标签:插入 页码 有序 汇聚 完成后 进一步 并行 链接 查询
顾名思义,就是应用程序对数据的批量处理。
跑批有以下特性:
在开发中常见的跑批应用场景如下(以目前做的系统举例):
在跑批开发中有一些存有潜在隐患的处理方式需要指出来:
如下图,准备了200万的数据:
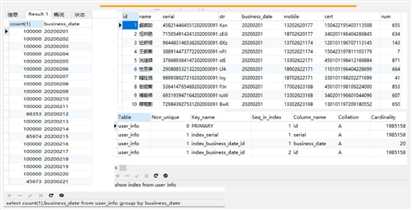
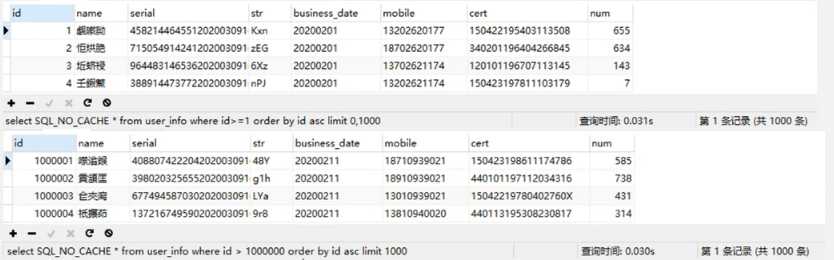
测试最简单的分片逻辑——limit的执行效率:
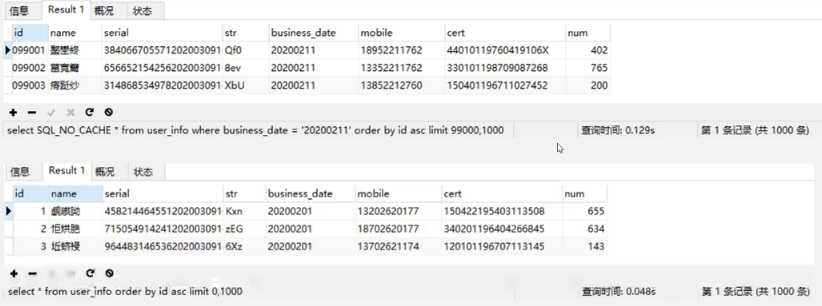


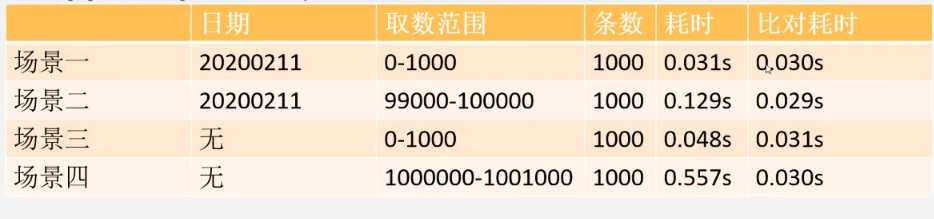
上面四种limit的耗时统计如下:
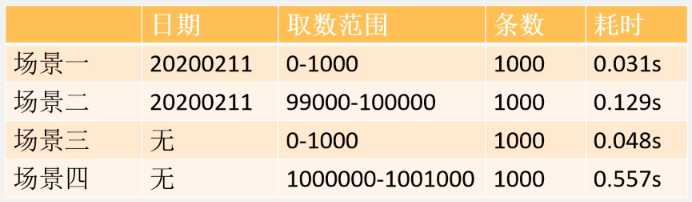
可以看出,随着起始记录的增加,查询时间也随着增大, 这说明分页语句limit跟起始页码是有很大关系的,所以limit 对记录很多的表并不适合直接使用。
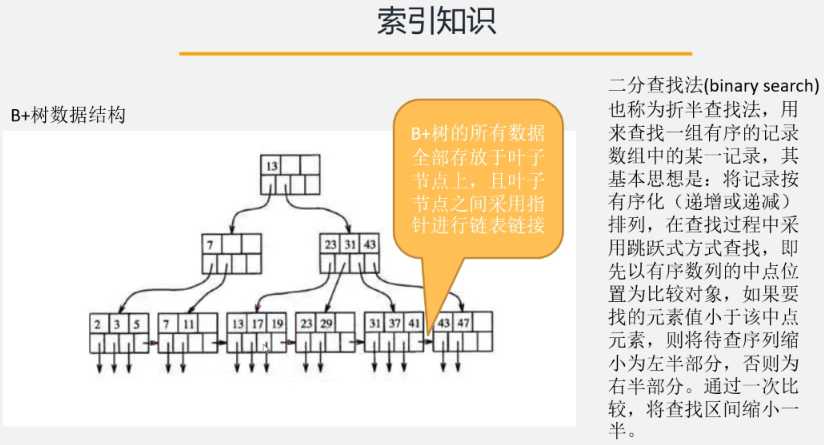
利用索引的排序特性与叶子节点链表链接特性以及快速定位数据所在位置的二分查找法,对分片进行优化。
下面是加条件查询:
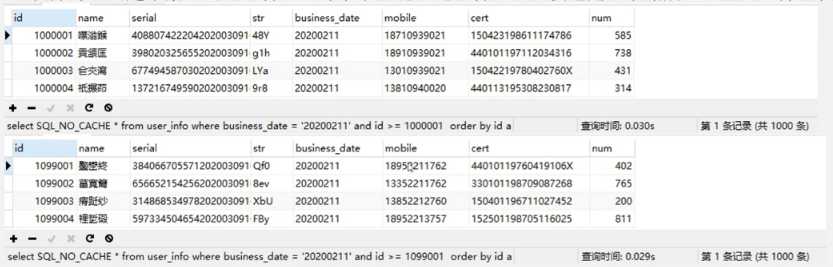
对全表查询,速度也有很大提升:
将两次查询进行比对:
很明显,当我们使用id进行范围查询的时候,查询效率趋于平稳且快速,那么只需要确定每一片需要使用的查询条件的id值与 business_date值,业务场景上一般按照业务日期进行跑批,日期是已知确定的,id可以通过lmit1000,1获取。
以此类推,10万数据按照1000条一片需要进行100次分片条件查询,预计平均耗时在3秒以内可以得到一组分片条件数据。

