标签:读取 静态方法 包括 复制 二进制文件 文件输入 取出 tput 需要
前面介绍 BufferedReader 时提到它的一个特征——当 BufferedReader 读取输入流中的数据时,如果没有读到有效数据,程序将在此处阻塞该线程的执行(使用 InputStream 的 read() 方法从流中读取数据时,如果数据源中没有数据,它也会阻塞该线程),也就是前面介绍的输入流、输出流都是阻塞式的输入、输出。不仅如此,传统的输入流、输出流都是通过字节的移动来处理的(即使不直接去处理字节流,但底层的实现还是依赖于字节处理),也就是说,面向流的输入/输出系统一次只能处理一个字节,因此面向流的输入/输出系统通常效率不高。
从 JDK 1.4 开始,Java 提供了一系列改进的输入/输出处理的新功能,这些功能被统称为新IO(New IO,简称NIO),新增了许多用于处理输入/输出的类,这些类都被放在 java.nio 包以及子包下,并且对原 java.io 包中的很多类都以 NIO 为基础进行了改写,新增了满足 NIO 的功能。
新IO和传统的IO有相同的目的,都是用于进行输入/输出,但新IO使用了不同的方式来处理输入/输出,新IO采用内存映射文件的方式来处理输入/输出,新IO将文件或文件的一段区域映射到内存中,这样就可以像访问内存一样来访问文件了(这种方式模拟了操作系统上的虚拟内存的概念),通过这种方式来进行输入/输出比传统的输入/输出要快得多。
Java 中与新IO相关的包如下。
Channel(通道)和 Buffer(缓冲)是新IO中的两个核心对象,Channel 是对传统的输入/输出系统的模拟,在新IO系统中所有的数据都需要通过通道传输:Channel 与传统的 InputStream、OutputStream 最大的区别在于它提供了一个 map() 方法,通过该 map() 方法可以直接将“一块数据”映射到内存中。如果说传统的输入/输出系统是面向流的处理,则新IO则是面向块的处理。
Buffer 可以被理解成一个容器,它的本质是一个数组,发送到 Channel 中的所有对象都必须首先放到 Buffer 中,而从 Channel 中读取的数据也必须先放到 Buffer 中。此处的 Buffer 有点类似于前面介绍的“竹筒”,但该 Buffer 既可以像“竹筒”那样一次次去 Channel 中取水,也允许使用 Channel 直接将文件的某块数据映射成 Buffer。
除 Channel 和 Buffer 之外,新IO还提供了用于将 Unicode 字符串映射成字节序列以及逆映射操作的 Charset 类,也提供了用于支持非阻塞式输入/输出的 Selector 类。
从内部结构上来看,Buffer 就像一个数组,它可以保存多个类型相同的数据。Buffer 是一个抽象类,其最常用的子类是 ByteBuffer,它可以在底层字节数组上进行 get/set 操作。除 ByteBuffer 之外,对应于其他基本数据类型(boolean 除外)都有相应的 Buffer 类;CharBuffer、ShortBuffer、IntBuffer、LongBuffer、FloatBuffer、DoubleBuffer。
上面这些 Buffer 类,除 ByteBuffer 之外,它们都采用相同或相似的方法来管理数据,只是各自管理的数据类型不同而己。这些 Buffer 类都没有提供构造器,通过使用如下方法来得到一个 Buffer 对象。
但实际使用较多的是 ByteBuffer 和 CharBuffer,其他 Buffer 子类则较少用到。其中 ByteBuffer 类还有一个子类:MappedByteBuffer,它用于表示 Channel 将磁盘文件的部分或全部内容映射到内存中后得到的结果,通常 MappedByteBuffer 对象由 Channel 的 map() 方法返回。
在 Buffer 中有三个重要的概念:容量(capacity)、界限(limit)和位置(position)。
除此之外,Buffer 里还支持一个可选的标记(mark,类似于传统IO流中的 mark),Buffer 允许直接将 position 定位到该 mark 处。这些值满足如下关系:
0≤mark≤position≤limit≤capacity
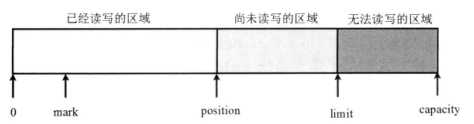
图1:Buffer 读入数据后的示意图
图1显示了某个 Buffer 读入了一些数据后的示意图。
Buffer 的主要作用就是装入数据,然后输出数据(其作用类似于前面介绍的取水的“竹筒”),开始时 Buffer 的 position为0,limit 为 capacity,程序可通过 put() 方法向 Buffer 中放入一些数据(或者从 Channel 中获取一些数据),每放入一些数据,Buffer 的 position 相应地向后移动一些位置。
当 Buffer 装入数据结束后,调用 Buffer 的 flip() 方法,该方法将 limit 设置为 position 所在位置,并将 position 设为0,这就使得 Buffer 的读写指针又移到了开始位置。也就是说,Buffer 调用 flip() 方法之后,Buffer 为输出数据做好备:当 Buffer 输出数据结束后,Buffer 调用 clear() 方法,clear() 方法不是清空 Buffer 的数据,它仅仅将 position 置为0,将 limit 置为 capacity,这样为再次向 Buffer 中装入数据做好准备。
提示:Buffer 中包含两个重要的方法,即 flip() 和 clear(),flip() 为从 Buffer 中取出数据做好准备,而 clear() 为再次向 Buffer 中装入数据做好准备。
除此之外,Buffer 还包含如下一些常用的方法。
除这些移动 position、limit、mark 的方法之外,Buffer 的所有子类还提供了两个重要的方法:put() 和 get() 方法,用于向 Buffer 中放入数据和从 Buffer 中取出数据。当使用 put() 和 get() 方法放入、取出数据时,Buffer 既支持对单个数据的访问,也支持对批量数据的访问(以数组作为参数)。
