标签:text 改变 amp 评分 tar each 数据 书籍 inf
豆瓣电影top250url:https://movie.douban.com/top250?start=0&filter=
首先f12进入检查CTRL +shift +c定位到标题
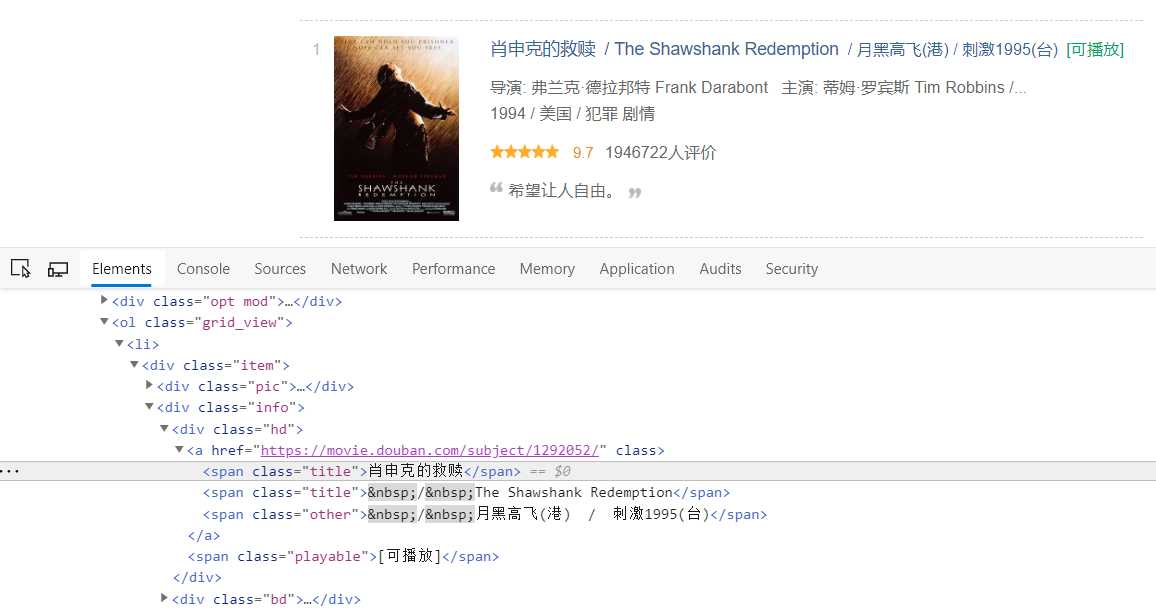
可以看到电影标题在<a>标签下,所以我们只要定位到a标签下就可以了,我们找到<a>标签的最上一级标签<div>标签属性class=item,好了现在我们大概有了思路了,现在让我来写代码吧
第一步:设置请求头headers
headers = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36 Edg/80.0.361.69‘}
然后我们发送get请求,并用BeautifulSoup解析
1 html = requests.get(url,headers=headers) 2 soup = BeautifulSoup(html.text,‘lxml‘)
这了我们用BeautifulSoup的select方法
movies = soup.select(‘.item‘)
这样我们就定位到了div标签,我们创建一个迭代对象一步一步向下定位,定位到我们需要的内容
1 for movie in movies: 2 movie_name = movie.select_one(‘div.info a‘).text.strip().replace(‘ ‘,‘‘).replace(‘\n‘,‘‘) 3 movie_star = movie.select_one(‘div.star‘).text.strip() 4 movie_quote = movie.select_one(‘p.quote‘).text.strip() 5 print(movie_name,movie_star[0:3]) 6 print(movie_quote,‘\n‘,‘-‘*80)
其实现在代码已经可以运行了,但是我们只能获取到第一页的内容,如果我们想自动翻页获取怎么办呢
我们点击第二页,查看第二页的url:https://movie.douban.com/top250?start=25&filter=,查看第三页url:https://movie.douban.com/top250?start=50&filter=我们可以发现一个规律
就是翻页其实只带来了url中start=_x_这个数字的改变,所以我们只要写一个for循环每次改变这个数字就可以实现url的改变
现在我们运行代码数据被成功的被爬取了下来
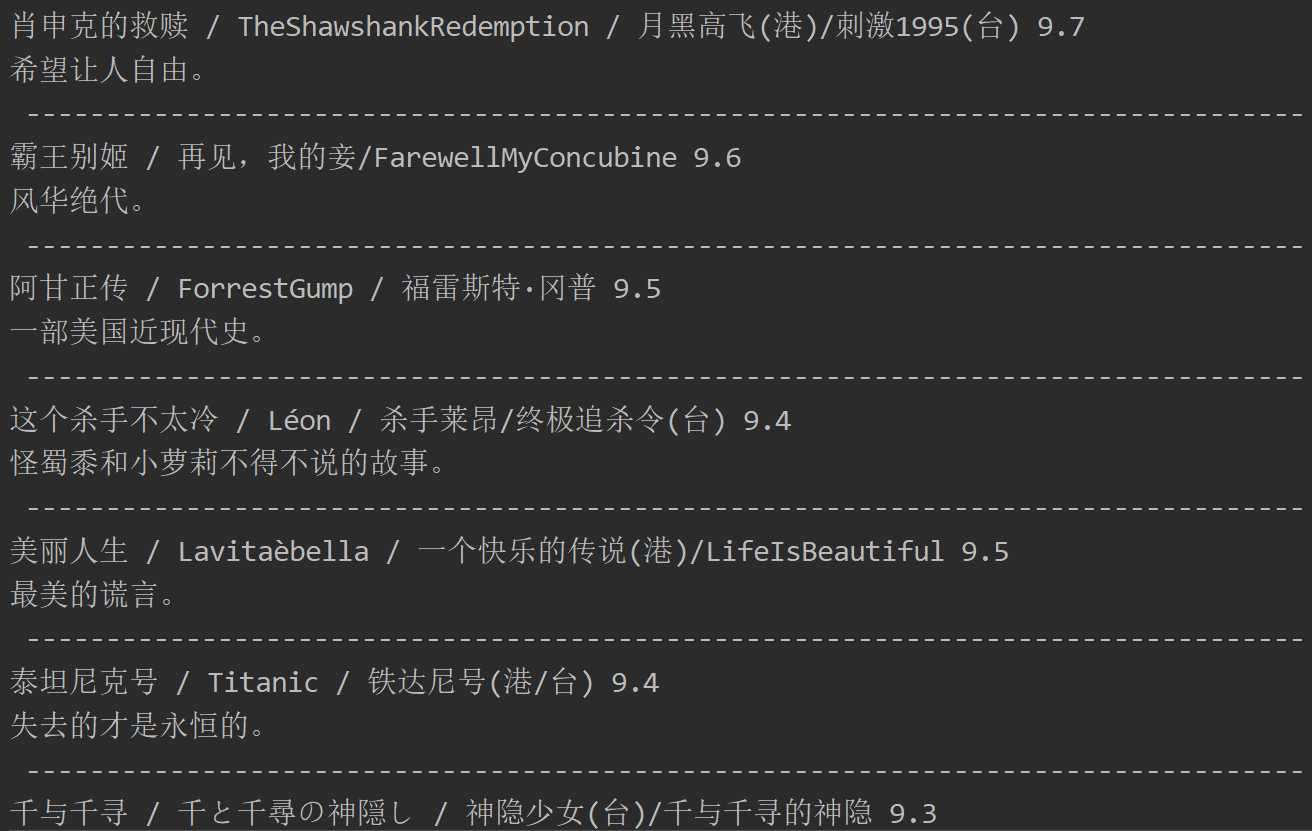
完整代码如下:
1 import requests 2 from bs4 import BeautifulSoup 3 4 def get_movies(url): 5 headers = {‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36 Edg/80.0.361.69‘} 6 html = requests.get(url,headers=headers) 7 soup = BeautifulSoup(html.text,‘lxml‘) 8 movies = soup.select(‘.item‘) 9 for movie in movies: 10 movie_name = movie.select_one(‘div.info a‘).text.strip().replace(‘ ‘,‘‘).replace(‘\n‘,‘‘) 11 movie_star = movie.select_one(‘div.star‘).text.strip() 12 movie_quote = movie.select_one(‘p.quote‘).text.strip() 13 print(movie_name,movie_star[0:3]) 14 print(movie_quote,‘\n‘,‘-‘*80) 15 16 if __name__ == ‘__main__‘: 17 for each in range(0,100,25): 18 url = ‘https://movie.douban.com/top250?start={}&filter=‘.format(each) 19 get_movies(url)
当我们会爬取豆瓣电影后其他的类似网站我们同样可以爬取:这里我们再把豆瓣书籍爬取一边:
爬取豆瓣读书的完整代码如下:
方法和上面是一样的,先用get请求获取网页源码,再用BeautifulSoup解析,然后用select方法迭代
1 import requests,time 2 from bs4 import BeautifulSoup 3 from urllib import parse 4 headers = { 5 ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36 Edg/80.0.361.69‘ 6 } 7 def get_html(url): 8 html = requests.get(url,headers=headers) 9 soup = BeautifulSoup(html.text,‘lxml‘) 10 books = soup.select(‘li.subject-item‘) 11 for book in books: 12 title = book.select_one(‘div.info h2 a‘).text.strip().replace(‘\n‘,‘‘).replace(‘ ‘,‘‘) 13 pub = book.select_one(‘div.pub‘).text.strip().replace(‘\n‘,‘‘) 14 shuping = book.select_one(‘p‘).text 15 ratingnum = book.select_one(‘.rating_nums‘).text 16 print(‘《‘,title,‘》‘,pub,"评分",ratingnum,"分") 17 print(shuping) 18 print(‘-‘*80) 19 20 21 if __name__ == ‘__main__‘: 22 for each in range(0,100,20): 23 url = ‘https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4?start={}&type=T‘.format(each) 24 print(‘正在爬取第{}‘.format((each//20+1))) 25 get_html(url)
标签:text 改变 amp 评分 tar each 数据 书籍 inf
原文地址:https://www.cnblogs.com/Truedragon/p/12584315.html