标签:header soup head tle requests parse ext int res
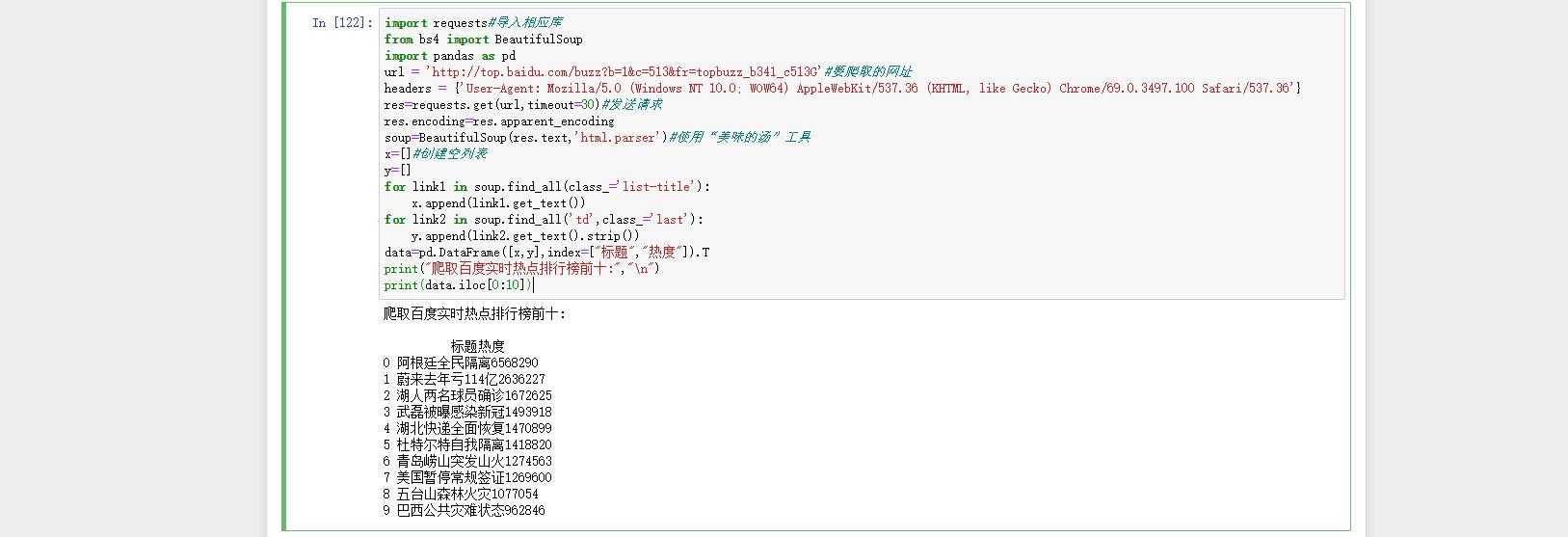
import requests#导入相应库
from bs4 import BeautifulSoup
import pandas as pd
url = ‘http://top.baidu.com/buzz?b=1&c=513&fr=topbuzz_b341_c513‘#要爬取的网址
headers = {‘User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36‘}
res=requests.get(url,timeout=30)#发送请求
res.encoding=res.apparent_encoding
soup=BeautifulSoup(res.text,‘html.parser‘)#使用“美味的汤”工具
x=[]#创建空列表
y=[]
for link1 in soup.find_all(class_=‘list-title‘):
x.append(link1.get_text())
for link2 in soup.find_all(‘td‘,class_=‘last‘):
y.append(link2.get_text().strip())
data=pd.DataFrame([x,y],index=["标题","热度"]).T
print("爬取百度实时热点排行榜前十:","\n")
print(data.iloc[0:10])
1.打开网站网址:http://top.baidu.com/buzz?b=1&c=513&fr=topbuzz_b341_c513
2.导入相应爬虫工具。
3.按下F12获得相应源代码
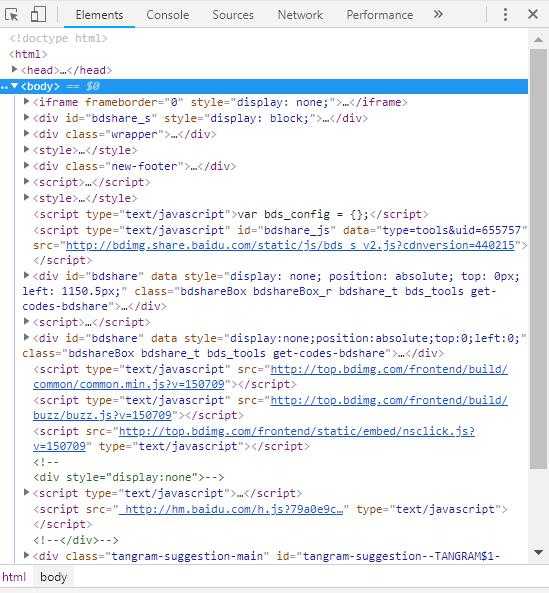
4.找到相应的数据进行爬取。
5.得出结果

标签:header soup head tle requests parse ext int res
原文地址:https://www.cnblogs.com/abc2920736782/p/12539146.html