标签:i++ 构造方法 setname 小结 方法 lse sys sort for
???TreeSet底层就是一个TreeMap(是一个简化版的TreeMap),当我们使用 TreeSet 的构造方法创建 TreeSet 对象,同时会创建一个TreeMap 对象,当你调用 add 方法向 TreeSet 添加元素,会在 add() 方法中调用 TreeMap 的 put(k,v) 方法。
????添加的元素不允许为null。
TreeSet的输出去重、默认升序排序。
import java.util.Set;
import java.util.TreeSet;
/**
* 例:放入Integer类型的元素到TreeSet中
*/
public class TestTreeSet {
public static void main(String[] args) {
Set<Integer> set = new TreeSet<>();
set.add(10);
set.add(1);
set.add(100);
// 打印的结果是已经排序的[1, 10, 100],因为TreeSet本质就是一个TreeMap,1、10、100都作为TreeMap的Key,value是一个哑巴值
// TreeMap集合中所有的值都是一个对象(哑巴)
System.out.println(set);
}
}
????注意:存储到TreeSet集合中的元素必须实现Comparable或者Comparator接口,否则抛出异常ClassCastException。
public class Student implements Comparable<Student> {
private int id;
private String stuName;
private int age;
public Student() {
super();
}
public Student(int id, String stuName, int age) {
super();
this.id = id;
this.stuName = stuName;
this.age = age;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getStuName() {
return stuName;
}
public void setStuName(String stuName) {
this.stuName = stuName;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + id;
result = prime * result + ((stuName == null) ? 0 : stuName.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (age != other.age)
return false;
if (id != other.id)
return false;
if (stuName == null) {
if (other.stuName != null)
return false;
} else if (!stuName.equals(other.stuName))
return false;
return true;
}
@Override
public String toString() {
return "Student [id=" + id + ", stuName=" + stuName + ", age=" + age + "]";
}
@Override
public int compareTo(Student o) {
return this.getAge()-o.getAge();
}
}
import java.util.Set;
import java.util.TreeSet;
public class TestTreeSet2 {
public static void main(String[] args) {
Set<Student> set = new TreeSet<>();
set.add(new Student(101,"Jerry", 16));
set.add(new Student(103,"Jack", 14));
set.add(new Student(105,"Jackson", 13));
// Exception in thread "main" java.lang.ClassCastException: com.whsxt.day8.treeset.Student cannot be cast to java.lang.Comparable
// 存储到TreeSet集合中的元素必须实现Comparable或者Comparator接口
System.out.println(set);
}
}
????概念:以红黑树的接口存储键值对。TreeMap是红黑二叉树的典型实现。
????特征:放入TreeMap集合中的元素都是按照指定规则进行排序的。
????key(键)不允许为null。
????TreeMap的输出默认以key(键)升序排序、去重。
?场景1:将key-value对放入TreeMap集合中
import java.util.Map;
import java.util.TreeMap;
/**
* 输出结果:
* 1 abc
* 2 bgw
* 4 bbb
* 5 cdd
* 6 cds
*/
public class TestTreeMap {
public static void main(String[] args) {
Map<Integer, String> map = new TreeMap<>();
map.put(1, "abc");
map.put(4, "aaa");
map.put(6, "cds");
map.put(2, "bgw");
map.put(5, "cdd");
map.put(4, "bbb");
for (Map.Entry<Integer, String> entry : map.entrySet()) {
Integer key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "\t" + value);
}
}
}
????注意:工作中TreeMap使用很少,因为数据结构复杂(以树的结构存储数据),存储TreeMap集合的元素是有序的(经过排序的),既然排序就会涉及比较,将新元素放入集合之前会先比较然后放入,所以耗时(效率低)。
? 场景2:将Student作为Key,String作为Value,放入TreeMap集合中。
???使用Comparable(内部比较器)实现。
public class Student implements Comparable<Student> {
private int id;
private String name;
public Student() {
super();
}
public Student(int id, String name) {
super();
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Student [id=" + id + ", name=" + name + "]";
}
@Override
public int compareTo(Student o) {
return this.getId() - o.getId();
}
}
import java.util.Map;
import java.util.TreeMap;
public class TestTreeMap2 {
public static void main(String[] args) {
Map<Student,String> map = new TreeMap<>();
map.put(new Student(11,"Jackson"), "AAA");
map.put(new Student(12,"Jack"), "AAA");
