标签:冗余备份 没有 github zook 历史 特点 范围 keepalive 监控
“架构”到底指什么?
涉及到的关键概念分析:
|
区别与联系 | |
|---|---|
|
系统与子系统 |
系统 系统泛指由一群有关联的个体组成,根据某种规则运作,能完成个别元件不能单独完成的工作的群体。 关键点:关联、规则、能力
子系统 |
|
模块与组件 |
举例:学生信息管理系统。从逻辑角度拆分,分为“登录注册模块”、“个人信息模块”、“个人成绩模块”。从物理角度拆分,可分为Nginx、WebServer、MySQL |
|
框架与架构 |
|
重新定义架构:
架构:软件架构指软件系统的顶层架构。
20 世纪 60 年代第一次软件危机引出了“结构化编程”,创造了“模块”概念;20 世纪 80 年代第二次软件危机引出了“面向对象编程”,创造了“对象”概念;到了 20 世纪 90年代“软件架构”开始流行,创造了“组件”概念。我们可以看到,“模块”“对象”“组件”本质上都是对达到一定规模的软件进行拆分,差别只是在于随着软件的复杂度不断增加,拆分的粒度越来越粗,拆分的层次越来越高。
架构设计的目的:架构设计的主要目的是为了解决软件系统复杂度带来的问题
单机如何高性能?多进程、多线程、进程间通信、多线程并发
如何选择?Nginx可以多进程也可多线程、Redis采用单进程、Memchache采用多线程,都实现了高性能
多台机器配合达到高性能的方式有
任务分配:(业务比较简单的情况)每台机器都可以处理完整的业务,不同任务分配到不同机器上执行
任务分解:(业务很复杂)将复杂的业务系统,拆分为多个简单但需要配合的业务系统
高可用方案本质都是通过“冗余”实现高可用
一台不够两台
一个机房可能断点,那就两个机房
一台通道可能故障,那就两条,两条不够就三条(移动、联通、电信)
高性能与高可用的区别
高可用的“冗余”解决方案,单纯从形式上来看,和之前讲的高性能是一样的,都是通过增加更多机器来达到目的,但其实本质上是有根本区别的:高性能增加机器目的在于“扩展”处理性能;高可用增加机器目的在于“冗余”处理单元。
特点:无论从哪台机器上进行计算,同样的算法和输入,产出都是一样的。
复杂度分析举例:双机架构
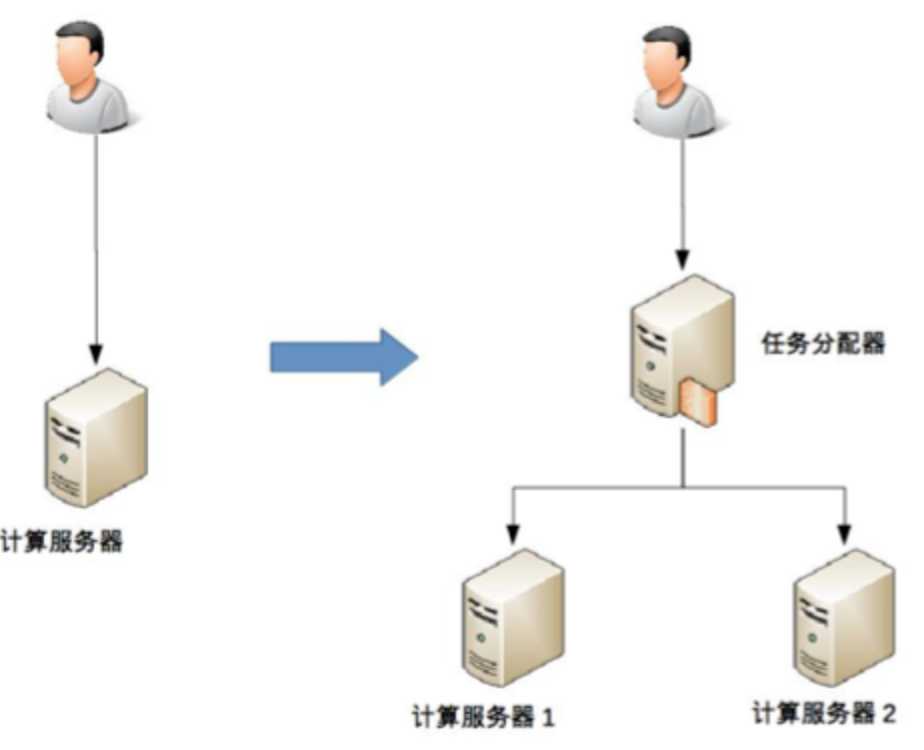
1)任务分配器的选择,性能、成本、可维护性、可用性等因素
2)任务分配器和计算服务器交互。什么连接方式、如何进行连接管理(连接建立、连接检测、连接中断处理)
3)任务分配器的分配算法。双机算法:主备(冷备、温备、热备)、主主。
存储与计算相比的本质区别:将数据从一台机器搬到另一台机器,需要经过线路进行传输。
传输带来的问题:数据的不一致
1)传输时延:同机房几毫秒、不同地方的机房几十甚至上百毫秒(广州到北京)
2)传输链路可用性:传输中断、阻塞、丢包、错包,光缆被挖断
存储高可用的难点:如何减少或规避数据不一致对业务的影响
无论计算高可用还是存储高可用,基础都是“状态决策”,即系统需要能够判断当前的状态是正常还是异常,出现了异常就要采取行动保证高可用。
矛盾点:通过冗余实现的高可用,状态决策本质上都不可能完美,都会有问题点。
常见决策方式
一个“决策者”,其他为“上报者”。“决策者”收集信息进行决策,“上报者”将状态信息发送给决策者。
