标签:original 布布扣 air 实例 交换 label learning wap height
LTR 排序学习主要用于对召回结果的精排,主流使用基于pair(文档对标记)的 LambdaMART 算法,该算法由两部分组成:lambda + MART(GBDT:梯度提升树)。lambda是MART求解过程使用的梯度,其物理含义是一个待排序的文档下一次迭代应该排序的方向(向上或者向下)和强度。
pair 文档对标记法的思想主要体现在query对应文档的 lambda 梯度计算,文档计算得到的 lambda 值也是 GBDT 训练的 label,依次拟合 lambda 残差得到最优解。
LambdaMART 训练流程:
1. 计算 deltaNDCG 以及 lambda
2. 以 lambda 作为 label训练一棵 regression tree
3. 在 tree 的每个叶子节点通过预测的 regression lambda值还原得到gamma(最终得分)
4. 预测所有训练集合值(+ learningRate*gamma),重新排序打分(每个query新的base ndcg),回到步骤 1 训练新的树
5. 模型 NDCG 评价指标没有改进、或者达到收敛(迭代轮次、树的棵数)则结束训练
排序问题评价指标一般有NDCG、ERR、MAP、MRR,但是这些指标特点是不平滑、不连续,无法求梯度,因此无法直接用梯度下降法求解。
lambda 梯度:
1. 可以进行求导,所有能用梯度下降法的模型都可以使用该梯度。
2. 重新定义了梯度,赋予排序问题需要的梯度的物理意义;lambda(i)表达了doc(i)上升或者下降的强度:
* lambda >0,越大:趋于上升的方向,力度也越大(lambda 绝对值表示力度)
* lambda <0,越小:趋于下降的方向,力度也越大
step first 先计算 query 的 NDCG:
1. 根据初始 label 排序计算 query 的 dcg:
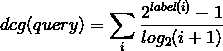 2. 根据理想的 label 排序(从大到小),重新计算 query的 idcg(即排序后的 dcg 值)
3. 计算query初始的 NDCG(original) = dcg/idcg
2. 根据理想的 label 排序(从大到小),重新计算 query的 idcg(即排序后的 dcg 值)
3. 计算query初始的 NDCG(original) = dcg/idcg
step second:
1. 计算 doc(i) 的与其他 doc(j) 交换位置的 deltaNDCG: deltaNDCG(i,j) = | NDCG(original) - NDCG(swap(i,j))| 2. 计算 lambda(i),涉及的计算公式:
: 该计算公式可以理解为所有正向lambda(i,j)与所有负向
lambda(i,j)之和
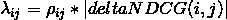
概率公式为逻辑回归函数,ρ可以理解为doci比docj差的概率:
![]()
lambda 计算实例: https://blog.csdn.net/u010035907/article/details/70739816
ps:训练过程中选取最小化平方误差和的特征分裂节点
标签:original 布布扣 air 实例 交换 label learning wap height
原文地址:https://www.cnblogs.com/fqr52/p/11612510.html