System.out.println(map);
}
}
? 使用Comparator(外部比较器)实现。
import java.util.Comparator;
import java.util.Map;
import java.util.TreeMap;
public class TestTreeMap2 {
public static void main(String[] args) {
Map<Student,String> map = new TreeMap<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.getId()-o2.getId();
}
});
map.put(new Student(11,"Jackson"), "AAA");
map.put(new Student(12,"Jack"), "AAA");
System.out.println(map);
}
}
? 外部比较器使用Lambda表达式实现。
import java.util.Map;
import java.util.TreeMap;
public class TestTreeMap2 {
public static void main(String[] args) {
Map<Student,String> map = new TreeMap<>((o1,o2)->o1.getId()-o2.getId());
map.put(new Student(22,"Jackson"), "AAA");
map.put(new Student(18,"Jack"), "AAA");
System.out.println(map);
}
}
???注意:TreeMap中的Key,必须实现Comparable接口或者实现Comparator接口,否则会抛出ClassCastException。
????LinkedHashSet是有序的,不会自动进行排序,如果想让放入Set集合的元素是有序的,可以使用LinkedHashSet。
????添加的元素允许为null,元素不允许重复。
import java.util.LinkedHashSet;
import java.util.Set;
/**
* 放入集合中的元素是有序的
*/
public class TestLinkedHashSet {
public static void main(String[] args) {
Set<String> set = new LinkedHashSet<>();
set.add("Tom");
set.add("Adam");
set.add("Bob");
set.add("Merry");
set.add("Tomas");
set.add("Bob");
set.add(null);
System.out.println(set); // [Tom, Adam, Bob, Merry, Tomas, null]
}
}
? HashSet和LinkedHashSet做200W的压力测试,HashSet性能略高于LinkedHashSet
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Set;
import org.junit.Test;
public class TestSet {
private final static int SIZE=2000000;
private Set<Integer> linkSet = new LinkedHashSet<>();
private Set<Integer> set = new HashSet<>();
/**
* add()方法200W次 耗时121ms
*/
@Test
public void testAddLinkedHashSet() {
for(int i=0;i<SIZE;i++) {
linkSet.add(i);
}
System.out.println(linkSet.size());
}
/**
* add()方法200W次 耗时101ms
*/
@Test
public void testAddHashSet() {
for(int i=0;i<SIZE;i++) {
set.add(i);
}
System.out.println(set.size());
}
}
????LinkedHashMap是有序的,不会自动进行排序,如果你想让key-value(键值对)在集合中有序,可以使用LinkedHashMap。
????添加的 key-value 允许为null,key不允许重复。
? 场景:使用LinkedHashMap存储key-value对
import java.util.LinkedHashMap;
import java.util.Map;
public class TestLinkedHashMap {
public static void main(String[] args) {
Map<String, String> map = new LinkedHashMap<>();
map.put("北京", "china");
map.put("上海", "china");
map.put("天津", "china");
map.put("长沙", "china");
map.put("北京", "china");
map.put(null, null);
System.out.println(map); // {北京=china, 上海=china, 天津=china, 长沙=china, null=null}
}
}
? 压力测试put(k,v)方法200W,HashMap效率略高于LinkedHashMap
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.Map;
import org.junit.Test;
public class TestMap {
private final static int SIZE=2000000;
private Map<Integer,Integer> linkMap = new LinkedHashMap<>();
private Map<Integer,Integer> map = new HashMap<>();
/**
* put(k,v)方法200W 耗时109ms
*/
@Test
public void putHashMap() {
for(int i=0; i<SIZE; i++) {
map.put(i,i);
}
System.out.println(map.size());
}
/**
* put(k,v)方法200W 耗时120ms
*/
@Test
public void putLinkedHashMap() {
for(int i=0; i<SIZE; i++) {
linkMap.put(i,i);
}
System.out.println("LinkedHashMap size=" + linkMap.size());
}
}
???Vector 类实现了可扩展的对象数组。
????SinceJDK1.0,是ArrayList的前身,从JDK1.2开始Vector就废弃了(不使用了),ArrayList取而代之。
????Vector是线程安全的,效率低;ArrayList非线程安全。
???Vector扩容机制是原始容量的2倍,ArrayList是原始容量的1.5倍。
import java.util.List;
import java.util.Vector;
public class TestVector {
public static void main(String[] args) {
// Vector也实现了List接口
// Vector扩容机制是:原始容量的2倍
List<Integer> list = new Vector<>();
for(int i=0;i<20;i++) {
list.add(i);
}
list.add(10);
}
}
?