问题点:因为只有一个决策者,当决策者异常,整个系统无法进行决策
两个个体进行交流,进行决策。常用协商式决策是主备决策。两台机器,一个主机,一个备机。
问题点:两个机器信息交换出现问题(如主备之间连接中断),如何做决策?主备之间连接中断。备机认为主机故障了,升级为主机,导致出现了两个主机;备机认为主机没故障,但主机确实故障了,导致没有主机了。
多个个体投票进行决策。常见的Zookeeper集群选举Leader。
问题点:脑裂
一般通过“投票数必须超过总结点数一半”解决脑裂问题。据CAP理论,但会降低系统可用性。
课后思考题:高性能和高可用是很多系统的核心复杂度,你认为哪个更复杂一些?理由是什么?
精彩评论1:
高可用
为什么会出现不可用?
硬件故障。如服务器宕机。
软件故障。如软件bug。
不可抗力。如地震、洪水、战争。
高可用的复杂度体现
状态监控、服务切换、服务恢复
如何做到高可用?
硬件故障引起的不可用解决方法:
(1)应用服务器:多台机器,负载均衡检测服务器不可用时,将其从集群中摘除。前提(无状态设计):服务需要设计为无状态的,即不保存业务的上下文信息,而仅根据每次请求提交的数据进行业务逻辑的响应。
(2)数据服务器:数据冗余备份
软件故障引起的不可用解决方法:通过软件开发过程进行质量保证。如测试、灰度发布
精彩评论2:
高性能非必须做。不管通过什么方式,或多或少,性能总能提高。高可用必须做。系统宕机或数据丢失,谈高性能没有意义。
精彩评论3:
高可用的解决方法不是解决,而是减少或者规避,而规避某个问题的时候,一般都会引发另一个问题,只是这个问题比之前的小,高可用的设计过程其实也是一个取舍的过程。这也就是为什么系统可用性永远只是说几个九,永远缺少那个一。而高性能,这个基本上就是定义计算能力,可以通过架构的优化,算法的改进,硬件的升级都可以得到很好的解决,从而达到我们心里对性能的预期…
精彩评论4:
高性能虽然复杂,但是只要通过合理的集群方案还是可以解决业务的性能需求,但是高可用也只能做到相对高可用,绝对高可用是不存在的,总会有诸多突发外界因素进行干扰,高性能的实现是受人为控制的,只要是在人的控制范围内,那问题都不是问题,但是要做到高可用,很多事情都不是人能控制的,比如天灾人祸
精彩评论5:
古人有言:先解决有无,再解决优化。所以可用更难,性能次之
设计具备良好可扩展性的系统,有两个基本条件:正确预测变化、完美封装变化
1)预测变化的复杂性
不是每个设计点都考虑可扩展性
不能完全不考虑可扩展性
所有的预测都存在出错的可能性
2)应对变化
常见方案1:将“变化”封装在“变化层”,将不变的部分封装在“稳定层”。
复杂性
1)需要拆分出变化层和稳定层,但是对于哪些属于变化层、哪些属于稳定层,并不好分辨
2)需要设计变化层和稳定层之间的接口
常见方案2:提炼出一个“抽象层”和一个“实现层”。
典型案例:设计模式、规则引擎。
规模:典型案例就是关系型数据库存储数据,需要进行分库分表。
软件架构图如何画?4+1视图。http://hongyitong.github.io/2017/02/17/4+1%E8%A7%86%E5%9B%BE%E5%88%86%E6%9E%90/
合适原则:“合适优于业界领先”
简单原则:“简单优于复杂”(KISS原则:Keep it simple,stupid!)
