标签:默认 details java对象 batch 字节数组 broker nal software sdn
记录下和kafka相关的Message、日志文件、索引文件、consumer记录消费的offset相关内容,文中很多理解参考文末博文、书籍还有前辈。
kafka中的消息Message,在V1版本中是如下部分组成,主要关系key和value。
(1)key:当需要将消息写入到某个topic下的指定partition分区时,需要给定key的值。
(2)value:实际消息内容保存在这里。
(3)其他均是消息的元数据,一般不用关心,对用户来说是透明的。

为了保存这些消息数据,kafka使用了ByteBuffer来存储,它是紧凑型字节数组,相比使用java对象来保存消息数据到堆内存,它更加的节省空间,提高内存使用率。
查看一个topic分区目录下的内容,发现有log、index和timeindex三个文件,它有以下几个特点。
(1)log文件名是以文件中第一条message的offset来命名的,实际offset长度是64位,但是这里只使用了20位,应付生产是足够的。可以看出第一个log文件名是以0开头,而第二个log文件是4161281,说明第一log文件保存了offset从0到4161280的消息。
(2)一组index+log+timeindex文件的名字是一样的,并且log文件默认写满1G后,会进行log rolling形成一个新的组合来记录消息,这个是通过broker端log.segment.bytes=1073741824指定的,可以修改这个值进行调整。
(3)index和timeindex在刚使用时会分配10M的大小,当进行log rolling后,它会修剪为实际的大小,所以看到前几个索引文件的大小,只有几百K。
# 一个分区目录下文件内容,参考文末书籍杜撰,主要为了说明概念
[root@hadoop01 /home/software/kafka-2/kafka-logs/football-0]# ll -h
-rw-r--r--. 1 root root 514K Mar 20 16:04 00000000000000000000.index
-rw-r--r--. 1 root root 1.0G Mar 17 03:36 00000000000000000000.log
-rw-r--r--. 1 root root 240K Mar 20 16:04 00000000000000000000.timeindex
-rw-r--r--. 1 root root 512K Mar 20 16:04 00000000000004161281.index
-rw-r--r--. 1 root root 1.0G Mar 17 03:36 00000000000004161281.log
