标签:文本 log head 逻辑 img arch 脚本 schema clu
参考地址
1、http://www.ruanyifeng.com/blog/2017/08/elasticsearch.html
2、https://www.cnblogs.com/smartloli/p/6978645.html
3、http://www.infoq.com/cn/articles/apache-kafka
Elastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。
单个 Elastic 实例称为一个节点(node)。一组节点构成一个集群(cluster)。
Elastic 会索引所有字段,经过处理后写入一个反向索引(Inverted Index)。查找数据的时候,直接查找该索引。
所以,Elastic 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
Index 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。相当于关系数据库表中的一个记录。
Document 可以分组,比如weather这个 Index 里面,可以按城市分组(北京和上海),也可以按气候分组(晴天和雨天)。这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document。相当于关系数据库中的一个表。
不同的 Type 应该有相似的结构(schema),举例来说,id字段不能在这个组是字符串,在另一个组是数值。这是与关系型数据库的表的一个区别。性质完全不同的数据(比如products和logs)应该存成两个 Index,而不是一个 Index 里面的两个 Type(虽然可以做到)。
根据规划,Elastic 6.x 版只允许每个 Index 包含一个 Type,7.x 版将会彻底移除 Type。
映射(Mapping)
ES中,所有的文档在存储之前都要首先进行分析。用户可根据需要定义如何将文本分割成token、哪些token应该被过滤掉,以及哪些文本需要进行额外处理等等。
分片(Shard)和副本(Replica)
ES的“分片(shard)”机制可将一个索引内部的数据分布地存储于多个节点,它通过将一个索引切分为多个底层物理的Lucene索引完成索引数据的分割存储功能,这每一个物理的Lucene索引称为一个分片(shard)。
每个分片其内部都是一个全功能且独立的索引,因此可由集群中的任何主机存储。创建索引时,用户可指定其分片的数量,默认数量为5个。
Shard有两种类型:primary和replica,即主shard及副本shard。
Primary shard用于文档存储,每个新的索引会自动创建5个Primary shard,当然此数量可在索引创建之前通过配置自行定义,不过,一旦创建完成,其Primary shard的数量将不可更改。
Replica shard是Primary Shard的副本,用于冗余数据及提高搜索性能。
每个Primary shard默认配置了一个Replica shard,但也可以配置多个,且其数量可动态更改。ES会根据需要自动增加或减少这些Replica shard的数量。
ES集群可由多个节点组成,各Shard分布式地存储于这些节点上。
ES可自动在节点间按需要移动shard,例如增加节点或节点故障时。简而言之,分片实现了集群的分布式存储,而副本实现了其分布式处理及冗余功能。
ElasticSearch在设计上支持插件式体系结构,用户可根据需要通过插件来增强ElasticSearch的功能。
目前,常用的通过插件扩展的功能包括添加自定义映射类型、自定义分析器、本地脚本、自定义发现方式等等。
安装及移除插件
插件的安装有两种方式:直接将插件放置于plugins目录中,或通过plugin脚本进行安装。
Marvel、BigDesk及Head这三个是较为常用的插件。
ElasticSearch提供了易用但功能强大的RESTful API以用于与集群进行交互,这些API大体可分为如下四类:
(1) 检查集群、节点、索引等健康与否,以及获取其相关状态与统计信息;
(2) 管理集群、节点、索引数据及元数据;
(3) 执行CRUD操作及搜索操作;
(4) 执行高级搜索操作,例如paging、filtering、scripting、faceting、aggregations及其它操作;
ElasticSearch是有其自己的套件的,简称ELK,即ElasticSearch,Logstash以及Kibana。ElasticSearch负责存储,Logstash负责收集数据来源,Kibana负责可视化数据,分工明确。想要分流Kafka中的消息数据,可以使用Logstash的插件直接消费,但是需要我们编写复杂的过滤条件,和特殊的映射处理,比如系统保留的`_uid`字段等需要我们额外的转化。今天我们使用另外一种方式来处理数据,使用Kafka的消费API和ES的存储API来处理分流数据。通过编写Kafka消费者,消费对应的业务数据,将消费的数据通过ES存储API,通过创建对应的索引的,存储到ES中。其流程如下图所示:
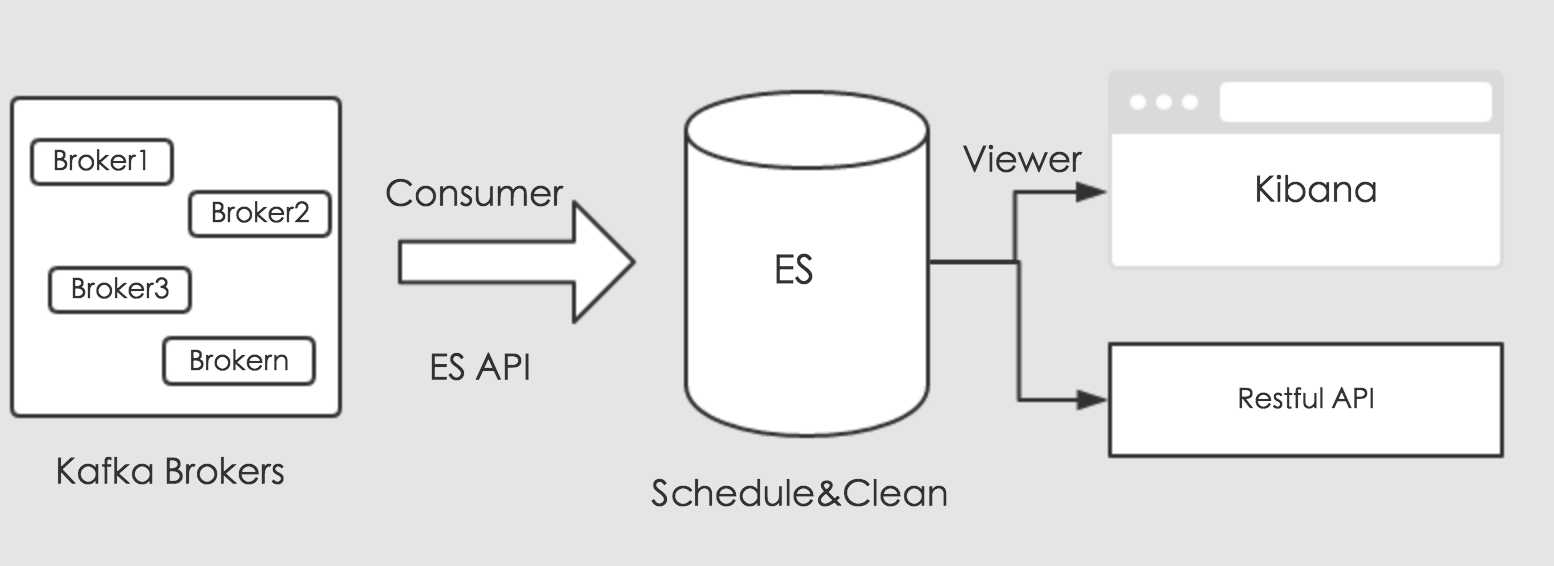
上图可知,消费收集的数据,通过ES提供的存储接口进行存储。存储的数据,这里我们可以规划,做定时调度。最后,我们可以通过Kibana来可视化ES中的数据,对外提供业务调用接口,进行数据共享。
标签:文本 log head 逻辑 img arch 脚本 schema clu
原文地址:https://www.cnblogs.com/suntp/p/8780836.html