标签:加锁 数据库 查询更新 第一个 导致 请求 比较 info 业务
库存的变化是原子性的,如果在更新的库存的时候没有考虑好如何更新库存,那么会导致库存的 重复修改、脏读、幻读、不可重复读等操作。
但如果加锁的粒度过于大的话,就会导致大量的更新库存的请求失败。无法支持高并发的。
那么该怎么样写合适代码来更新库存呢?
其实核心思想是:
1. 加事务
2. 查询更新
先看下导致重复修改的代码: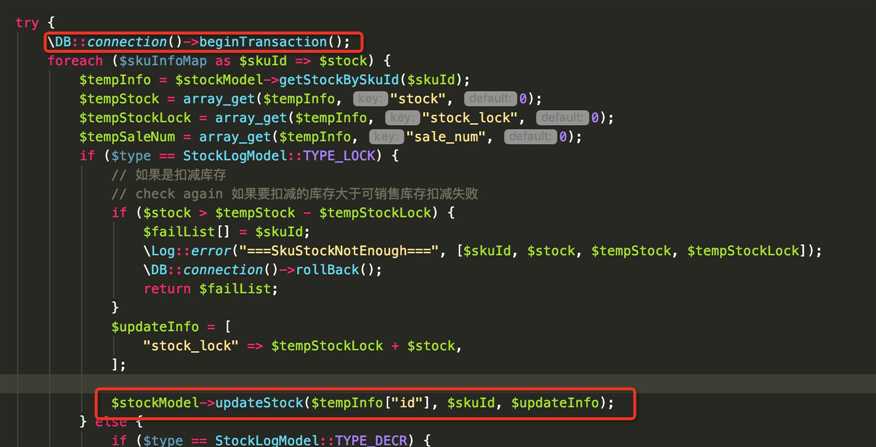
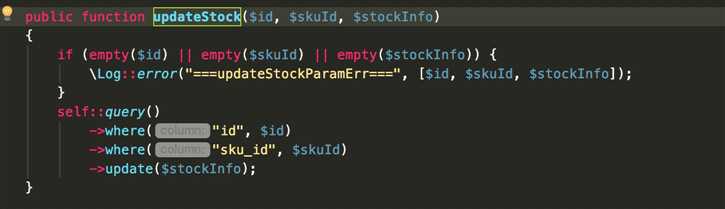
虽然这个方法是加了事务,然而事务在执行的过程中,只能保证事务的独立性,但是在更新库存的时候,还是造成了重复写入的错误。
接着看下,第一版本的优化:
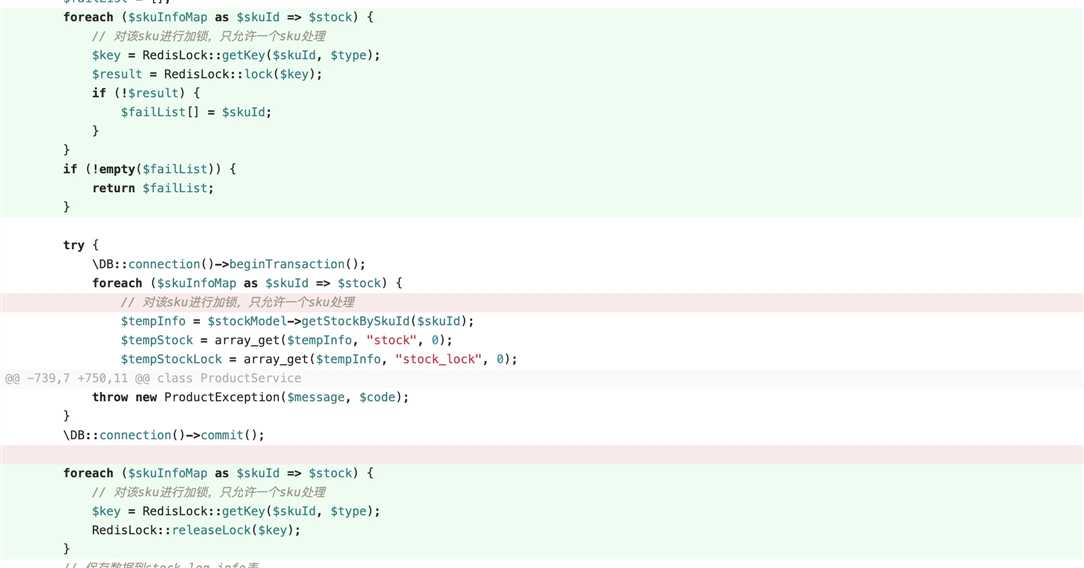
第一版的优化方法是对每个skuId加了一个锁,保证同一时刻对某一sku_id的操作是唯一的,但是这种方法无法支持高并发,对一个高并发的网站来说不是一个很好的选择。
