标签:数据 span 评价 port 类别 panda user soft component
sklearn PAI:from sklearn.cluster import KMeans
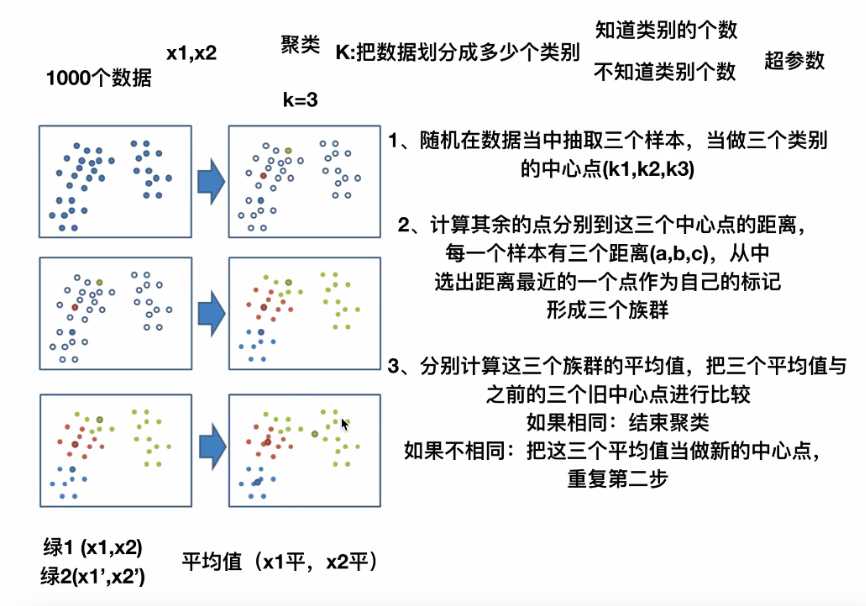
聚类的原理
评价指标:轮廓系数,一般[-1,1]之间,一般超过0-0.1聚类效果已经十分不错

from sklearn.cluster import KMeans # K-means PAI import pandas as pd from sklearn.decomposition import PCA import matplotlib.pyplot as plt from sklearn.metrics import silhouette_score # 轮廓系数API # 数据地址:https://www.kaggle.com/c/instacart-market-basket-analysis/data # 读取表 prior = pd.read_csv(r"E:\360Downloads\Software\降维案列数据\order_products__prior.csv") products = pd.read_csv(r"E:\360Downloads\Software\降维案列数据\products.csv") order = pd.read_csv(r"E:\360Downloads\Software\降维案列数据\order.csv") aisles = pd.read_csv(r"E:\360Downloads\Software\降维案列数据\aisles.csv") # 合并表,prodyct_id按该列合并 _mg = pd.merge(prior, products, on=[‘prodyct_id‘, ‘product_id‘]) _mg = pd.merge(_mg, order, on=[‘order_id‘, ‘order_id‘]) mt = pd.merge(_mg, aisles, on=[‘aisle_id‘, ‘aisle_id‘]) # 使用交叉表,构造用户-购买商品类别表 cross = pd.crosstab(mt[‘user_id‘], mt[‘aisle‘]) # 进行主成分分析,将冗余的商品类别过滤掉,即将少量或者几乎没有人购买的商品类别过滤掉 pca = PCA(n_components=0.9) data = pca.fit_transform(cross) data = data[0:500,:] # n_clusters 开始聚类中心的数量,init初始化方法,默认k-means++ km = KMeans(n_clusters=4) km.fit(data) predict = km.predict(data) plt.figure(figsize=(10, 10)) colored = [‘orange‘, ‘green‘, ‘blue‘, ‘purple‘] colr = [colored[i] for i in predict] plt.scatter(data[:,1], data[:,20], color = colr) plt.xlabel("1") plt.ylabel(‘20‘) plt.show() # 聚类的评价:轮廓系数在[-1,1]之间,一般超过0-0.1聚类效果已经十分不错 # 第一个参数特征值,第二个参数被聚类标记的目标值 print(silhouette_score(data, predict))
标签:数据 span 评价 port 类别 panda user soft component
原文地址:https://www.cnblogs.com/kogmaw/p/12580536.html