标签:数据规模 type nbsp order prim tab 意图 创新 之间
性能建议:
尽量避免使用 Left join 或 Right join,而用 Inner join 在使用 Left join 或 Right join 时, ON 会优先执行, where 条件在最后执行,所以在使用过程中,条件尽可能的在 ON 语句中判断,减少 where 的执行。
少用子查询,而用 join。
Mycat 目前版本支持跨分片的 join,主要实现的方式有四种:全局表, ER 分片, catletT(人工智能)和 ShareJoin, ShareJoin 在开发版中支持,前面三种方式 1.3.0.1 支持 。
1. 全局表
一个真实的业务系统中,往往存在大量的类似字典表的表格,它们与业务表之间可能有关系,这种关系,可以理解为“标签” ,而不应理解为通常的“主从关系” ,这些表基本上很少变动。
考虑到字典表具有以下几个特性:
• 变动不频繁
• 数据量总体变化不大
• 数据规模不大,很少有超过数十万条记录。
鉴于此, MyCAT 定义了一种特殊的表,称之为“全局表” ,全局表具有以下特性:
• 全局表的插入、更新操作会实时在所有节点上执行,保持各个分片的数据一致性
• 全局表的查询操作,只从一个节点获取
• 全局表可以跟任何一个表进行 JOIN 操作
全局表的配置如下:
<table name="company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" />
2. ER Join
MyCAT 借鉴了 NewSQL 领域的新秀 Foundation DB 的设计思路, Foundation DB 创新性的提出了 Table Group 的概念,其将子表的存储位置依赖于主表,并且物理上紧邻存放,因此彻底解决了 JION 的效率和性能问题,根据这一思路,提出了基于 E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上。
customer 采用 sharding-by-intfile 这个分片策略,分片在 dn1,dn2 上, orders 依赖父表进行分片,两个表的关联关系为 orders.customer_id=customer.id。于是数据分片和存储的示意图如下
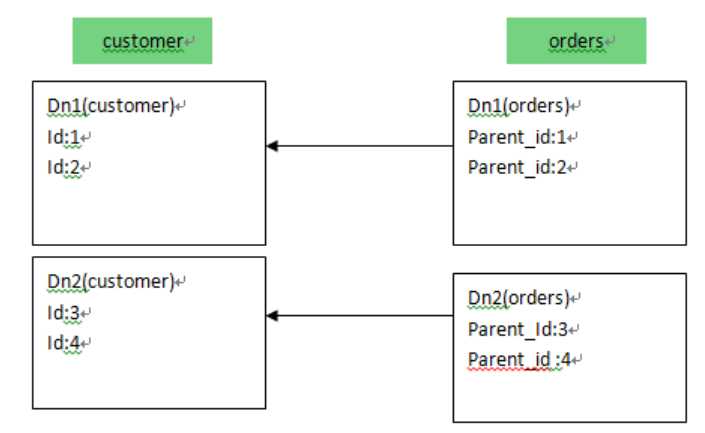
配置示例:
<table name="customer" dataNode="dn1,dn2" rule="sharding-by-intfile"> <childTable name="orders" joinKey="customer_id" parentKey="id"/> </table>
3. Share join
ShareJoin 是一个简单的跨分片 Join,基于 HBT 的方式实现。
目前支持 2 个表的 join,原理就是解析 SQL 语句,拆分成单表的 SQL 语句执行,然后把各个节点的数据汇集
支持任意配置的两个表,如:
<table name="A" dataNode="dn1 " rule="auto-sharding-long" />
<table name="B" dataNode=" dn2,dn3" rule="auto-sharding-long" />
上面的配置是官方文档中的示例,但是我试的时候,连 mycat 都启动不起来。把这两个配置中的 rule 去掉,加上 primaryKey="id" autoIncrement="true" , mycat 可以启动,但是运行这两个表的 join 查询,会抛错。
4. catlet(人工智能)
mycat 提供了一些接口,需要自己定逻辑怎么把不同分片的表 join 起来。
标签:数据规模 type nbsp order prim tab 意图 创新 之间
原文地址:https://www.cnblogs.com/langfanyun/p/12567355.html