? 场景:100W压力,测试ArrayList和Vector,目的:谁的效率高。
? ArrayList执行效率比Vector高,因为ArrayList没有synchronized关键字。
import java.util.ArrayList;
import java.util.List;
import java.util.Vector;
import org.junit.Test;
public class TestList {
private final static int SIZE=1000000;
private List<Integer> list = new ArrayList<>();
private List<Integer> vector = new Vector<>();
/**
* add()方法100W 耗时13ms
*/
@Test
public void testAddArrayList() {
for(int i=0; i<SIZE; i++) {
list.add(i);
}
System.out.println("ArrayList size=" + list.size());
}
/**
* add()方法100W 23ms
*/
@Test
public void testAddVector() {
for(int i=0; i<SIZE;i++) {
vector.add(i);
}
System.out.println("Vector size=" + vector.size());
}
}
????SinceJDK1.0,是HashMap的前身,也是使用键值对存储数据。
???Hashtable类和HashMap用法几乎一模一样,只是HashTable的方法中添加了synchronizeed(同步),效率低。
???Hashtable不允许 key 或 value 为null。
?
? 为什么会被淘汰?
????1. 是一个线程安全的键值对集合,put元素到HashTable效率相对较低。
???2. 不允许有null值,否则就会抛出空指针异常。
????3. 默认容量是11,所以扩容相对较频繁。容量会出现莫名其妙的bug,最好设置为2的次幂。
? SinceJDK1.0,继承了Hashtable 类,以使用键值对存储数据,
???put(key, value):由于没有指定泛型,所以key-value可以存放任意类型,但不允许为空。
????get(key):根据key(键)来获对应取值,查找不到返回null。
????Properties 类的详细使用:https://blog.csdn.net/yjltx1234csdn/article/details/93769032
???使用Collections中synchronizedList()实现。
package com.whsxt.day8.list;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class TestArrayList {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
// 将ArrayList由非线程安全变为线程安全
List<Integer> syncList = Collections.synchronizedList(list);
// syncList就是一个线程安全的ArrayList
System.out.println(syncList);
}
}
| ArrayList | LinkedList |
|---|---|
| 本质是一个数组,适合查找 | 本质是一个链表,适合插入,添加,删除 |
| 构造方法有一个int类型的参数,表示数组的长度 | 构造方法没有int类型的参数 |
| 遍历元素效率高,删除首部和中间元素效率低 | 删除首部和中间元素效率高,遍历元素效率低 |
? ArrayList和LinkedList区别:https://www.cnblogs.com/yonyong/p/9323588.html
| ArrayList | Vector |
|---|---|
| 非线程安全的,性能好 | 方法都是同步的(Synchronized),线程安全的,性能差 |
| 初始容量为10,扩容机制,原始容量的1.5倍 | 初始容量为10,扩容机制,原始容量的2倍 |
| 第一次add方法被调用的时候指定容量 | 创建对象指定容量 |
| SinceJDK1.2 | SinceJDK1.0 |
????ArrayList和Vector区别:https://www.cnblogs.com/guweiwei/p/6632341.html
| HashMap | HashTable |
|---|---|
| 非线程安全 | 方法都是同步的(Synchronized),线程安全,速度慢 |
| 加载因子为0.75,默认容量16 | 加载因子为0.75,默认容量11 |
| 扩容增量:原容量的 1 倍 | 扩容增量:2*原数组长度+1 |
| 允许 key-value 为null | 不允许 key-value 为null |
| sinceJDK1.2 | sinceJDK1.0 |
????一般情况下,HashMap能够比Hashtable工作的更好、更快,主要得益于它的散列算法,以及没有同步。应用程序一般在更高的层面上实 现了保护机制,而不是依赖于这些底层数据结构的同步,因此,HashMap能够在大多应用中满足需要。推荐使用HashMap,如果需要同步,可以使用同 步工具类将其转换成支持同步的HashMap。
????HashMap实现同步:Collections.synchronizedMap()
????HashMap默认容量为何是16:16是2^4,可以提高查询效率,另外,32=16<<1。
