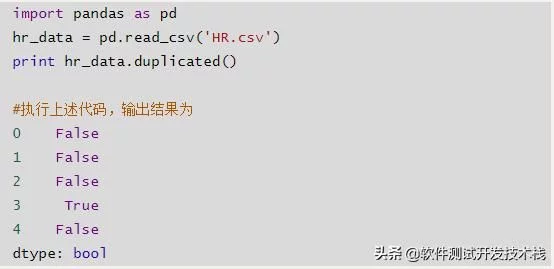
- df.duplicated() :判断各行是重复,False为非重复值。
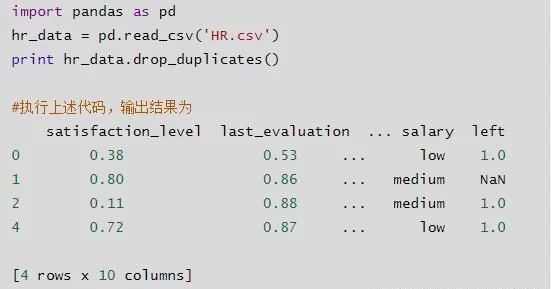
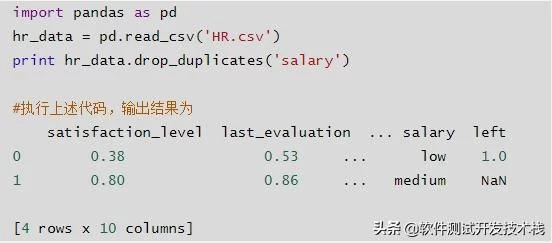
- df.drop_duplicates():删除重复行
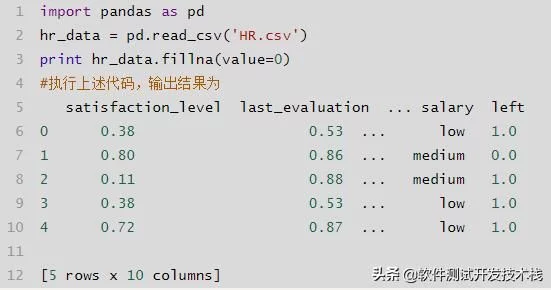
- df.fillna(0):用实数0填充na
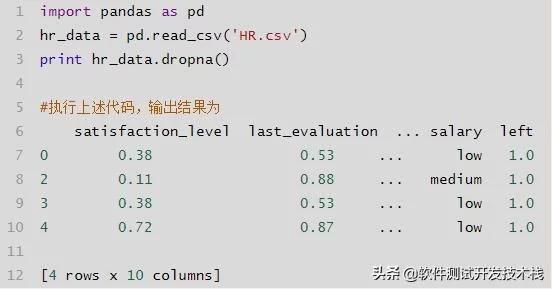
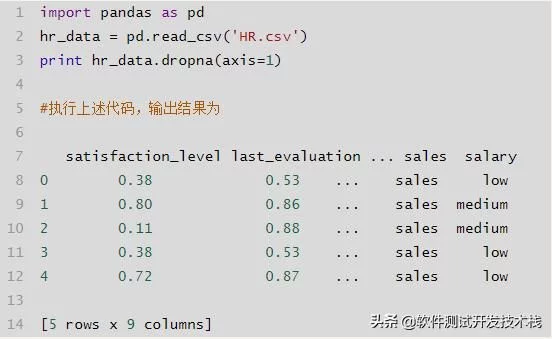
- df.dropna():按行删除缺失数据,使用参数axis=0;按列删除缺失值,使用参数axis=1,how = "all" 全部是NA才删,"any"只要有NA就删除
- del df[‘col1‘]:直接删除某列
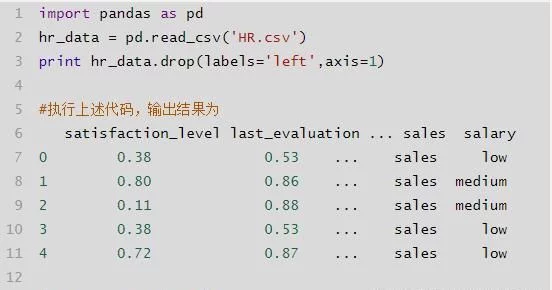
- df.drop([]‘col1‘,……],axis=1):删除指定列,也可以删除指定行
- df.rename(index={‘row1‘:‘A‘},columns ={‘col1‘:‘B‘}):重命名索引名和列名
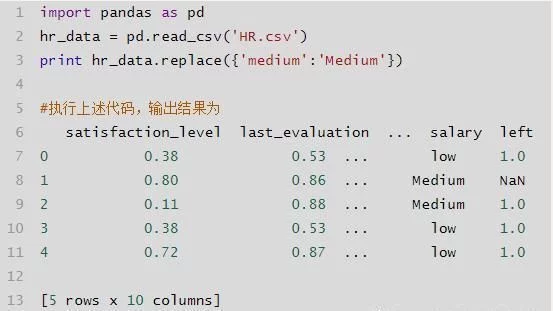
- df.replace():替换df值,前后值可以用字典表,{‘1‘:‘A‘,‘2:‘B‘}
- hr_data[‘col1‘].map(function):Series.map,对指定列进行函数转换
- pd.merge(df1,df2,on=‘col1‘,how=‘inner‘,sort=True):合并两个df,按照共有的列作内连接(交集),outter为外连接(并集),结果排序。
- pd.concat([df1,df2]):多个Series堆叠成多行。
- df1.combine_first(df2):用df2的数据补充df1的缺失值NAN。