许将ZSL模型裁剪为特定的测试数据集。本文的性能远远超过了最先进的技术。
1. Introduction
本文的贡献涉及ZSL视频分类的多个方面:
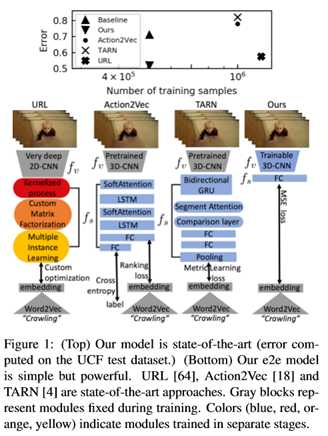
新的建模方法:我们提出了第一个用于Zero-shot识别的e2e训练模型。训练程序的灵感来自现代监督视频分类实践。图1表明,这个方法简单,但优于以前的工作。此外,还设计了一种新的简单的预训练技术,以ZSL场景为目标进行视频识别。
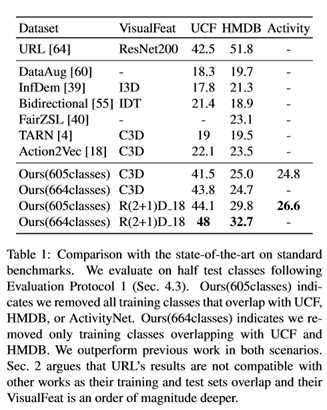
评估协议:我们提出了一个新的ZSL训练和评估协议,实施一个现实的ZSL设置。扩展Roitberg等人[40]的工作。在多个测试数据集上测试一个单一训练模型,其中训练和测试类集是不相交的。此外,本文认为训练和测试领域不应该是相同的。
深入分析:本文对e2e模型和预训练基线进行深入分析。在一系列引导性实验中,探索了良好ZSL数据集的特征。
2. Related work
本文关注的是在训练时测试数据完全未知的归纳ZSL。有大量关于跨导ZSL的文献[1,33,54,55,59,58,60],其中测试图像或视频在训练期间是可用的,但测试标签不是。在这项工作中暂不讨论反导方法。
Video classi?cation:
在这项工作中,我们将最先进的视频分类的训练时间采样原理应用到ZSL设置中。这使得我们能够训练视觉嵌入e2e。因此,与之前的工作相比,整体架构和推理过程非常简单,并且结果是最先进的-如图1所示。
Zero shot video classi?cation:
Zero shot视频分类的常见做法是首先使用预训练网络(如C3D[51]或ResNet[21])从视频帧中提取视觉特征,然后训练将视觉嵌入映射到语义嵌入空间的时间模型[4、13、14、15、16、18、35、61、64]。类名语义嵌入的良好泛化意味着该模型可以在可能的情况下应用于新的视频训练数据中不存在输出类。推理减少到查找嵌入为模型输出最近邻的测试类。Word2Vec[32]通常用于生成基本真值词嵌入。另一种方法是使用手工构建的类属性[23]。本文决定不采用手动方法,因为在一般情况下很难应用。
最近两种有效的方法,Hahn等人 [18] 以及Bishay等人 [4] ,从每个视频16帧的52个片段中提取C3D特征。然后训练一个递归神经网络[10,22],将结果编码为一个向量。最后,一个完全连接的层将编码的视频映射到Word2Vec嵌入中。图1示出了这种方法。[18]和[4]将可用的数据集类分成两组后,使用相同的数据集进行训练和测试。使用预先训练好的深度网络是很方便的,因为预先提取的视觉特征很容易在GPU内存中找到,即使对于大量的视频帧也是如此。替代方法使用生成模型来补偿语义和视觉分布之间的差距[33,62]。不幸的是,性能受到无法精确调整视觉嵌入的限制。本文展示了精确的调整对于在数据集中进行概括是至关重要的。本文的工作与朱等人[64]类似。在这两种方法中,都学习了一种通用的动作表示法,它可以在数据集之间进行泛化。然而,他们提出的模型并没有充分利用3D CNN的潜力。相反,他们利用了非常深的ResNet200[21],在ImageNet[9,43]上预先训练,后者不能利用时间信息。正如Roitberg等人[40]指出的那样,之前的工作是在和目标数据集重叠的操作上训练模型,违反了ZSL假设。例如,Zhu等人 [64]在完整的活动网络[11]数据集上训练。这使得他们的结果很难与本文的相比较。根据本文对ZSL的定义。在与测试数据集重叠的训练数据集中有23个类。所有其他方法的情况都不同程度地相似。

