标签:tps transform 单词 adbc 模版 重要 res 输出 处理
老板:3000字原创文章,明天上午10点要。
我:嗯?
老板:嗯?
我:嗯!
套话文章不会写?狗屁不通文章生成器分分钟写出一万字,保证原创、绝不重样!
(https://github.com/menzi11/BullshitGenerator)
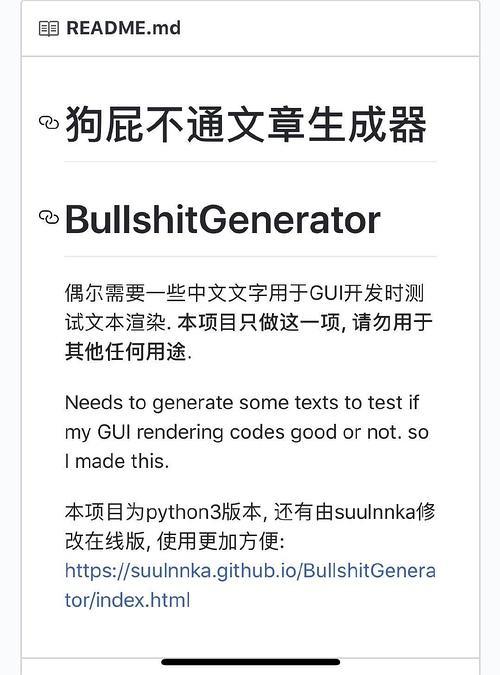
虽然的确是用 Python 写的,遗憾的是它只是简单的循环随机内容选取脚本。
文章会从名人名言开始,接上没有实际意义的承接句,然后是点题句,再来个同样没有意义的转折句。然后再接名人名言、承接句、点题句……周而复始生生不息。

设置语句库,按顺序从中随机选取语句,再将它们组合起来。原理并不难,难得的是作者对套话文章的揣摩和创意。
目前让机器写作,即自动文本生成,通常采用统计方法。先用大量语料训练神经网络,再让机器根据关键词不断预测接下来的词语,最后组成句子和段落。
这样生成的文本难免有逻辑错误、无中生有等问题,效果甚至不如僵硬的模版文本生成方法。
由于NLP 领域中只有小部分标注过的数据,而有大量的数据是未标注,如果只用标注数据将会大大影响深度学习的性能,所以为了充分利用大量未标注的原始文本数据,需要利用无监督学习来从文本中提取特征。
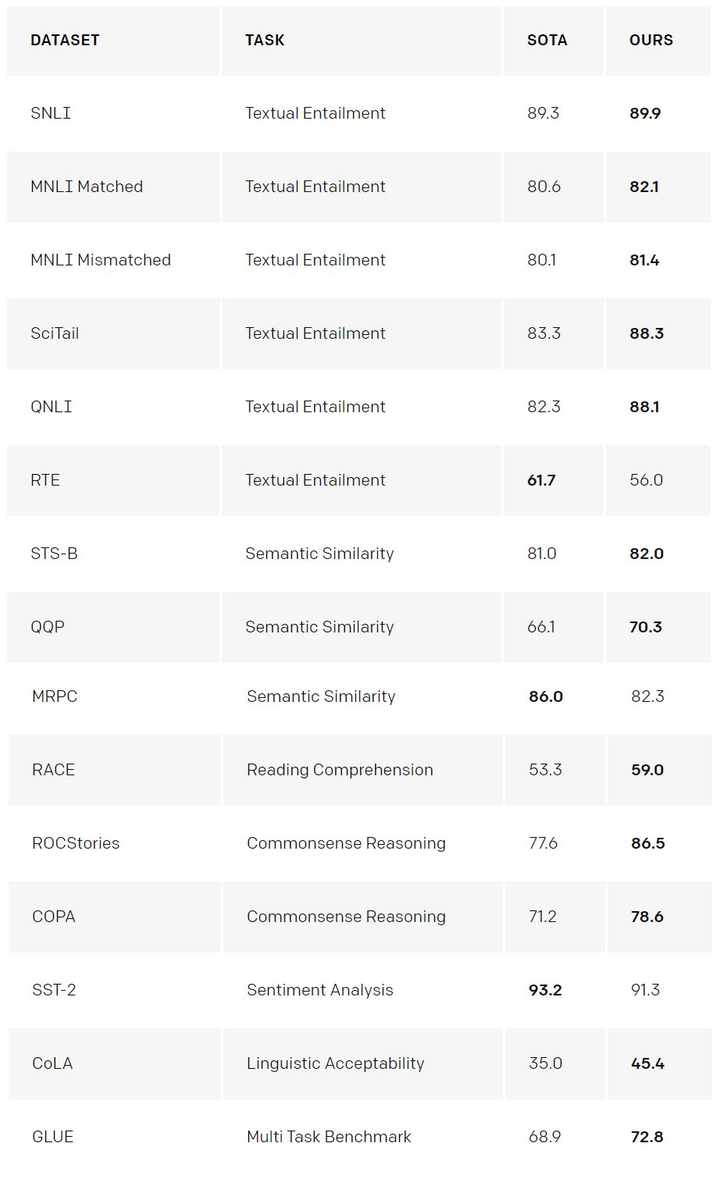
为了解决以上问题,2019 年OpenAI发表了论文《Language Models are Unsupervised Multitask Learners》,作者提出了 GPT 框架。
用一种半监督学习的方法来完成语言理解任务,GPT 的训练过程分为两个阶段:
用无监督学习的 Pre-training, 充分利用大量未标注的文本数据;用监督学习的 Fine-tuning 来适配具体的具体的 NLP 任务(如机器翻译),并在 12 个 NLP 任务中刷新了 9 个记录。
GPT-2,其模型结构与 GPT 相比几乎没有什么变化,只是让模型变得更大更宽,并且取消了 Fine-tuning 的步骤。也就是说 GPT-2 采用了一阶段的模型(预训练)代替了二阶段的模型(预训练+微调),并且在语言模型(文本摘要等)相关领域取得了不错的效果。
GPT-2能生成质量相当不错的英文文本,原因是数据集——它的训练语料是 800 万 Reddit 网友的高质量回复。面对 Reddit 讨论很多的主题,它能给出相当不错的输出。