????length 的值为 2 的整数次幂,**h & (length - 1)**相当于对 length 取模。这样提高了效率也使得数据分布更加均匀。
????为什么会更加均匀? length的值为偶数,length - 1 为奇数,则二进制位的最后以为为1,这样保证了 h & (length - 1) 的二进制数最后一位可能为1,也可能为0。如果为length为奇数,那么就会浪费一半的空间。
????他们内部都以一个数组。
???都有get()方法。
???ArrayList实际上也是以键值对的形式存储数据,只不过ArrayList的key只能是整数类型,HashMap的key可以使任意类型,但是必须要覆盖hashCode()和equals()方法。
???HashSet本质就是一个HashMap,也就是说HashSet有一个HashMap的属性,每当创建一个HashSet对象,在它的构造方法中就会创建一个HashMap对象。
???加载因子为0.75:即当 元素个数超过容量长度的0.75倍 时,进行扩容。
???扩容增量:原容量的 1 倍。(如 HashSet的容量为16,一次扩容后是容量为32)
????HashSet实际上也是使用键值对形式存储数据,key必须唯一,值可以重复(哑巴值)。
? 都以Key对象产生的hashCode来排序的。
String str1="Tom";
String str2= new String("Tom");
set.add(str1);
set.add(str2);
// 实际大小是1,因为str1和str2有着相同的hashCode
????他们都是树形结构,以红黑树的形式存储数据。
????红黑树:是一个平衡的二叉树。
????二叉树特征:每个节点最多只能有两个子节点,左边的子节点叫做左子树,右边的节点叫做右子树,左子树的值永远都小于该节点,右子树的值永远都大于该节点。
????平衡:自己被右孩子代替了,然后自己变成左孩子,叫做左旋转。
?????? 自己被左孩子代替了,然后自己变成右孩子,叫做右旋转。
????变色 :二叉树由红色节点和黑色节点构成。
????红黑树原则:
??????1. 根节点必须是黑色节点
??????2. 子节点可以是红色也可以是黑色
???????3. 一旦某个节点是红色,那么它下面的子节点必须是黑色
??????4. 叶子必须是黑色,叶子节点下面不能再有子节点
???????5. 某个节点到叶子节点的所有路径包含相同数量的黑色节点
???小结:有红必有黑,红红不相连(父节点是红色,所有的子节点必须是黑色)。
???????根节点的左边永远都小于根节点,右边永远都大于根节点。
????目的:方便比较(方便查找),查找的次数不能大于树的深度
? 场景:创建一个TreeSet集合,向集合中添加55,56,57,58,59 删除57,最后添加60,目的理解元素在TreeSet中如何存储(表示)。
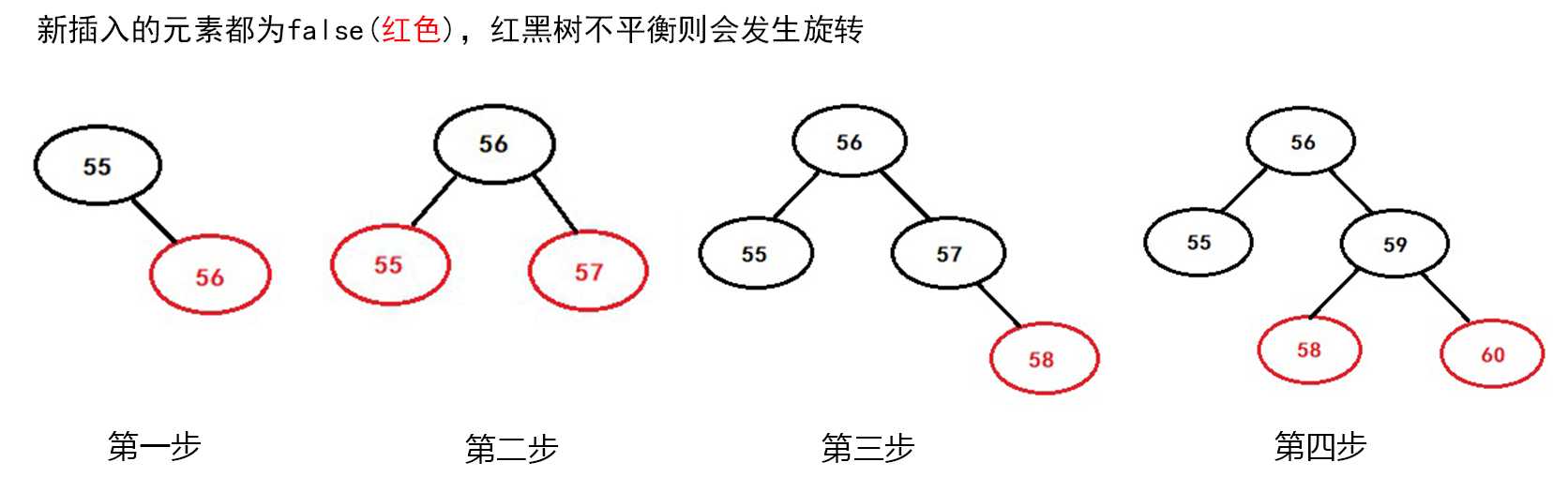
import java.util.Set;
import java.util.TreeSet;
/**
* black ---> true
* red ---> false
*/
public class TestTreeSet3 {
public static void main(String[] args) {
Set<Integer> set = new TreeSet<>();
set.add(55);
set.add(56);
set.add(57);
set.add(58);
set.remove(57);
set.add(59);
set.add(60);
System.out.println(set);
}
}
????定义一个ArrayList集合,里面有若干个Student对象[id,name,age,成绩,爱好],要求从集合中找到成绩大于90,并且年龄大于16的学生分数,此外还要对分数进行排序[93,92,91]
public class Student {
private int id;
private String stuName;
private int stuAge;
private int score;
private String stuHobby;
public Student() {}
public Student(int id, String stuName, int stuAge, int score, String stuHobby) {
this.id = id;
this.stuName = stuName;
this.stuAge = stuAge;
this.score = score;
this.stuHobby = stuHobby;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getStuName() {
return stuName;
}
public void setStuName(String stuName) {
this.stuName = stuName;
}
public int getStuAge() {
return stuAge;
}
public void setStuAge(int stuAge) {
this.stuAge = stuAge;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
public String getStuHobby() {
return stuHobby;
}
public void setStuHobby(String stuHobby) {
this.stuHobby = stuHobby;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + id;
result = prime * result + score;