-rw-r--r--. 1 root root 177K Mar 20 16:04 00000000000004161281.timeindex
-rw-r--r--. 1 root root 10M Mar 20 16:04 00000000000008749921.index
-rw-r--r--. 1 root root 390M Mar 17 03:36 00000000000008749921.log
-rw-r--r--. 1 root root 10M Mar 20 16:04 00000000000008749921.timeindex如果想查看这些文件,可以使用kafka提供的shell来完成,几个关键信息如下:
(1)offset是逐渐增加的整数。
(2)position是相对外层batch的位置增量,可以理解为消息的字节偏移量。
(3)CreateTime:时间戳。
(4)magic:2代表这个消息类型是V2,如果是0则代表是V0类型,1代表V1类型。本机是V2类型的,不过也可以暂时按照上面的V1来参考理解,具体需要看文末书籍里的详细介绍。
(5)compresscodec:None说明没有指定压缩类型,kafka目前提供了4种可选择,0-None、1-GZIP、2-snappy、3-lz4。
(6)crc:对所有字段进行校验后的crc值。
# 查看并打印log文件内容
[root@hadoop01 /home/software/kafka-2/kafka-logs/football-0]# ../../bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000004.log --print-data-log
Dumping 00000000000000000004.log
Starting offset: 4
baseOffset: 4 lastOffset: 4 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 49 isTransactional: false position: 0 CreateTime: 1584368524633 isvalid: true size: 85 magic: 2 compresscodec: NONE crc: 3049289418
baseOffset: 5 lastOffset: 5 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 49 isTransactional: false position: 85 CreateTime: 1584368668414 isvalid: true size: 73 magic: 2 compresscodec: NONE crc: 2267711305
