标签:code 路由表 编程 img 引擎 pen 开始 大数 深圳
读写分离:数据库主从集群(一主一从或一主多从),主负责读写、从仅负责读
适用场景:分散了数据库读写操作的压力,适用于读多写少的情况。
两个设计细节点:主从复制延迟问题和实现方式
1)主从复制延迟
造成的问题:业务将数据库写入数据库主服务器后立刻读取,读操作访问的是从机的话,读取不到最新的数据,导致出现问题。
解决方法:
缓存。读取时,先差缓存再查库。
2)实现方式
两种方式:程序代码封装、中间件封装
使用场景:分散了数据库的存储压力。
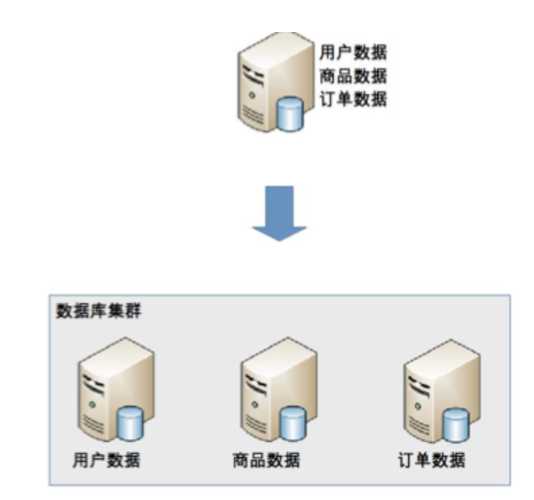
分库:按业务模块将数据分散到不同数据库上。
带来的问题
1)join操作问题。原本在同一数据库中的表分散到不同数据库中,导致无法使用join查询
2)事务问题。表分散到不同数据库中,无法通过事务统一修改。
3)成本问题。本来一台机器的事情,现在要多台。
分表:对单表数据进行拆分。
两种方式:垂直分表和水平分表。注意:可能不止分一次。
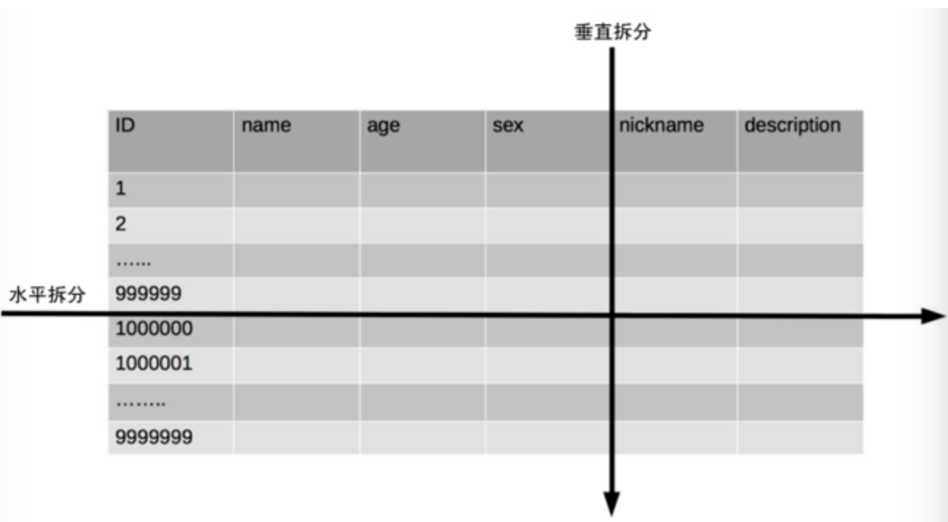
垂直分表
适合将某些不常用且占用了大量空间的列拆分出去。
带来的问题
表操作的数据增加了。例如原来只要一次就能把name、age、nickname等全查出来,现在要两次。
水平分表带来的问题
适合表行数特别大的表。当表的数据量达到千万级别时,要警觉起来,这很可能是架构性能瓶颈或隐患。
带来的问题
路由:水平分表后,某条数据具体属于哪个子表,需要增加路由算法进行计算。
常见路由算法
范围路由
选择有序的数据列(如整型、时间戳)作为路由的条件,不同分段分散到不同数据库表中。举例:用户id,按1000000分段,1~999999在数据库1的表中,1000000-1999999在数据库2表中
复杂点:分段大小的选取上。太小导致子表过多;太大,单表依然存在性能问题。建议分段在100万至2000万之间。
优点:随数据增加可平滑扩充新表。
缺点:数据分布不均匀。如最后一个分段数据量太少了。
Hash路由
选取某个列(或多个列组合)的值进行hash运算,据hash结果分散到不同数据库中。举例:hash(user_id) % 10
复杂点:初始表数量的选取上。表太多维护麻烦,太少可能导致单表性能问题
优点:数据分布较均匀。
缺点:扩充新表麻烦,所有数据要重新分布。
配置路由
增加路由表,专门记录路由信息。举例:user_router表,含user_id和table_id两列,据user_id可查table_id
优点:使用灵活,扩充新表时,只需要迁移指定数据,修改路由表即可。
缺点:必须多查询一次路由表,影响性能;路由表过大,性能差,又面临分表问题。
