标签:fir 注意 referer 除了 use strong 通过 错误提示 返回
服务器端通过校验请求头或者请求正文中特定的信息,用以区分正常用户和爬虫程序
1.User-Agent反爬虫
这是一种较为初级的判断方法,以下简称ua:
User-Agent就是请求头域之一,服务器能够从 User-Agent对应的值中识别客户端使用的操作系统CPU类型、浏览器、浏览器引擎、操作系统语言等。浏览器 User-Agent头域值的格式为:
浏览器标识 (操作系统标识;加密等级标识:浏览器语言) 渲染引擎标识 版本信息
如Chrome和Firefox:
Chrome:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36
Firefox:Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0
对比两个浏览器的User-Agent 值可以发现,它们的浏览器标识头都是Mozilla,操作系统标识相近,但渲染引擎、浏览器版本和厂商不同。服务器正是通过这些差异来区分客户端身份的。
在网络请求中,User-Agent是客户端用于表明身份的一种标识,服务器通常通过该头域的值来】断各户端的类型。要注意的是,User-Agent头域并非不可缺少,而且它的值可以被更改。
之所以选择 User-Agent头域作为校验对象,是因为很多编程语言和软件有默认的标识、在发起网络请求的时候,这个标识会作为请求头参数中的User-Agent头域值被发送到服务器。比如使用Python中的Requests 库向服务器发起 HTTP请求时,服务器读取的 User-Agent 值为:
?python-requests/2.21.0
便用Java和 PHP等语言编写的库也常设置有默认的标识,但并不是全都有,这跟开发者有安注意的是,HTTP协议并未强制要求请求头的格式.
既然客户端发起造求时会将UserAent发送给服务器端,那么我们只需要在服务器端对User-A头域值进行校验即可,校验流程如图4-5所示。客户端标识种类繁多,如何有效区分呢?这就需要田到黑名单策略了。
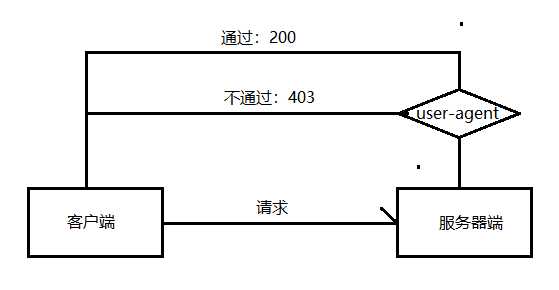
名单是包含事物名称的清单,而黑名单则是用来记录那些不符合要求的事物名称的清单。我们可以将非正常客户端的关键字加入黑名单中,利用 nginx的条件判断语句实现反爬虫。比如将Python、Java 和 PHP等关键词加人黑名单,那么只要服务器检测到 User-Agent头域值中包含黑名单中的关键词时、就会将此次请求的发起者视为爬虫,可以不予处理或者返回相应的错误提示
除了User-Agent 之外,常见的用于反爬虫的头域还有Host 和Referer。这种验证请求头信息中特定头的方式既可以有效地屏蔽长期无人维护的爬虫程序,也可以将一些爬虫初学者发起的网络请求拒之外,但是对于一些经验丰富的爬虫工程师,或许还需要更巧妙的反爬虫手段
标签:fir 注意 referer 除了 use strong 通过 错误提示 返回
原文地址:https://www.cnblogs.com/codexlx/p/12556341.html