标签:color 自然语言 location 自然语言分析 转移 词法 事件 tar input
1.源数据介绍
自然语言分析技术大致分为三个层面:词法分析、句法分析和语义分析。语义角色标注是实现浅层语义分析的一种方式。在一个句子中,谓词是对主语的陈述或说明,指出“做什么”、“是什么”或“怎么样,代表了一个事件的核心,跟谓词搭配的名词称为论元。语义角色是指论元在动词所指事件中担任的角色。主要有:施事者(Agent)、受事者(Patient)、客体(Theme)、经验者(Experiencer)、受益者(Beneficiary)、工具(Instrument)、处所(Location)、目标(Goal)和来源(Source)等。
请看下面的例子,“遇到” 是谓词(Predicate,通常简写为“Pred”),“小明”是施事者(Agent),“小红”是受事者(Patient),“昨天” 是事件发生的时间(Time),“公园”是事情发生的地点(Location)。
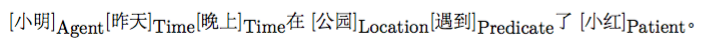
语义角色标注(Semantic Role Labeling,SRL)以句子的谓词为中心,不对句子所包含的语义信息进行深入分析,只分析句子中各成分与谓词之间的关系,即句子的谓词(Predicate)- 论元(Argument)结构,并用语义角色来描述这些结构关系,是许多自然语言理解任务(如信息抽取,篇章分析,深度问答等)的一个重要中间步骤。在研究中一般都假定谓词是给定的,所要做的就是找出给定谓词的各个论元和它们的语义角色。
2.神经网络结构
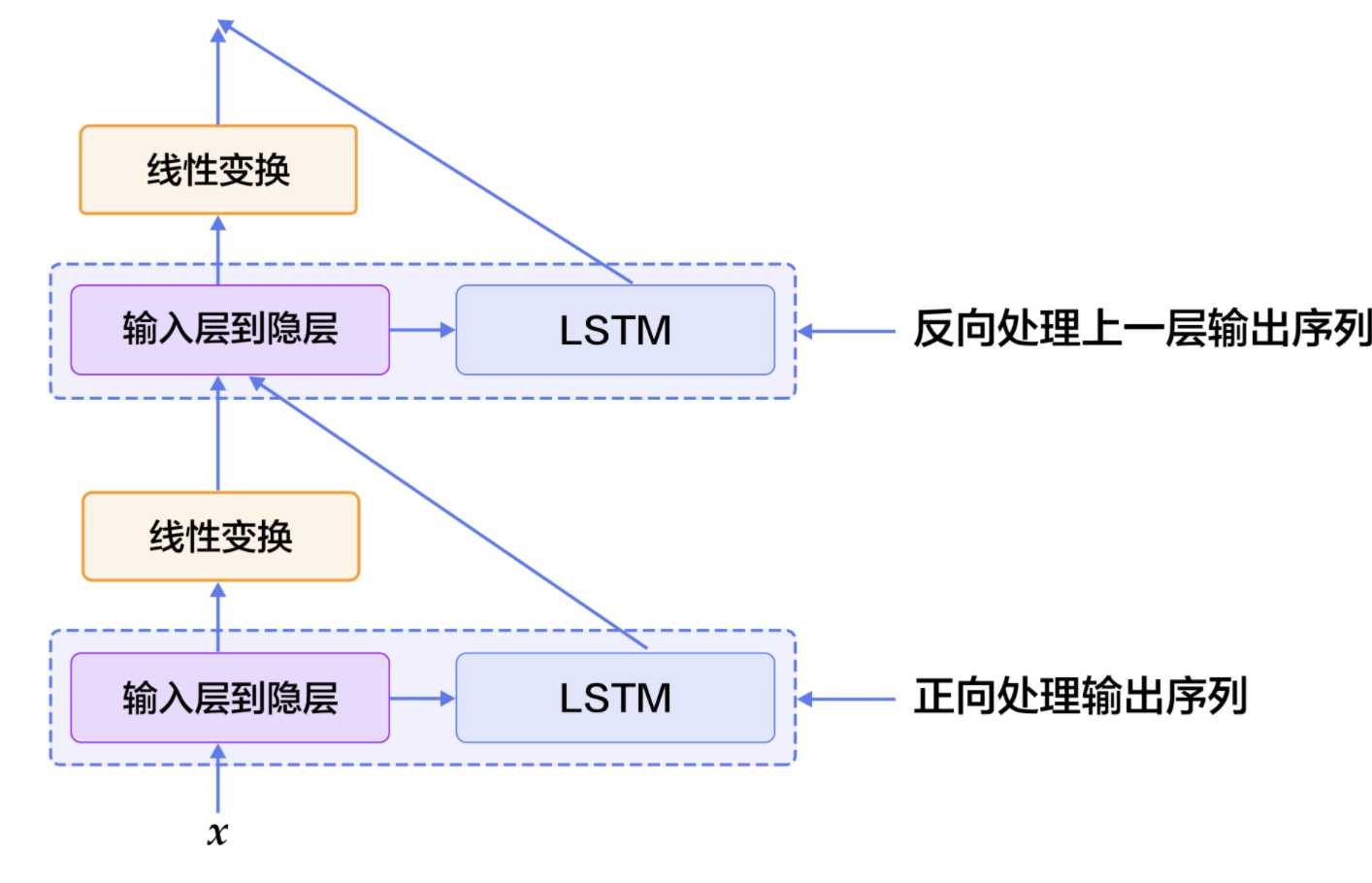
大家可以尝试上面这种方法。这里,我们提出一些改进,引入两个简单但对提高系统性能非常有效的特征:
3.初始化环境
from __future__ import print_function import math, os import numpy as np import paddle import paddle.dataset.conll05 as conll05 import paddle.fluid as fluid import six import time with_gpu = os.getenv(‘WITH_GPU‘, ‘0‘) != ‘0‘ word_dict, verb_dict, label_dict = conll05.get_dict() word_dict_len = len(word_dict) label_dict_len = len(label_dict) pred_dict_len = len(verb_dict) print(‘word_dict_len: ‘, word_dict_len) print(‘label_dict_len: ‘, label_dict_len) print(‘pred_dict_len: ‘, pred_dict_len)
mark_dict_len = 2 # 谓上下文区域标志的维度,是一个0-1 2值特征,因此维度为2
word_dim = 32 # 词向量维度
mark_dim = 5 # 谓词上下文区域通过词表被映射为一个实向量,这个是相邻的维度
hidden_dim = 512 # LSTM隐层向量的维度 : 512 / 4
depth = 8 # 栈式LSTM的深度
mix_hidden_lr = 1e-3 # linear_chain_crf层的基础学习率
IS_SPARSE = True # 是否以稀疏方式更新embedding
PASS_NUM = 10 # 训练轮数
BATCH_SIZE = 10 # batch size 大小
embedding_name = ‘emb‘
2.定义神经网络
use_cuda = False #在cpu上执行训练 save_dirname = "label_semantic_roles.inference.model" #训练得到的模型参数保存在文件中 is_local = True word = fluid.data( name=‘word_data‘, shape=[None, 1], dtype=‘int64‘, lod_level=1) # 谓词 predicate = fluid.data( name=‘verb_data‘, shape=[None, 1], dtype=‘int64‘, lod_level=1) # 谓词上下文5个特征 ctx_n2 = fluid.data( name=‘ctx_n2_data‘, shape=[None, 1], dtype=‘int64‘, lod_level=1) ctx_n1 = fluid.data( name=‘ctx_n1_data‘, shape=[None, 1], dtype=‘int64‘, lod_level=1) ctx_0 = fluid.data( name=‘ctx_0_data‘, shape=[None, 1], dtype=‘int64‘, lod_level=1) ctx_p1 = fluid.data( name=‘ctx_p1_data‘, shape=[None, 1], dtype=‘int64‘, lod_level=1) ctx_p2 = fluid.data( name=‘ctx_p2_data‘, shape=[None, 1], dtype=‘int64‘, lod_level=1) # 谓词上下区域标志 mark = fluid.data(name=‘mark_data‘, shape=[None, 1], dtype=‘int64‘, lod_level=1) predicate_embedding = fluid.embedding( input=predicate, size=[pred_dict_len, word_dim], dtype=‘float32‘, is_sparse=IS_SPARSE, param_attr=‘vemb‘) mark_embedding = fluid.embedding( input=mark, size=[mark_dict_len, mark_dim], dtype=‘float32‘, is_sparse=IS_SPARSE) #句子序列和谓词上下文5个特征并预训练 word_input = [word, ctx_n2, ctx_n1, ctx_0, ctx_p1, ctx_p2] # 因词向量是预训练好的,这里不再训练embedding表, # 参数属性trainable设置成False阻止了embedding表在训练过程中被更新 emb_layers = [ fluid.embedding( size=[word_dict_len, word_dim], input=x, param_attr=fluid.ParamAttr( name=embedding_name, trainable=False)) for x in word_input ] #加入谓词和谓词上下区域标志的预训练结果 emb_layers.append(predicate_embedding) emb_layers.append(mark_embedding) hidden_0_layers = [ fluid.layers.fc(input=emb, size=hidden_dim, act=‘tanh‘) for emb in emb_layers ] hidden_0 = fluid.layers.sums(input=hidden_0_layers) lstm_0 = fluid.layers.dynamic_lstm( input=hidden_0, size=hidden_dim, candidate_activation=‘relu‘, gate_activation=‘sigmoid‘, cell_activation=‘sigmoid‘) # 用直连的边来堆叠L-LSTM、R-LSTM input_tmp = [hidden_0, lstm_0] # 其余的栈结构 for i in range(1, depth): mix_hidden = fluid.layers.sums(input=[ fluid.layers.fc(input=input_tmp[0], size=hidden_dim, act=‘tanh‘), fluid.layers.fc(input=input_tmp[1], size=hidden_dim, act=‘tanh‘) ]) lstm = fluid.layers.dynamic_lstm( input=mix_hidden, size=hidden_dim, candidate_activation=‘relu‘, gate_activation=‘sigmoid‘, cell_activation=‘sigmoid‘, is_reverse=((i % 2) == 1)) input_tmp = [mix_hidden, lstm] # 取最后一个栈式LSTM的输出和这个LSTM单元的输入到隐层映射, # 经过一个全连接层映射到标记字典的维度,来学习 CRF 的状态特征 feature_out = fluid.layers.sums(input=[ fluid.layers.fc(input=input_tmp[0], size=label_dict_len, act=‘tanh‘), fluid.layers.fc(input=input_tmp[1], size=label_dict_len, act=‘tanh‘) ])
