标签:新闻 new status 抓取 lte 完整 网页 com author
首先要获取网页的代码,先将其装成一个函数
def getHTMLText(url): try: r = requests.get(url, timeout = 30) r.raise_for_status() #r.encoding = ‘utf-8‘ return r.text except: return ""
在chrome浏览器下,直接进去新闻之后,右键题目检查就可以定位到题目所在的html代码,如下图
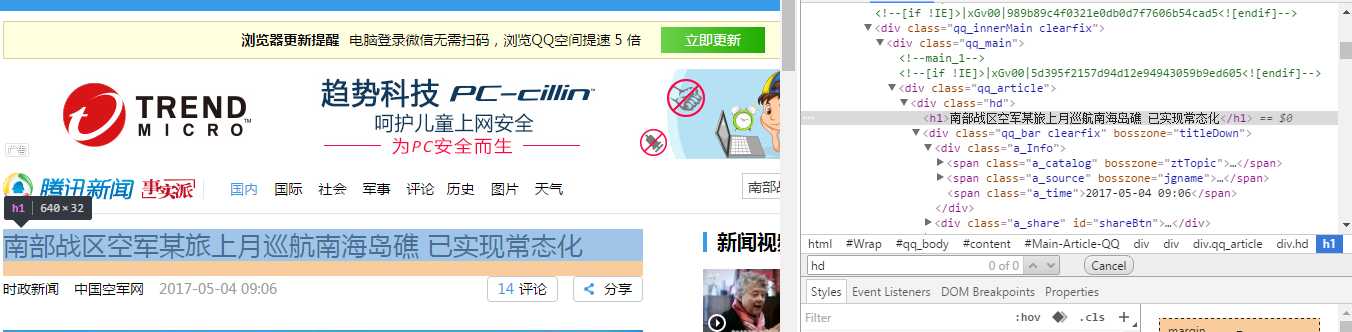
然后会看到<h1>标签内,它的上一级标签是div,并且class="hd",BeautifulSoup提供了一个CSS选择器,直接调用select方法即可
所以代码可以写成
def getContent(url): html = getHTMLText(url) # print(html) soup = BeautifulSoup(html, "html.parser") title = soup.select("div.hd > h1") print(title[0].get_text()) time = soup.select("div.a_Info > span.a_time") print(time[0].string) author = soup.select("div.qq_articleFt > div.qq_toolWrap > div.qq_editor") print(author[0].get_text()) paras = soup.select("div.Cnt-Main-Article-QQ > p.text") for para in paras: if len(para) > 0: print(para.get_text()) print()
完整源代码
#此代码主要是从给定腾讯新闻网页中爬取新闻的题目,时间,正文,作者 import requests from bs4 import BeautifulSoup def getHTMLText(url): try: r = requests.get(url, timeout = 30) r.raise_for_status() #r.encoding = ‘utf-8‘ return r.text except: return "" def getContent(url): html = getHTMLText(url) # print(html) soup = BeautifulSoup(html, "html.parser") title = soup.select("div.hd > h1") print(title[0].get_text()) time = soup.select("div.a_Info > span.a_time") print(time[0].string) author = soup.select("div.qq_articleFt > div.qq_toolWrap > div.qq_editor") print(author[0].get_text()) paras = soup.select("div.Cnt-Main-Article-QQ > p.text") for para in paras: if len(para) > 0: print(para.get_text()) print() #写入文件 fo = open("text.txt", "w+") fo.writelines(title[0].get_text() + "\n") fo.writelines(time[0].get_text() + "\n") for para in paras: if len(para) > 0: fo.writelines(para.get_text() + "\n\n") fo.writelines(author[0].get_text() + ‘\n‘) fo.close() #将爬取到的文章用字典格式来存 article = { ‘Title‘ : title[0].get_text(), ‘Time‘ : time[0].get_text(), ‘Paragraph‘ : paras, ‘Author‘ : author[0].get_text() } print(article) def main(): url = "http://news.qq.com/a/20170504/012032.htm" getContent(url); main()
标签:新闻 new status 抓取 lte 完整 网页 com author
原文地址:https://www.cnblogs.com/laiqunshi/p/12539102.html