标签:长度 使用 tar htm sizeof 刷新 操作 math 字符串操作
57 数字游戏
作者:
问题描述 :
现在,有许多给小孩子玩的数字游戏,这些游戏玩起来简单,但要创造一个就不是那么容易的了。 在这,我们将介绍一种有趣的游戏。
你将会得到N个正整数,你可以将一个整数接在另一个整数之后以制造一个更大的整数。 例如,这有4个数字123, 124, 56, 90,他们可以制造下列整数─ 1231245690, 1241235690, 5612312490, 9012312456, 9056124123....等,总共可以组合出24(4!)种数字。 但是,9056124123是最大的那一个。
你可能会想这是个简单的事情,但对刚有数字概念小孩来说,这会是个简单的任务吗?
输入说明 :
输入含有多组测试数据。
每组测试资料两行,第一行为一个正整数N(N<= 50),第二行将有N 个正整数。
当N=0代表输入结束。
输出说明 :
对每一组测试数据,输出一行,输出利用这N个整数可结合成的最大整数。
输入范例 :
5
123 124 56 90 9
1
1
5
991 9909 99 990 989
2
191 1919
0
输出范例 :
99056124123
1
999919909990989
1919191
总结,这道题目有着深刻的教训!!!
1、关于C语言的字符串操作及内存分析理解不到位,具体表现在 字符串数组和字符串指针区别遗忘。详解C语言字符串指针
2、对于全排列问题的深度优先搜索不是很理解,也就是说不借助于工具书写不出来。(递归)
3、DFS的剪枝经验不足,当数据量增大时,超时!
4、轻视了题目的数据规模,这个数据规模值得不仅仅是数据量,也保持了数据的排列方式。例如两个极端的测试案例(测试要有极端案例)
测试样例一:

测试样例一有什么意义呢?
第一:可以检验程序在极端情况下是否正常输出
第二:可以测试程序在极端情况下的耗时
通过这个测试样例,我很明显看到了倒序的数据输入耗时明显少于正序,而第一种输入甚至死循环也没出结果。这种情况其实是算法有问题。
毕竟50!次运算量很大。
那么,我就想到了一种有效的剪枝方法,即在全排列之前,可以先按照某种模糊的要求将记录数据的内容排序。使得全排列过程中可以提前
找打较大,甚至是最大的值。这个有什么用呢?单纯这种剪枝方法没有效果,要结合第二种剪枝,即在进入下一层DFS之前,提前将下一层的
结果和当前记录最大值进行比较,可以预判下一层的DFS是否已意义。如果没必要进行下一层,直接返回。大大减小计算量。详见代码。
测试样例二:(这个是点击官方案例才拿到的,没想到官方给的整数长度超过了30,不过这也合理)
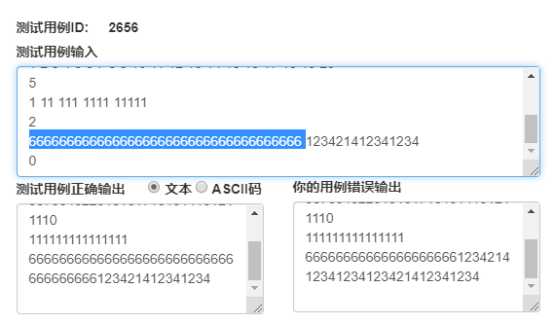
这个测试样例给予我深刻的印象,我会记你一辈子的。
简答总结一下思路和遇到的问题
今天早上的思路是就是通过字符串数组录入字符串,然后将字符串数组DFS全排列,全排列的过程通过索引生成完整的字符串(整数),
刷新最大值(通过strcmp)。这个思路是正确的。但是栽了不少坑。
1、刚开始没有用strcpy赋值字符串,使用的是max_str = str;导致输出的最大值一直是最后一个数据。
这个牵涉到字符串指针的理解
如果使用max_str = str这个的话,对字符数组str[]赋值,那么max_str肯定会跟着改变。
2、DFS剪枝,刚开始的剪枝单纯采用if(strncmp(temp,max_str,strlen(temp))>=0),即避免
本次91开始递归,记录最大值是92……。很明显无需递归下一层。似乎超时的样例少了一个。
3、下午索性自己造数据,造极端数据看看超时有多严重。
for循环产生

超时挺严重的,程序仿佛死循环,50!惹不起。
思考为啥有这么大的计算量,一看就很明显,前面的计算都没有意义,应当尝试将数据逆序下。
如下:

不到半秒就出结果了。!
这个给予我很大启示,在进行DFS之前,应当尽量先将记录数排序下,排序的目的使得DFS可以尽早找到较大值甚至最大值(减少计算量)
这个排序的方法在我脑海中闪现了一下。
如果数据是1 2 3
那么应当将记录数组该位3 2 1
如果数据是333 222 111 9
那么记录数组应当是9 333 222 111
详细说来
/**
为了减少计算量,提前将数据进行模糊排序
这个模糊排序指的是
比如
9 98如何定义大小呢?
我们规定9>98
因为如果数据集合是9 9 98的话
按照以上定义,我们可以比较快的DFS到9998
也就是尽可能让组成大的数据
但是不能依据这个的单纯的排序,这只是一个模糊的排序
如按照定义:19>192
如果单纯这种排序出结果,那么结果是19192
其实正确答案是 19219,
所以必须DFS比较。
以上的定义大小只是模糊的将“大的”数据放在记录数组的前面,
防止极端数据造成的无意义的DFS(计算量超大,参照1到50的正序数据)
**/
这种排序规则是这样的
1 int myStrcmp(char str1[],char str2[]){ 2 int i=0; 3 while(str1[i]!=‘\0‘&&str2[i]!=‘\0‘){ 4 // printf("i=%d\n",i); 5 if(str1[i]>str2[i]){ 6 return 1; 7 }else if(str1[i]<str2[i]){ 8 return -1; 9 } 10 i++; 11 } 12 //strcmp在这里肯定返回0,但是满足不了我的需求你 13 return strlen(str2)-strlen(str1);//原有判定条件下,短的更大 14 }
如果单纯用这种排序规则出来的数据是不一定正确的,有反例的如(19 192),必须进行DFS。
可能有的人不理解,但其实这种排序已经达到了剪枝的目的。通过排序使得DFS可以尽早地找打较大数据,减少计算量
并不会遗漏任何数据的。
完整代码:
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <math.h> 4 #include <string.h> 5 #include <ctype.h> 6 7 8 #define maxn 55 9 char rec[maxn][80]; 10 int Index[maxn]; 11 int hash[maxn] = {0}; 12 char *max_str; 13 14 char temp[505]; 15 int n; 16 17 void Permu_Index(int index); 18 void GenerateStr(int arr[], char str[],int index); 19 int myStrcmp(char str1[],char str2[]); 20 void MySort(); 21 22 int main(){ 23 24 int i; 25 while(1){ 26 27 scanf("%d",&n); 28 if(n == 0){ 29 break; 30 } 31 32 char str[505]; 33 str[0] = ‘\0‘; //教训,数据一直是最后的那组数据 34 35 max_str = str; 36 37 memset(hash,0,maxn*sizeof(int)); 38 for(i=0;i<n;i++){ 39 scanf("%s",&rec[i][0]);//写入字符串 40 } 41 42 //提前布置,剪枝(将记录数组中的数据排序,这样的话可以比较早的找找到较大值,大大减少重复计算) 43 MySort(); 44 //生成索引的全排列,并更新最大值 45 Permu_Index(0); 46 printf("%s\n",max_str); 47 48 } 49 return 0; 50 } 51 52 53 54 /* 55 建立一个字符串数组解决字符串的保存 56 生成n个数的全排列(0-n-1) 57 字符串比较大小 58 */ 59 void Permu_Index(int index){ 60 61 if(index == n){ 62 //一个排列已经完成,比较大小更新最值 63 temp[0] = ‘\0‘; 64 GenerateStr(Index,temp,n-1); 65 if(strcmp(temp,max_str)>0){ 66 strcpy(max_str,temp); 67 } 68 return ; 69 } 70 71 int i; 72 for(i=0;i<n;i++){ 73 if(hash[i] == 0){ 74 //数字i还没有被利用 75 Index[index] = i; 76 hash[i] = 1; 77 temp[0] = ‘\0‘; 78 GenerateStr(Index,temp,index); 79 80 if(strncmp(temp,max_str,strlen(temp))>=0){ 81 Permu_Index(index+1); 82 hash[i] = 0; //已经处理完Index[index]为i的问题,还原状态 83 }else{ 84 hash[i] = 0; 85 return; 86 } 87 88 } 89 } 90 } 91 92 93 void GenerateStr(int arr[], char str[],int index){ 94 int i; 95 for(i=0;i<=index;i++){ 96 int idx = arr[i]; 97 strcat(str,&rec[idx][0]); 98 } 99 } 100 101 int myStrcmp(char str1[],char str2[]){ 102 int i=0; 103 while(str1[i]!=‘\0‘&&str2[i]!=‘\0‘){ 104 // printf("i=%d\n",i); 105 if(str1[i]>str2[i]){ 106 return 1; 107 }else if(str1[i]<str2[i]){ 108 return -1; 109 } 110 i++; 111 } 112 //strcmp在这里肯定返回0,但是满足不了我的需求你 113 return strlen(str2)-strlen(str1);//原有判定条件下,短的更大 114 } 115 116 void MySort(){ 117 int i,j; 118 char temp[80]; 119 for(i=n-2;i>=0;i--){ 120 for(j=0;j<=i;j++){ 121 if(myStrcmp(&rec[j][0],&rec[j+1][0])<0){ 122 //90<9 123 strcpy(temp,&rec[j][0]); 124 strcpy(&rec[j][0],&rec[j+1][0]); 125 strcpy(&rec[j+1][0],temp); 126 } 127 } 128 } 129 }
标签:长度 使用 tar htm sizeof 刷新 操作 math 字符串操作
原文地址:https://www.cnblogs.com/ManOK/p/12601938.html