GPT-2 采用的 Transformer 的 Decoder 模块堆叠而成,而 BERT 采用的是 Transformer 的 Encoder 模块构建的。两者一个很关键的区别在于,GPT-2 采用的是传统的语言模型,一次只输出一个单词(多个 token)。
下图是一个训练好的模型来 “背诵” 机器人第一法则:
这种效果之所以好是因为采用了自回归机制(Auto-Regression):每生成一个新单词,该单词就被添加在生成的单词序列后面,这个序列会成为下一步的新输入。这个也是 RNN 的重要思想。
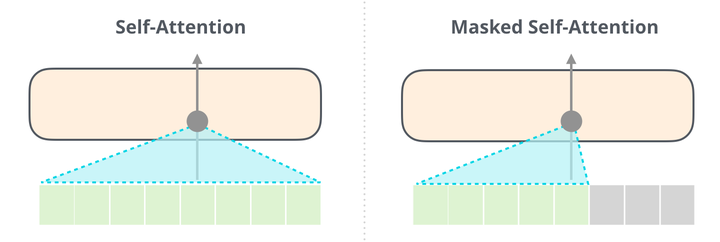
而 BERT 采用的是双向语言模型,虽然没有自回归,但也因为获得了结合上下文单词信息的能力,从而也取得了不错的效果。下图展示了 BERT 的 Self-Attention(左)和 GPT-2 的 Masked Self-Attention(右)的区别:
放一个 GPT-2 和 ELMo、Bert 的参数对比图:

自然语言处理无非是目前最大的风口,从Word2Vec、ElMo、GPT、Bert,ALBERT到XLNet, 我们见证了这个领域的高速发展以及未来的前景。互联网中大量的文本以及IOT时代赋予我们的全新交互带来了这个领域的爆发。
那怎么来学习上边提到的这些知识点呢?
美国南加州大学博士,人工智能、知识图谱领域专家。前凡普金科集团(爱钱进) 的首席数据科学家、美国亚马逊和高盛的高级工程师,负责过金融知识图谱、聊天机器人、量化交易、自适应教育系统等核心项目的李文哲先生设计了对标MIT人工智能博士学位的学习路线。
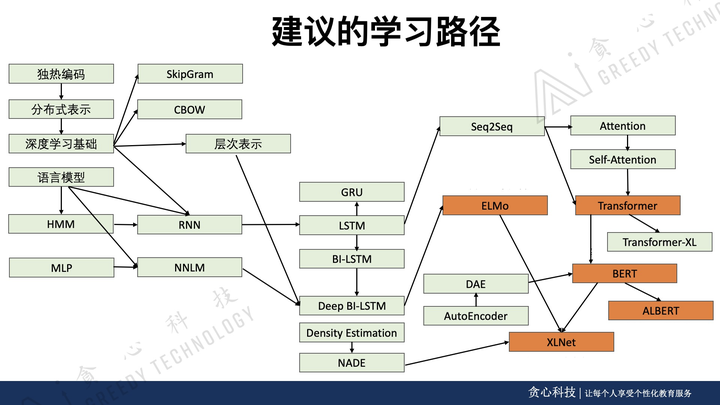
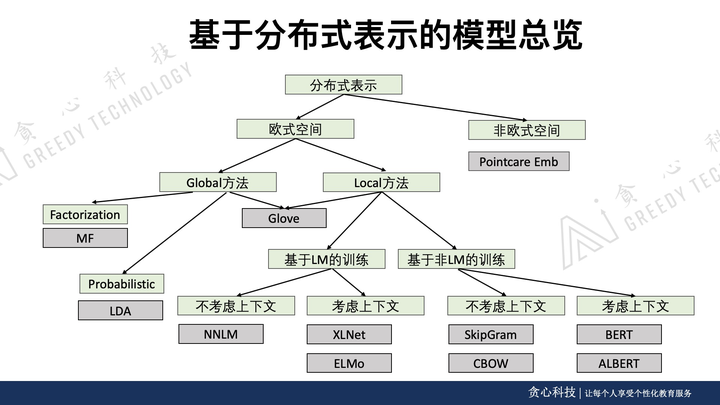
以上是部分需要学习的知识点,李文哲先生还亲自研发了对应的《高阶NLP课程》,并且写了配套的书籍教程。
如果你对这门课程感兴趣,可以加我了解:
如果你对这门课程感兴趣,可以加我了解:
如果这门课程能帮到你,你可以加我了解:
标签:tps transform 单词 adbc 模版 重要 res 输出 处理
原文地址:https://www.cnblogs.com/txkjai/p/12580426.html