3. Zero-shot action classi?cation
首先在视频分类的背景下仔细定义ZSL。这将使我们不仅可以提出一种新的ZSL算法,而且还可以提出一个清晰的评估协议,希望能将未来的研究引向实用的ZSL解决方案。
3.1. Problemsetting
形式上,给定一个视频x,我们推导出相应的语义嵌入z=g(x),并在测试类的嵌入集合中将x分类为z的最近邻。然后,经过训练的分类模型M(·)输出

3.2. End-to-end training
本文建议同时优化fv和fs。这样的e2e培训提供了多种优势: 一。1)由于fv提供了一个复杂的计算引擎,fs可以是一个简单的线性层(见图1)。 2)可以使用标准的3D CNNs来实现完整的模型。
3)在分类任务中预先训练视觉嵌入是不必要的。
由于GPU内存限制,使用完整视频进行端到端优化是不可行的。本文的实现基于标准的视频分类方法,即使在训练过程中只使用一个小片段,这些方法也是有效的,如第2节中详细讨论的。
形式上,在给定训练视频/类对(x,c)∈Ds的情况下,我们在随机时间t≤(len(x)–16)提取16帧的片段xt。通过最小化损耗优化网络
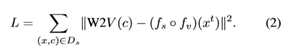
3.3. Towards realistic ZSL
为了确保我们的ZSL设置是现实的,我们扩展了[40]中仔细分离训练和测试数据的方法。这在实践中很难实现,而且大多数以前的工作都没有尝试过。我们希望我们对训练和评估协议的清晰表述将使未来的研究人员更容易理解其模型在真实ZSL场景中的性能。

非重叠训练和测试分类:
本文的第一个目标是确保Ds∪Dp和Dt有“非重叠分类”。简单的解决方案-删除 来自目标类的源类名称或相反的源类名称不起作用,因为两个名称稍有不同的类可以很容易地引用同一个概念,如图3所示。类名之间需要一个距离。有了这样的标准, 就可以确保训练类和测试类不太相似。形式上,设d:C→C表示所有可能类名C的空间上的距离度量,并设τ∈R表示相似阈值。在以下情况下,视频分类任务完全遵守zero-shot约束:
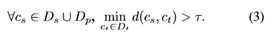
一种直接的定义方法是使用类名的语义嵌入。我们将两个类之间的距离定义为
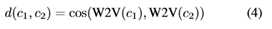
其中cos表示余弦距离。这与我们在等式1中使用的ZSL设置中的余弦距离一致。图2显示了在使用上述过程从与测试数据重叠的动力学类中移除后的训练类和测试类的嵌入。图3显示了本文的数据集中训练类和测试类之间的距离分布。距离非常接近0和大于0.1之间有一个悬崖。在我们的实验中,我们使用τ=0.05作为一个自然的、无偏的阈值。
不同的培训和测试视频域:
本文认为Ds∪Dp和Dt的视频域应该不同。在以前的工作中,标准的评估协议是使用一个数据集进行训练和测试,使用10个随机分割。这并不能解释真实场景中由于数据压缩、摄像机伪影等而发生的域转移。因此,理想情况下,ZSL训练和测试数据集应该具有不相交的视频源。
多个测试数据集:
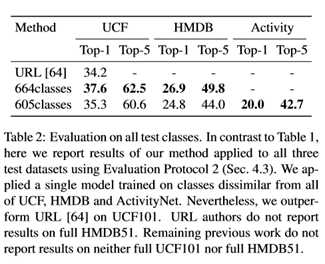
一个ZSL模型应该在多个测试数据集上运行良好。如上所述,以前的工作为每个可用的数据集(通常是UCF和HMDB)重新训练和测试。在本文的实验中,在动力学数据集[25]上只进行一次训练,在所有UCF[50]、HMDB[28]和ActivityNet[11]上进行测试。
3.4. Easy pretraining for video ZSL
在真实场景中,模型只需训练一次,然后部署到各种不可见的测试数据集上。一个庞大而多样的训练数据集对于获得良好的性能至关重要。理想情况下,训练数据集将根据推理的一般领域进行定制,例如,部署在多个未知位置的强ZSL监视模型将需要一个大型监视和动作识别数据集。然而,获取和标记领域特定的视频数据集是非常昂贵的。另一方面,注释图像的速度要快得多。
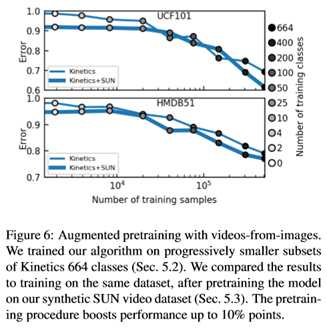
因此,设计了一个简单的数据集增强方案,从静止图像中生成合成训练视频。Sec. 5表明,使用此数据集对模型进行预训练可以提高性能,特别是在可用训练数据较少的情况下。
使用Ken Burns效果将图像转换为视频:一系列在图像周围移动的作物模拟类似视频的运动。Sec. 4.1提供了更多细节。实验集中在动作识别领域。在动作识别(以及许多其他分类任务)中,视频的位置和景物对动作类别具有很强的预测性。因此,选择了标准场景识别数据集SUN[57]。图2显示了场景数据集类名的完整类嵌入。
4. Test Results
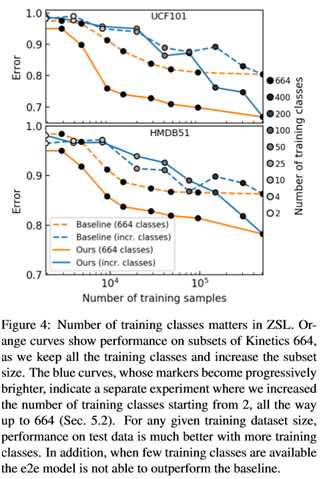
为了得到图4,我们按类别对动力学664进行了亚采样。我们首先随机选取了2个动力学664类,并仅在这些类上训练算法。我们使用4、10、25、50、100、200、400和所有664个类重复了这个过程。当然,类越少,训练集包含的数据点就越少。这一结果在图4中与上面描述的程序进行了比较,我们随机删除了动力学数据点,与它们的类别无关。
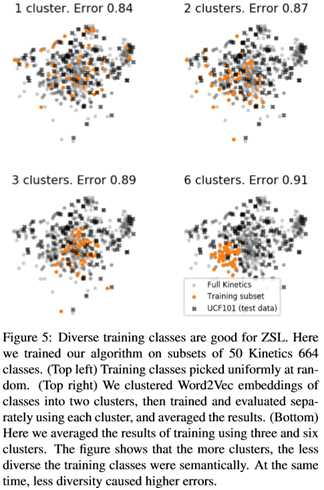
在图5中,我们通过四种方式选择了50个训练类:(左上角)我们从整个动力学664数据集中随机选择了50个类,在这些类上训练算法,并在测试集上运行推理。我们重复这个过程十次,平均推断误差。(右上)我们在Word2Vec嵌入空间中将664个类分为2个类,并在其中一个类中随机选择50个类,进行训练和推理。然后我们重复这个过程十次,平均结果。
5. Conclusion
本文遵循最近视频分类文献中的实践,为视频识别ZSL培训第一个e2e系统。本文的评估方案比现有的工作更严格,测量更现实的零炮分类精度。即使在这种更为严格的协议下,本文的方法也优于以前的工作,后者的性能是通过训练和测试集重叠和共享域来衡量的。通过一系列有针对性的实验,发现一个好的ZSL数据集应该有许多不同的类。在这个观点的指导下,制定了一个简单的预训练技术,以提高ZSL的性能。模型易于理解和扩展。训练和评估方案很容易与其他方法一起使用。
CVPR2020论文解析:视频分类Video Classification
标签:调整 图像 输出 结果 摘要 测试数据 word2vec clu 标签
原文地址:https://www.cnblogs.com/wujianming-110117/p/12537527.html