再看下第二版本的优化:
这个版本的优化是在执行更新操作的时候,比较一下skuId的库存数是不是和原先的一样,如果一样的话就更新,如果不一样的话就更新失败。
我们这样想,同时有10个请求进来,对数据库进行操作。第一个请求更新完库存后,其他9个请求去校验库存,库存校验这个时候一定是失败的,这样会导致另外9的请求的更新库存是失败的。
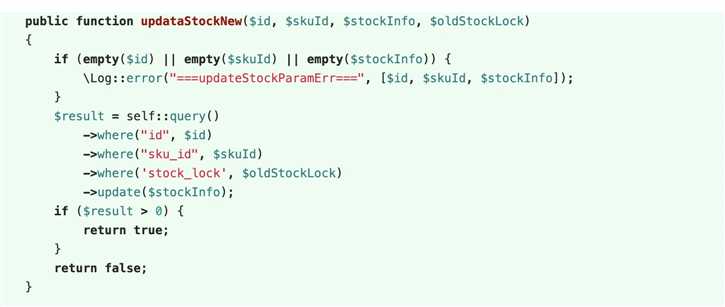
最后再看下最终版本的解决方法:
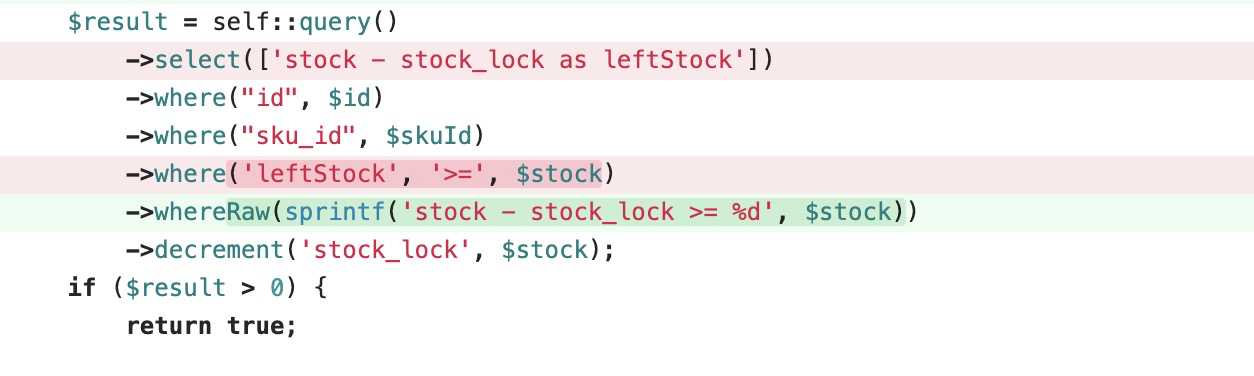
最后的方法是将判断库存是不是足够,以及增加库存的语句放到了一个sql里,这样的话,每个事务在执行的时候只需要判断,库存是不是足够就行了。并不会影响每个事务的更新操作。
标签:加锁 数据库 查询更新 第一个 导致 请求 比较 info 业务
原文地址:https://www.cnblogs.com/cjjjj/p/12602459.html