baseOffset: 6 lastOffset: 6 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 49 isTransactional: false position: 158 CreateTime: 1584368679882 isvalid: true size: 78 magic: 2 compresscodec: NONE crc: 789213838
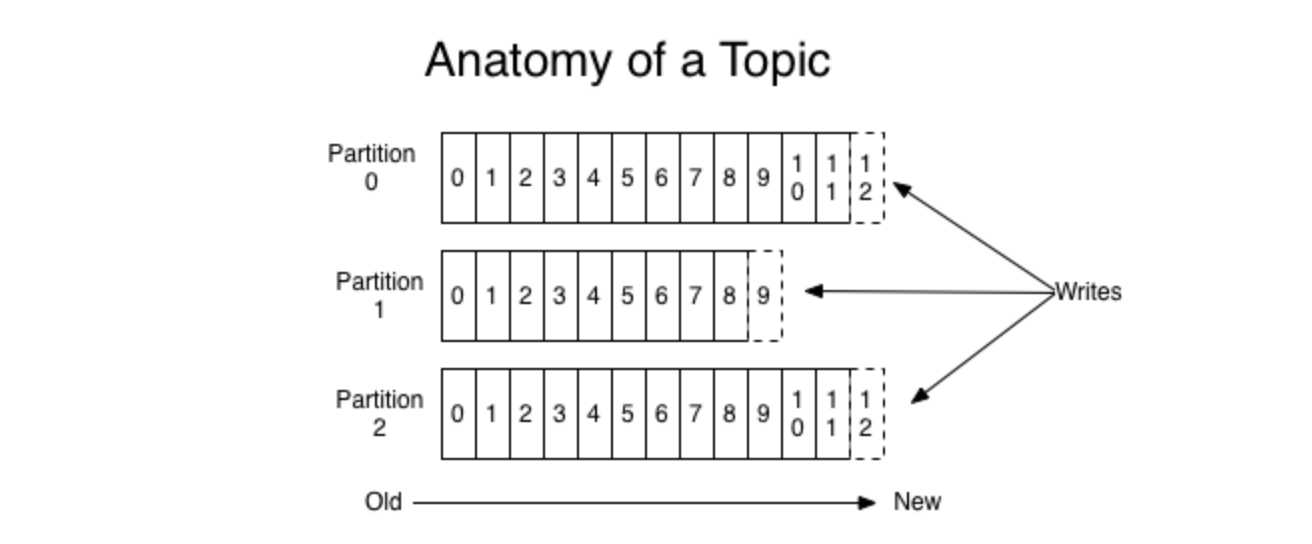
baseOffset: 7 lastOffset: 7 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 49 isTransactional: false position: 236 CreateTime: 1584368695371 isvalid: true size: 95 magic: 2 compresscodec: NONE crc: 703634716(1)消息内容,保存在log日志文件中,它是记录message的载体。消息会封装成Record的形式,append到log日志文件末尾,采用的是顺序写模式,参考官网图片,一个topic的不同分区,可以想成queue,都会顺序写入发送到它的消息。图中partition0中的0、1、2、3等数字就是一个分区中消息的offset,它是递增的数字。
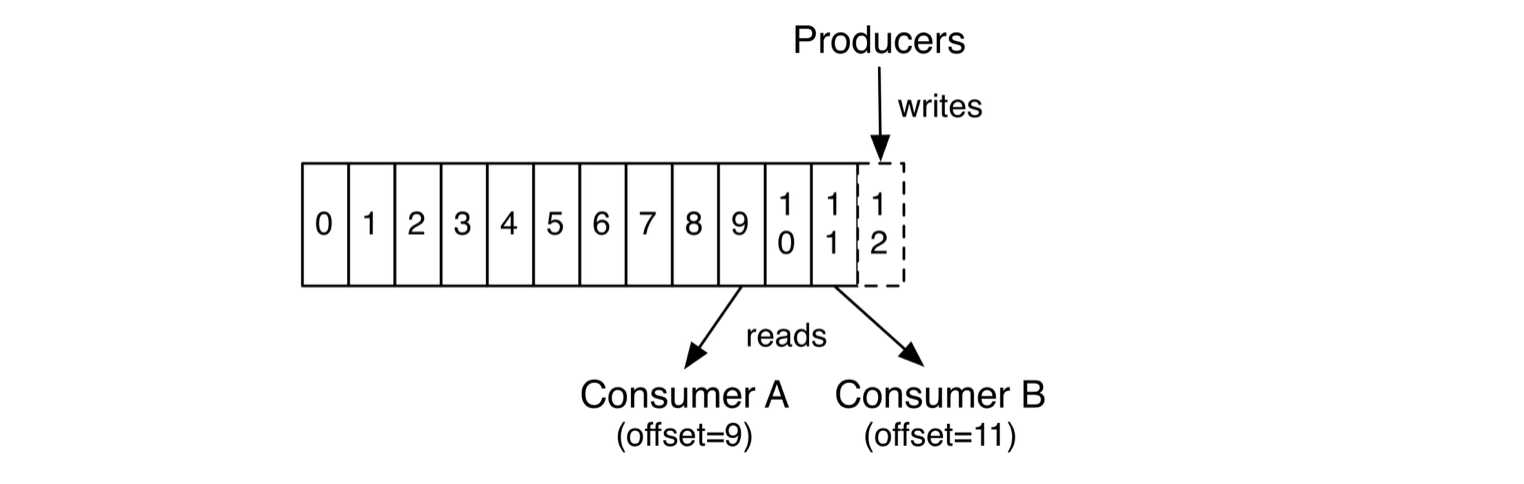
注意消费者也是有offset的,刚开始学的时候两者混淆了,消费者的offset指的是消费的位置,它是不断更新的数字,主要是为了下次继续消费定位用的。如官网中图片所示,消费者A消费的offset是9,消费者B消费的offset是11,不同的消费者offset是交给它们自己单独记录的。
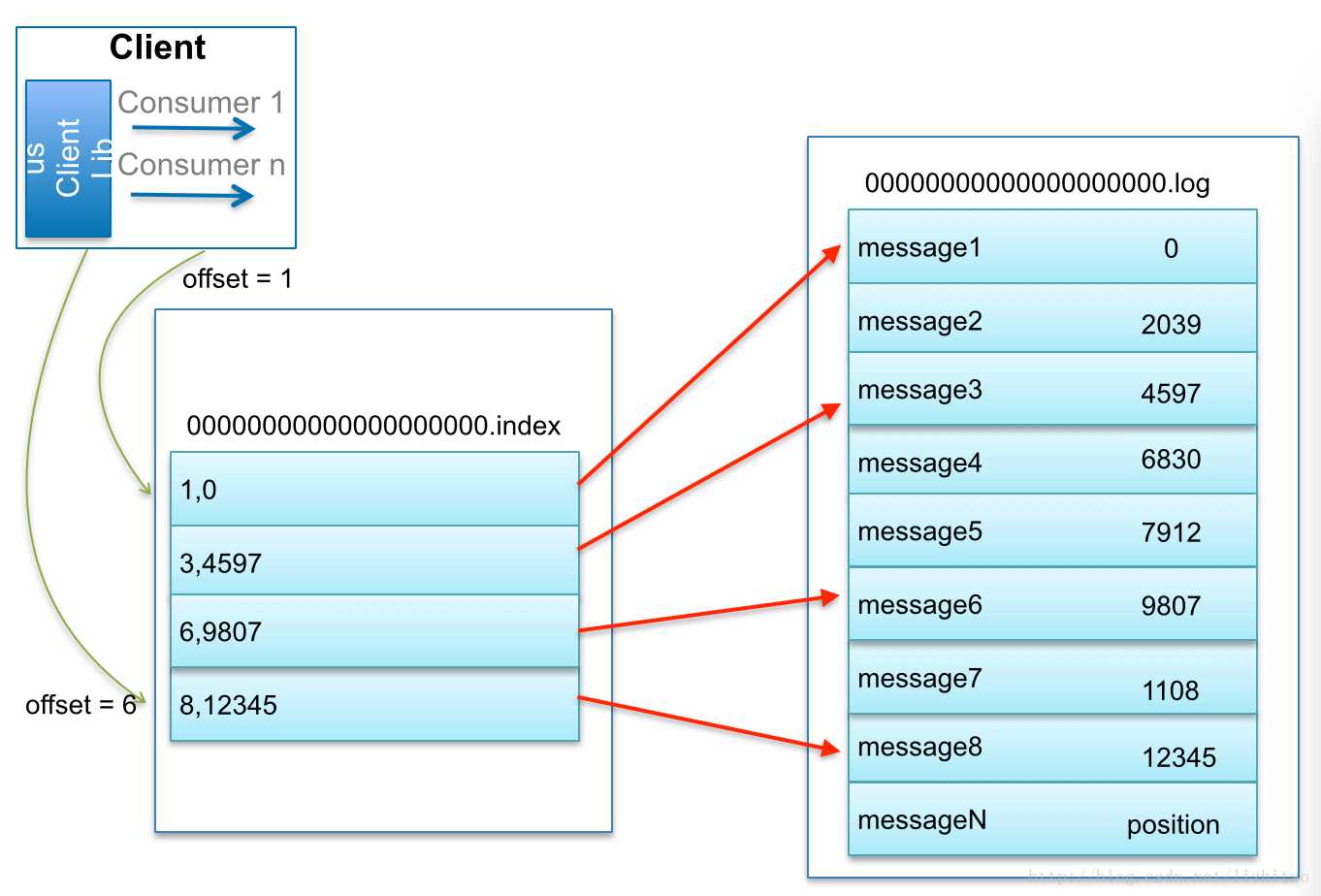
(2)位置索引,保存在index文件中,log日志默认每写入4K(log.index.interval.bytes设定的),会写入一条索引信息到index文件中,因此索引文件是稀疏索引,它不会为每条日志都建立索引信息。
下图是网上拿来的直接用了,log文件中的日志,是顺序写入的,由message+实际offset+position组成,索引文件的数据结构则是由相对offset(4byte)+position(4byte)组成,由于保存的是相对第一个消息的相对offset,只需要4byte就可以了,可以节省空间,在实际查找后还需要计算回实际的offset,这对用户是透明的。如下图由于log文件名是从0开始的,因此相对offset为3的实际offset是3+0,依然是3。
