标签:概率 一个 期望 error exist off pen exp math
假设空间(Hypothesis space):包含学习得到的模型的条件概率分布或决策函数集合;
\[\mathcal{F}=\{f|Y=f_\theta(X),\theta\in\R^n\} \]
每一个具体的输入为一个实例,通常由特征向量表示,所有特征向量存在的空间为特征空间,其中每一维对应于一个特征。
\[(实例)=\{特征向量=(特征_1,...,特征_p)|特征向量\in\{特征空间|特征空间\sub输入空间\}\} \]
\(x_i\)表示多个输入变量中的第 \(i\) 个变量,其中 \(X_i^{(j)}\) 表示第 \(i\) 个变量的第 \(j\) 个特征。
\[x_i=\left(\begin{array}{c}x_i^{(1)}\\x_i^{(2)}\\\vdots\\x_i^{(n)}\end{array}\right)\in X=(x_1,...,x_N) \]
训练数据由输入与输出对 (样本) 组成,通常表示为:
**风险函数(期望损失)**:
其中,\(L(Y,P(Y|X))=-\log{P(Y|X)}\)为对数似然损失函数。
学习的目标当然是选择期望风险最小的模型,然而联合分布是未知的,所以监督学习就成为一个病态问题。若给定一个训练数据集:\(T=\{(x_1,y_1),...,(x_N,y_N)\}\), 模型\(f(X)\)关于训练数据集的平均损失称为**经验风险(empirical loss)**,记作:
由于现实中训练样本数量有限,所以用经验风险估计期望风险往往并不理想,需要进行一些矫正,这就涉及到:经验风险最小化、和结构风险最小化。
当样本数据量过小的话,经验风险最小化学习就会产生过拟合现象。结构风险最小化是为了防止过拟合而产生的策略,结构风险最小化等价于正则化,在经验风险上加上表示模型复杂度的正则化项或罚项,在上述条件下,可定义为:
SRM最小化策略认为结构风险最小的模型就是最优模型,所以求最优模型就是求解最优化问题:
训练误差的大小本质上不重要,但是却反映了学习方法对未知测试数据集的预测能力(泛化能力 generalization ability)。
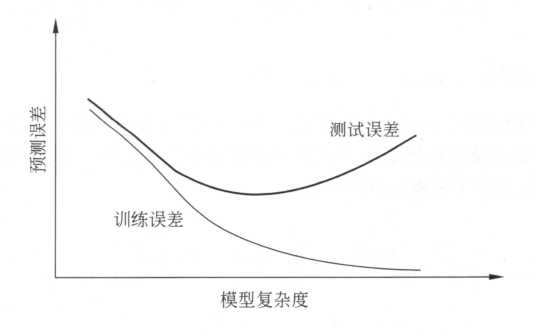
我们选择模型时,应选择复杂度适当的模型,以达到测试误差最小的学习目的,两种常见的选择方法为正则化与交叉验证。
正则化是结构风险最小化策略的实现,在经验风险上加一个正则化项或罚项,一般是模型复杂度的单调递增函数。
- Occam‘s razor principle
在假设空间中,能够很好的解释已知数据且十分简单才是最好的模型。
如果给定的样本数据重组,则可以将数据集分成三部分:
泛化能力反映了模型对未知数据的预测能力,现实中采用最多的方法是通过训练误差来评价学习方法的泛化能力,但是这种评价是依赖测试数据集的,由于测试集也是有限的,所以评价结果可能并不可靠。于是统计学习从理论上对学习方法的泛化能力进行分析:
若学到的模型为:\(\hat{f}\),那么用这个模型对未知数据预测的误差即为泛化误差(generalization error):
\[R_{exp}(\hat{f})=E_P[L(Y,\hat{f}(X))]=\int_{\mathcal{X}\times\mathcal{Y}}L(y,\hat{f}(x))P(x,y)dxdy \]事实上,泛化误差就是学习得到模型的期望风险。
泛化能力分析往往是通过研究泛化误差的概率上界进行的,其通常具有以下性质:
为了证明泛化误差上界定理,我们会首先引入霍夫丁不等式:
(Hoeffding Inequality)
In probability theory, Hoeffding‘s inequality provides an upper bound on the probability that the sum of bounded independent random variables deviates from its expected value by more than a certain amount.(随机变量的和与其期望值偏差的概率上限) Hoeffding‘s inequality was proven by Wassily Hoeffding in 1963.\(^{[*]}\).
\[\begin{equation} \mathbb{P}(\overline{X}-\mathbb{E}[\overline{X}]\ge t) \le exp\left(-\frac{2t^{2}n^{2}}{\sum_{i=1}^{n}(b_i-a_i)^2}\right) \end{equation} \]\[\begin{equation} \mathbb{P}(\mathbb{E}[\overline{X}]-\overline{X}\ge t) \le exp\left(-\frac{2t^{2}n^{2}}{\sum_{i=1}^{n}(b_i-a_i)^2}\right) \end{equation} \]\(X_i\in[a_i,b_i],i=1,...,n,t>0,\overline{X}=\frac1n\sum X_i\).
\(^{[ *]}\)Wikipedia
对任意函数\(f\in\mathcal{F},\hat{R}(f)\)是\(N\)个独立的随机变量\(L(Y,f(X))\)的样本均值,\(R(f)\)是随机变量\(L(Y,f(X))\)的期望值若\(\forall i,[a_i,b_i]\sub[0,1]\)那么由 \(Hoeffding\)不等式:对\(\forall\varepsilon>0\):
由于\(\mathcal{F}=\{f_1,f_2,...,f_d\}\)是一个有限集合,故
其具有等价形式:
若令\(\delta=d\exp{(-2N\varepsilon^2)}\)则有:
至少以概率\((1-\delta)\),有\(R(f)<\varepsilon+\hat{R}(f)\).
由泛化误差上界可知,
其中\(f_N=\arg\min_{f\in\mathcal{F}}\hat{R}(f)=\arg\min_{f\in\mathcal{F}}\frac1N\sum L(y_i,f(x_i))\).
(马尔可夫不等式)
如果\(U\in R\)是非负随机变量,那么对于任意\(\forall t>0\):
(切比雪夫不等式)
特别的,对于\(n\hat{R}_n(h)\sim Binom(n,R(h))\),有\(E(\hat{R}_n(h))=R_n(h)=\mu, \sigma^2=\frac{R(h)(1-R(h))}{n}\),所以:
其中:\(\hat{R}_n(h)=\frac1n\sum I_{\{h(X_i)\neq Y_i\}}\)为经验误差
(切尔诺夫界)
其中\(M_z(s)=E[e^{sZ}]\)为矩生成函数。
[霍夫丁不等式]
标签:概率 一个 期望 error exist off pen exp math
原文地址:https://www.cnblogs.com/rrrrraulista/p/12571044.html