简单的方案和复杂的方案都能满足要求,最好选择简单的方案。
演化原则:“演化优于一步到位”
软件架构需要根据业务的发展不断变化。
分析了淘宝和手机QQ的发展历程
将主要的复杂度问题列出来,优先解决当前面临的最主要的复杂度问题
举例:是否需要高性能、是否需要高可用、是否需要高可扩展性。按优先级排序,前面的优先解决。
需注意的是:业务阶段不同,复杂度问题的优先级可能不同。
注意事项
备选方案的数据以3-5个为最佳。
备选方案之间的差异要比较明显。
主备方案VS集群方案,zookeeper做主备决策VS用keepalived做主备决策。
备选方案的技术不要只局限于已经熟悉的技术。
备选方案不要过于详细。备选阶段关注的是技术选型,而不是技术细节。
几种常见的设计误区。
1)设计最优秀的方案(技术人的技术情结,方案中的技术越牛逼越好)。而是要根据“合适”、“简单”、“演进”的架构设计原则,决策出与需求、团队、技术能力相匹配的合适方案。
2)只做一个方案。一个方案容易陷入思考问题片面、自我坚持的认知陷阱。
几种流派
最简派。挑选最简单的方案。
最牛派。挑选最牛逼的方案。
最熟派。挑选最熟悉的方案。
对上面几种流派的看法:
并无绝对正确和错误,关键是不同场景采取不同方式。即有时最简,有时最牛,有时最熟。
如何选出最终方案?
1)列出需要关注的质量属性点,然后分别从这些质量属性的维度去评估每个方案。常见的质量属性点:性能、可用性、扩展性、安全性、硬件成本、项目投入(时间、人力)、复杂度、可维护性、运维难度
2)根据当前业务发展情况、团队规模和技能、业务发展预测等因素,将质量属性按优先级排序,首先挑选满足高优先级的。
实战案例
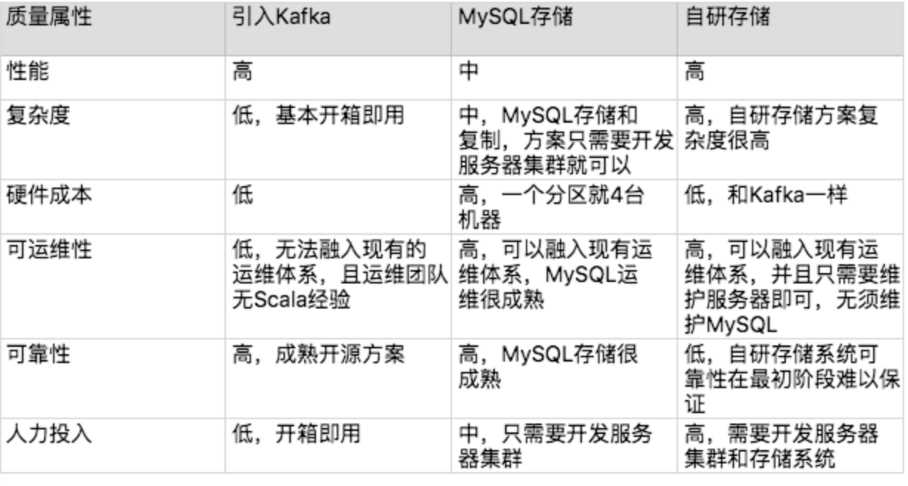
就是将方案设计到的关键技术细节给确定下来
如确定使用MySQL分库分表,那就需要确定哪些表要分库分表、按什么维度分库分表、分库分表后联合查询怎么处理。
可能遇到的问题是在详细设计阶段发现备选方案不可行,一般原因是备选方案设计时遗漏了关键技术点或关键质量属性。
架构师不但要进行备选方案设计和选型,还需要对备选方案的关键细节有较深入理解。
标签:冗余备份 没有 github zook 历史 特点 范围 keepalive 监控
原文地址:https://www.cnblogs.com/yeyang/p/12578624.html