3.损失函数
target = fluid.data( name=‘target‘, shape=[None, 1], dtype=‘int64‘, lod_level=1) # 学习 CRF 的转移特征 crf_cost = fluid.layers.linear_chain_crf( input=feature_out, label=target, param_attr=fluid.ParamAttr( name=‘crfw‘, learning_rate=mix_hidden_lr)) avg_cost = fluid.layers.mean(crf_cost) # 使用最基本的SGD优化方法(momentum设置为0) sgd_optimizer = fluid.optimizer.SGD( learning_rate=fluid.layers.exponential_decay( learning_rate=0.01, decay_steps=100000, decay_rate=0.5, staircase=True)) sgd_optimizer.minimize(avg_cost)
这里的损失函数使用的crf,以计算到的标记去标记真实的标记,得到P(Y|X)最新为目标
4.训练数据
crf_decode = fluid.layers.crf_decoding(input=feature_out, param_attr=fluid.ParamAttr(name=‘crfw‘)) train_data = paddle.batch(paddle.reader.shuffle(paddle.dataset.conll05.test(), buf_size=8192), batch_size=BATCH_SIZE) place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace() feeder = fluid.DataFeeder( feed_list=[ word, ctx_n2, ctx_n1, ctx_0, ctx_p1, ctx_p2, predicate, mark, target ], place=place) exe = fluid.Executor(place) main_program = fluid.default_main_program() exe.run(fluid.default_startup_program()) embedding_param = fluid.global_scope().find_var( embedding_name).get_tensor() embedding_param.set( load_parameter(conll05.get_embedding(), word_dict_len, word_dim), place) start_time = time.time() batch_id = 0 for pass_id in six.moves.xrange(PASS_NUM): for data in train_data(): cost = exe.run(main_program, feed=feeder.feed(data), fetch_list=[avg_cost]) cost = cost[0] if batch_id % 10 == 0: print("avg_cost: " + str(cost)) if batch_id != 0: print("second per batch: " + str((time.time( ) - start_time) / batch_id)) # Set the threshold low to speed up the CI test if float(cost) < 60.0: if save_dirname is not None: fluid.io.save_inference_model(save_dirname, [ ‘word_data‘, ‘verb_data‘, ‘ctx_n2_data‘, ‘ctx_n1_data‘, ‘ctx_0_data‘, ‘ctx_p1_data‘, ‘ctx_p2_data‘, ‘mark_data‘ ], [feature_out], exe) break batch_id = batch_id + 1
标签:color 自然语言 location 自然语言分析 转移 词法 事件 tar input
原文地址:https://www.cnblogs.com/yangyang12138/p/12596322.html