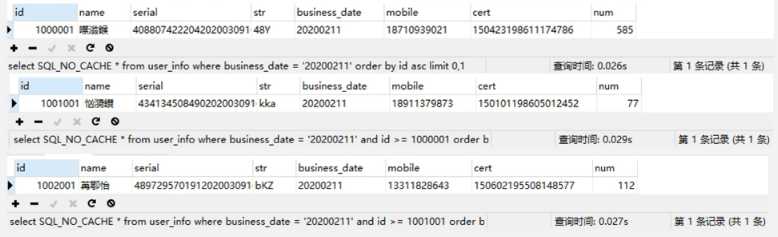
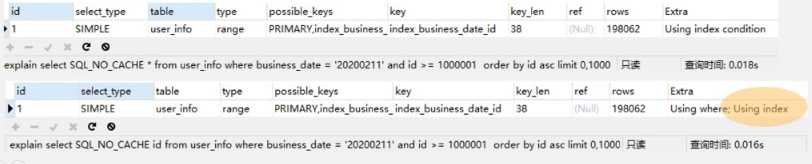
针对覆盖索引的知识,对分片SQL进一步优化,对于 business date与id本身已经是联合索引,而分片的条件只需要返回id。

如上,为了验证覆盖索引效果,对查询执行了N次,提取出来各自执行能达到的最短时间,最小值提升了2毫秒。
通过explain,仅查询id字段是用到了覆盖索引。
系统中的批量任务是基于开源项目xxl-job进行调度执行的,项目详见作者博客 许雪里 。
在该项目落地过程中,有些问题浮现:
所以基于上面的思路,为避免各个子系统对于分片存储和广播通知后多线程执行逻辑重复造轮子,对xxl-job进行了适配改造,具体改造点:
当业务设计到数据库操作时,相比较于单条的新增或更新,批量的执行效率更高,所以涉及到批量的业务,能够使用批量就尽量使用批量。
批量插入:
insert into table_name(column1,column2,column3) values (‘column11‘,‘column12‘,‘column13‘),(‘column21‘,‘column22‘,‘column23‘)···
批量更新:
update table_name set column_name = ‘column1‘ where column_name2 = ‘column2‘;update table_name set column_name = ‘column3‘ where column_name2 = ‘column4‘;···
需要在数据库连接上开启批量操作:rewriteBatchedStatements=true&allowMultiQueries=true
master.jdbc.url=jdbc:mysql://127.0.0.1:3306/batch_test?useUnicode=true&characterEncoding=utf8&rewriteBatchedStatements=true&allowMultiQueries=true

对文件进行分片,文件中有一个元素,天然是有序的:行号。且按照行进行分片能够保证一片内数据完整性。
可以使用Java IO提供的RandomAccessFile类来进行文件的解析,主要基于以下三个方法:

分片思路:
此外,Java NIO类SeekableByteChannel同样支持随机访问,只是没有整行读取功能,需要识别字节中是否有换行符,性能上强于RandomAccessFile。

优化思路:
标签:插入 页码 有序 汇聚 完成后 进一步 并行 链接 查询
原文地址:https://www.cnblogs.com/zjfjava/p/12538446.html