join操作
与其他表join时,需要多次join,将结果合并
count()操作
多个子表导致没法直接获取到count值。
常见处理方式:
count()相加
缺点:性能比较低,需要多次查询多个子表
增加记录数表,包含table_name、row_count两个字段,每次插入或删除子表数据都更新记录数表
优点:性能较好,仅需要一次查询
缺点:复杂度提升,可能导致数据不一致;增加了数据库写压力
order by操作
多个子表导致无法排序,需要查每个子表,汇总后排序。
实现方式:程序代码封装和中间件封装。
与读写分离相比更复杂,读写分离仅需识别SQL是读还是写(select、update、insert、delete)。
分库分表除了判断操作类型,还要判断需要操作的表、操作函数(如count)、order by、group by等,根据操作进行不同处理。
关系数据库的缺点
1)存储的是行记录,无法存储数据结构
2)数据库schema扩展不方便
3)大数据场景下IO较高
4)全文检索功能较弱。
常见NoSQL方案
Kv存储:解决无法存数据结构的问题。Redis。
文档存储:解决强scheme约束问题。MongoDB。
列式数据库:解决大数据场景下IO问题。HBase。
全文搜索引擎:解决全文检索性能问题。Elasticsearch。
缓存典型使用场景
需要经过复杂运算后得出的数据
读多写少
概念:缓存没法发挥作用,业务系统虽然查缓存,但缓存中没数据,导致再次去查存储系统。
常见原因1:数据确实不存在。注意点:Null值查询导致每次都去查存储系统,解决方法:缓存中对Null值设置默认值。
常见原因2:缓存生成耗费较长时间,在缓存失效这段时间内,发生缓存穿透
概念:缓存失效,对存储系统造成巨大压力,导致系统崩溃
解决方案:后台更新机制
概念:“特别”热点的数据,导致大部分请求命中同一份缓存数据,造成缓存服务器压力过大
解决方案:复制多分缓存副本,将请求分散到多个缓存服务器上。注意点:缓存副本不要设置统一的过期时间,否则导致缓存雪崩。
“程序代码实现”的中间层方式 或者 独立的中间件
单服务器高性能关键之一:服务器采取的并发模型。
并发模型两个关键设计点:服务器如何管理连接、服务器如何处理请求。这两个设计点与操作系统的IO模型和进程模式相关。
IO模型:阻塞、非阻塞、同步、异步。
进程模型:单进程、多进程、多线程。
参考《UNIX网络编程(三卷本)》
PPC:Process Per Connection*(一个连接一个进程)
TPC:Thread Per Connection(一个链接一个线程)
优点都是实现简单,缺点是都无法支撑高并发的场景
单服务器高性能模式:Reactor与Proactor
IO多路复用
如何理解“IO多路复用”?
