标签:enc 知识 购物 style 缺点 去掉 还需要 副作用 row
?
关联规则(AssociationRules),无监督学习方法,用于知识发现。
其可以用于给数据进行标注,但缺点是其结果难以进行评估。
关联规则的最经典的案例就是购物篮分析。同样也可用于电影推荐、约会网站或者药物间的相互副作用。
?
关联规则首先定义: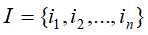 为项集(items),其中
为项集(items),其中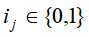 为项。
为项。
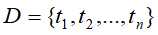 则为数据库(database),其中
则为数据库(database),其中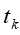 为事务(transaction)。事务是项的集合,即
为事务(transaction)。事务是项的集合,即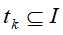 ,每个事务有唯一的标识索引,而规则定义如下:
,每个事务有唯一的标识索引,而规则定义如下:
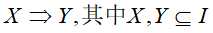
每条规则有两个不同的项集X和Y组成,X称为前提,Y则称为结论。
ID | milk | bread | butter | beer | diapers |
1 | 1 | 1 | 0 | 0 | 0 |
2 | 0 | 0 | 1 | 0 | 0 |
3 | 0 | 0 | 0 | 1 | 1 |
4 | 1 | 1 | 1 | 0 | 0 |
5 | 0 | 1 | 0 | 0 | 0 |
表1-1 超市销售记录表
在表中 {butter, bread} → {milk}是一条关联规则,表示如果顾客在购买butter和bread后,有很大的可能会购买milk。而类似这样的规则能够帮助超市制定一些促销活动,提高营业。
这条规则的发现,需要其符合一定的指标。这些指标分别为支持度(support)和置信度(confidence)等等。
支持度,用来表示项集在数据库中出现的频率。对于数据库D中的项集X,其定义为:数据库中包含项集X的事务数t与所有事务数T之比
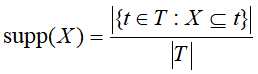
置信度,用来衡量规则的可信程度,对于规则 X → Y ,其置信度定义为:数据库中同时包含X 和 Y的事务数 与 只包含X的事务数之比
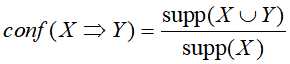
Lift定义为:
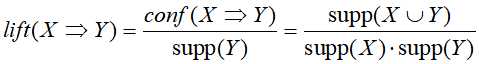
如果一个规则的lift值等于1,这表示前提和结论对应的事件相互独立;如果lift值大于1,指示了两个事件之间的相互依赖程度,值越大,关联越强;如果lift值小于1,表明一个item的出现对其他item的出现存在消极影响(相斥),反之亦然(其中一个出现另一个一般不会出现)。lift的意义在于其即考虑了置信度也考虑了整个数据集中结论的支持度。
Conviction,用来表示规则预测出错的概率,定义为:
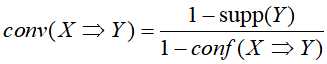
在有了这些可计算的指标后,还需要给这些指标设定一个阈值,关联规则只有满足最小支持度阈值和最小置信度阈值,这条规则才能认为是有趣的。而且关联规则的生成可分以下两个步骤:
关联规则的生成规则的阶段是直接的,但寻找频繁项集却是非常耗时的,常用的高效的算法有Apriori,FP-growth等。
?
Apriori算法
假设一家商铺经营着四种商品:商品0,商品 1,商品 2 和商品 3。根据排列组合,购买商品的情况有15种组合。如果商品的种类增加的话,购买商品的情况组合则可能呈指数级增长。Apriori根据:
来帮助减少在频繁项集上的搜索遍历。
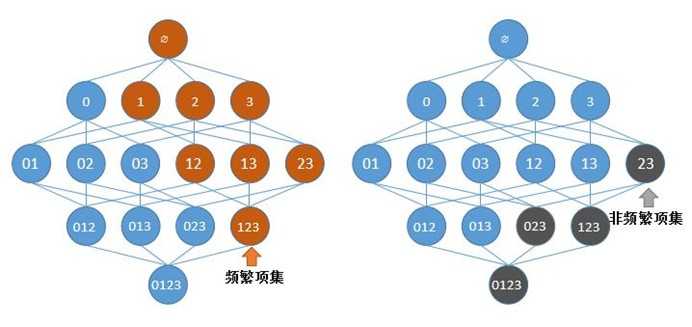
图1-1 Apriori搜索频繁项集的原理
Apriori 算法是发现频繁项集的一种方法。过程如下:
标签:enc 知识 购物 style 缺点 去掉 还需要 副作用 row
原文地址:https://www.cnblogs.com/lincz/p/12562592.html