对于稀疏索引,尽管它的索引密度不高,但是offset是有序的,kafka查找一条offset对应的实际的消息时,可以通过index二分查找,获取到最近的低位offset,然后从低位offset对应的position开始,从实际的log文件中开始往后查找对应的消息。如要查找offset=5的消息,先去索引文件中找到低位的3 4597这条数据,然后通过4597这个字节偏移量,从log文件中从4597个字节开始读取,直到读取到offset=5的这条数据,这比直接从log文件开始读取要节省时间。二分查找的时间复杂度为O(lgN),如果从头遍历时间复杂度是O(N)。
注意下图的index中逗号是不存在的,这个图片加的逗号是为了方便理解。
(3)时间戳索引文件,它的作用是可以让用户查询某个时间段内的消息,它一条数据的结构是时间戳(8byte)+相对offset(4byte),如果要使用这个索引文件,首先需要通过时间范围,找到对应的相对offset,然后再去对应的index文件找到position信息,然后才能遍历log文件,它也是需要使用上面说的index文件的。
但是由于producer生产消息可以指定消息的时间戳,这可能将导致消息的时间戳不一定有先后顺序,因此尽量不要生产消息时指定时间戳。
消费者消费消息时,会记录消费者offset(注意不是分区的offset,不同的上下文环境一定要区分),这个消费者的offset,也是保存在一个特殊的内部分区,叫做__consumer_offsets,它就一个作用,那就是保存消费组里消费者的offset。默认创建时会生成50个分区(offsets.topic.num.partitions设置),一个副本,如果50个分区分布在50台服务器上,将大大缓解消费者提交offset的压力。可以在创建消费者的时候产生这个特殊消费组。
# 如果只启动了hadoop03一个broker,则所有的50个分区都会在这上面生成
[root@hadoop03 /home/software/kafka-2/bin]# sh kafka-console-consumer.sh --bootstrap-server hadoop03:9092 --topic football --from-beginning --new-consumer那么问题来了,消费者的offset到底保存到哪个分区呢,kafka中是按照消费组group.id来确定的,使用Math.abs(groupId.hashCode())%50,来计算分区号,这样就可以确定一个消费组下的所有的消费者的offset,都会保存到哪个分区了.