IO多路复用的产生背景是:对于每个socket需要新建一个进程(或线程),太浪费了!于是用一个进程来管理多个client socket,复用进程,以节省资源。
IO多路:指的是多个网络连接(IO线路),其实就是server端的多个socket(与client socket进行IO通信的)。
复用:复用的是同一个进程(或线程)。
IO多路复用实现方式:select、poll、epoll
select是不管socket是否活跃,都要去遍历全部socket,询问是否有读写事件发生;epoll是通过事件驱动,当socket有读写事件时,会通知触发回调。所以,epoll更高效。
epoll中的e对应的英文单词就是enhancement
Reactor
IO多路复用
高性能集群的复杂性体现在需要增加一个负载均衡器及选择一个合适的负载均衡算法。
负载均衡分类
DNS负载均衡、硬件负载均衡、软件负载均衡
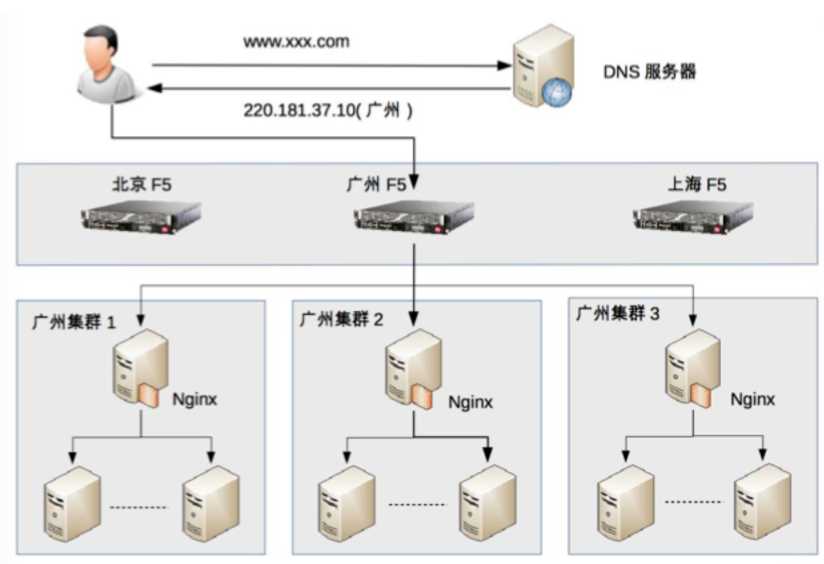
DNS负载均衡本质是DNS解析同一个域名可以返回不同IP地址,常用来实现地理级别的均衡。
如北方用户访问北京机房、南方用户访问深圳机房。同样是www.baidu.com,不同地区用户返回的ip地址不同。
缺点:
更新不及时:因DNS缓存的存在。
扩展性差:DNS负载均衡控制权在域名商那里
负载均衡策略较简单:算法少,不能区分服务器配置差异。
典型硬件负载均衡设备:F5和A10。
优点:
功能强大、性能强大、稳定性高、支持安全防护。
缺点:
价格昂贵
扩展能力差:可根据业务配置,无法进行扩展和定制
常见的有Nginx和LVS。
Nginx是7层负载均衡,LVS是Linux内核的4层负载均衡。
3种负载均衡可以组合使用。组合原则为:DNS负载均衡用于实现地理级别的负载均衡;硬件负载均衡用于实现集群级别的负载均衡;软件负载均衡用于实现机器级别的负载均衡。
负载均衡算法较多,大致可分为以下几类:
任务平分类:数量平均,或按权重平均
轮询
加权轮询
负载均衡类:根据服务器负载进行分配,连接数、IO使用率等
性能最优类:优先将新任务分配给响应最快的服务器
Hash类:常见的有源地址hash,session id hash
标签:code 路由表 编程 img 引擎 pen 开始 大数 深圳
原文地址:https://www.cnblogs.com/yeyang/p/12578654.html