result = prime * result + stuAge;
result = prime * result + ((stuHobby == null) ? 0 : stuHobby.hashCode());
result = prime * result + ((stuName == null) ? 0 : stuName.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (id != other.id)
return false;
if (score != other.score)
return false;
if (stuAge != other.stuAge)
return false;
if (stuHobby == null) {
if (other.stuHobby != null)
return false;
} else if (!stuHobby.equals(other.stuHobby))
return false;
if (stuName == null) {
if (other.stuName != null)
return false;
} else if (!stuName.equals(other.stuName))
return false;
return true;
}
@Override
public String toString() {
return "Student [id=" + id + ", stuName=" + stuName + ", stuAge=" + stuAge + ", score=" + score + ", stuHobby=" + stuHobby + "]";
}
}
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
/**
* 定义一个ArrayList集合,里面有若干个Student对象[id,name,age,成绩,爱好],
* 要求从集合中找到大于90的成绩,
* 并且年龄大于16的学生,只找出最大的3个,不能重复。此外还要对分数进行排序[99,98,97]
*
* 1. 遍历集合中的所有Student对象,过滤掉年龄小于16的学生,放入新集合
* 2. 提取成绩,将提取的结果放入一个新的集合中[89,91,88,87,91....]
* 3. 过滤掉重复的分数
* 4. 只限制3个成绩
* 5. 成绩排序
*/
public class TestStudent {
private static List<Student> list = new ArrayList<>();
static{
list.add(new Student(101,"黄欣", 18, 89,"Football"));
list.add(new Student(21,"张衡", 16, 91,"Basketball"));
list.add(new Student(31,"陈亮", 17, 88,"Pinpong"));
list.add(new Student(11,"李阳", 19, 91,"Tennis"));
list.add(new Student(61,"唐科资", 20, 91,"Swimming"));
list.add(new Student(81,"邹涛", 22, 99,"HightJump"));
list.add(new Student(51,"陈勇", 21, 98,"Running"));
list.add(new Student(81,"郑行", 22, 97,"HightJump"));
list.add(new Student(51,"胡黎", 15, 78,"Running"));
list.add(new Student(51,"关洪颜", 15, 93,"Running"));
}
public static void main(String[] args) {
//过滤掉<=16的学生信息,保留>16的学生信息,将过滤结果放入新集合中
List<Student> stuList =new ArrayList<>();
for (Student student : list) {
if(student.getStuAge()>16) {
stuList.add(student);
}
}
//提取成绩
List<Integer> scoreList = new ArrayList<>();
for (Student stu : stuList) {
scoreList.add(stu.getScore());
}
System.out.println(scoreList);
//去掉重复的成绩
distinct(scoreList);
System.out.println(scoreList);
//排序
Collections.sort(scoreList,Collections.reverseOrder());
System.out.println(scoreList);
//限制3个
scoreList = scoreList.subList(0,3);
System.out.println(scoreList);
}
/**
* 去重
* @param scoreList
*/
private static <E> void distinct(List<E> scoreList) {
Set<E> set = new HashSet<>();
set.addAll(scoreList);
scoreList.clear();
scoreList.addAll(set);
}
}
标签:i++ 构造方法 setname 小结 方法 lse sys sort for
原文地址:https://www.cnblogs.com/lyang-a/p/12569170.html