那么问题又来了,既然一个消费组内的所有消费者都把offset提交到了__consumer_offsets下的同一个分区,如何区分不同消费者的offset呢?原来提交到这个分区下的消息,key是groupId+topic+分区号,value是消费者offset。这个key里有分区号,注意这个分区号是消费组里消费者消费topic的分区号。由于实际情况下一个topic下的一个分区,只能被一个消费组里的一个消费者消费,这就不担心offset混乱的问题了。
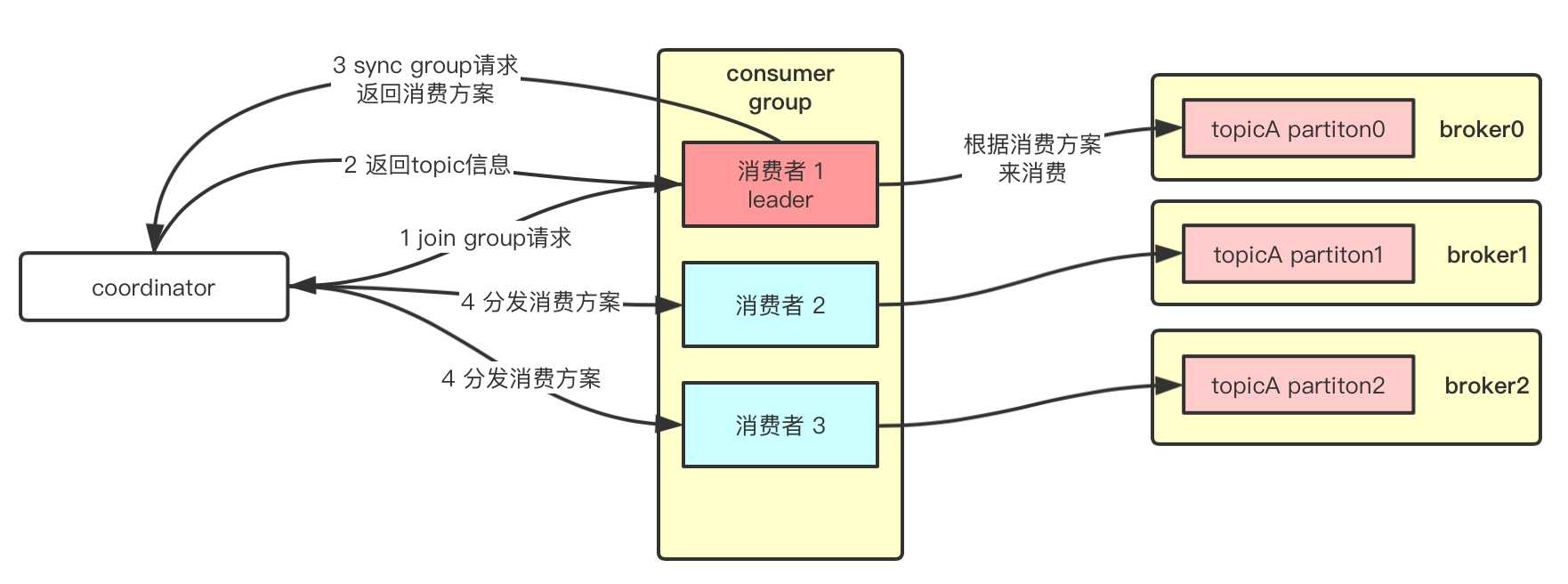
实际上,topic下多个分区均匀分布给一个消费组下的消费者消费,是由coordinator来完成的,它会监听消费者,如果有消费者宕机或添加新的消费者,就会rebalance,使用一定的策略让分区重新分配给消费者。如下图所示,消费组会通过offset保存的位置在哪个broker,就选举它作为这个消费组的coordinator,负责监听各个消费者心跳了解其健康状况,并且将topic对应的leader分区,尽可能平均的分给消费组里的消费者,根据消费者的变动,如新增一个消费者,会触发coordinator进行rebalance。
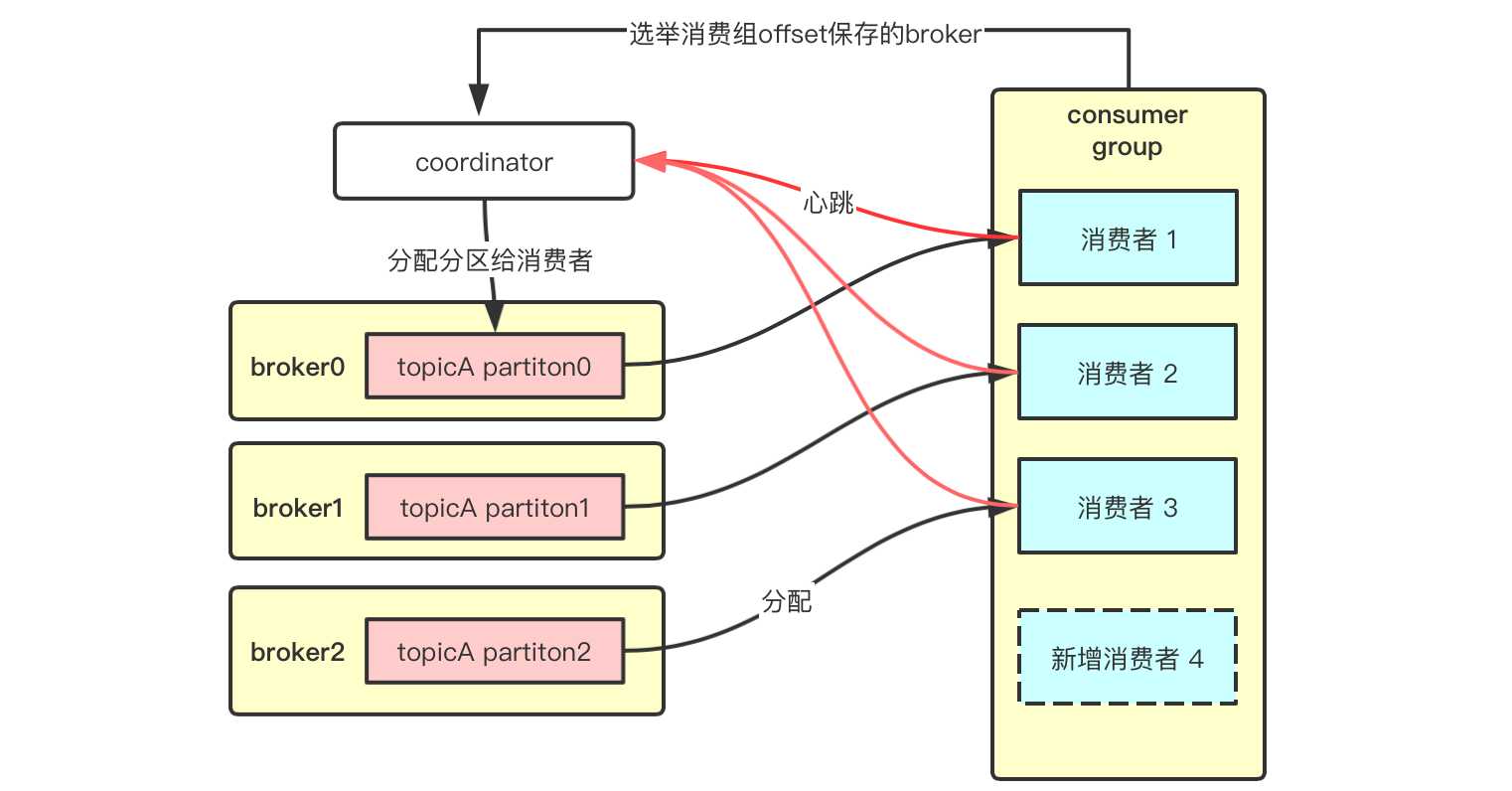
还有一个细节,消费者组和coordinator之间还进行了什么通信,各个消费者之间是如何做到默契不抢别人的资源?参考前辈整理如下。
(1)消费组会对选出的coordinator发送join group请求。
(2)coordinator会在消费组中选一个leader消费者,并且随后把要消费的topic信息返回给这个leader。
(3)leader消费者会根据topic信息,指定出一套符合自己消费组的消费方案,通过sync group请求返回给coordinator。
(4)coordinator收到分配方案后会分发给各个消费者。
(5)最后每个消费者身上都会有一套消费方案,都遵守它进行消费。
rebalance是消费组内达成一致如何消费topic分区的协议,文末书籍里提到有三个触发条件,这里只记录第一个因为它最常出现,那就是消费组里消费者或增加、或离去、或奔溃(它像极了人生)。其他两个,一个是topic分区数使用kafka shell增加了分区,还有一个就是消费的topic是按照正则去匹配的,当有了符合这个规则的新的topic出现,也会触发rebalance。
它有三种策略,为range、round robin、sticky。
假设topicA分区有p0~p6 一共6个分区,某个消费组有三个消费者,以此为基础来直观感受三个策略。
(1)range
有点类似python的range,它就是一个范围,会按照分区号来划分,结果就是:
消费者1 p0 p1,消费者2 p2 p3,消费者3 p4 p5
(2)round robin
就是随机均匀分配,结果略。
(3)sticky
上面两种分配存在一个小问题,就是有消费者宕机后,重新分配后,原本属于一个消费者消费得好好的的分区会被分到新的消费者。如range策略下消费者3挂掉,重新分配后会变成消费者1 p0 p1 p2 消费者2 p3 p4 p5,这样p2就被重分配了。考虑到管理消费者offset的复杂性,尽量希望维持原来的习惯,如果是sticky策略会变成消费者1 p0 p1 p4 消费者2 p2 p3 p5。
以上,理解不一定正确,写的也比较啰嗦,但学习就是一个不断了解和纠错的过程。
参考博文:
(1)https://blog.csdn.net/xiaoyu_bd/article/details/52398265
(2)《Apache Kafka实战》
kafka-Message、日志和索引文件、消费组、rebalance
标签:默认 details java对象 batch 字节数组 broker nal software sdn
原文地址:https://www.cnblogs.com/youngchaolin/p/12543436.html