当使用 put() 和 get() 来访问 Buffer 中的数据时,分为相对和绝对两种。
下面程序示范了 Buffer 的一些常规操作。
public class BufferTest { public static void main(String[] args) { // 创建Buffer CharBuffer buff = CharBuffer.allocate(8); // ① System.out.println("capacity: " + buff.capacity()); System.out.println("limit: " + buff.limit()); System.out.println("position: " + buff.position()); // 放入元素 buff.put(‘a‘); buff.put(‘b‘); buff.put(‘c‘); // ② System.out.println("加入三个元素后,position = " + buff.position()); // 调用flip()方法 buff.flip(); // ③ System.out.println("执行flip()后,limit = " + buff.limit()); System.out.println("position = " + buff.position()); // 取出第一个元素 System.out.println("第一个元素(position=0):" + buff.get()); // ④ System.out.println("取出一个元素后,position = " + buff.position()); // 调用clear方法 buff.clear(); // ⑤ System.out.println("执行clear()后,limit = " + buff.limit()); System.out.println("执行clear()后,position = " + buff.position()); System.out.println("执行clear()后,缓冲区内容并没有被清除:" + "第三个元素为:" + buff.get(2)); // ⑥ System.out.println("执行绝对读取后,position = " + buff.position()); } }
在上面程序的①号代码处,通过 CharBuffer 的一个静态方法 allocate() 创建了一个 capacity 为8的 CharBuffer,此时该 Buffer 的 limit 和 capacity 为8,position 为0,如图2所示。
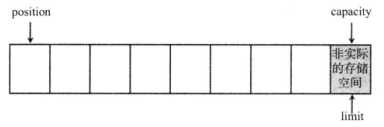
图2:新分配的 CharBuffer 对象
接下来程序执行到②号代码处,程序向 CharBuffer 中放入3个数值,放入3个数值后的 CharBuffer 效果如图3所示。
程序执行到③号代码处,调用了 Buffer 的 flip() 方法,该方法将把 limit 设为 position 处,把 position 设为0,如图4所示。
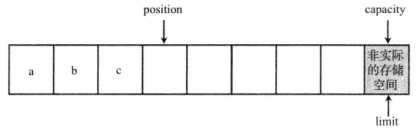
图3:向 Buffer 中放入3个对象后的示意图
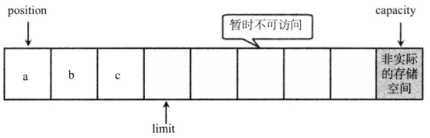
图4:执行 Buffer 的 flip() 方法后的示意图
从图4中可以看出,当 Buffer 调用了 flip() 方法之后,limit 就移到了原来 position 所在位置,这样相当于把 Buffer 中没有数据的存储空间“封印”起来,从而避免读取 Buffer 数据时读到 null 值。
接下来程序在④号代码处取出一个元素,取出一个元素后 position 向后移动一位,也就是该 Buffer 的 position 等于1。程序执行到⑤号代码处,Buffer 调用 clear() 方法去将 position 设为0,将 limit 设为与 capacity 相等。执行 clear() 方法后的 Buffer 示意图如图5所示。
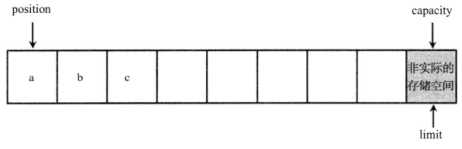
图5:执行 Buffer 的 clear() 方法后的示意图
从图5中可以看出,对 Buffer 执行 clear() 方法后,该 Buffer 对象里的数据依然存在,所以程序在⑥号代码处依然可以取出位置为2的值,也就是字符c。因为⑥号代码采用的是根据索引来取值的方式,所以该方法不会影响 Buffer 的 position。
通过 allocate() 方法创建的 Buffer 对象是普通 Buffer,ByteBuffer 还提供了一个 allocateDirect() 方法来创建直接 Buffer。直接 Buffer 的创建成本比普通 Buffer 的创建成本高,但直接 Buffer 的读取效率更高。
提示:由于直接 Buffer 的创建成本很高,所以直接 Buffer 只适用于长生存期的 Buffer,而不适用于短生存期、一次用完就丢弃的 Buffer。而且只有 ByteBuffer 才提供了 allocateDirect() 方法,所以只能在 ByteBuffer 级别上创建直接 Buffer。如果希望使用其他类型,则应该将该 Buffer 转换成其他类型的 Buffer。
直接 Buffer 在编程上的用法与普通 Buffer 并没有太大的区别,故此处不再贅述。
Channel 类似于传统的流对象,但与传统的流对象有两个主要区别。
Java 为 Channel 接口提供了 DatagramChannel、FileChannel、Pipe.SinkChannel、Pipe.SourceChannel、SelectableChannel、ServerSocketChannel、SocketChannel 等实现类,本节主要介绍 FileChannel 的用法。根据这些 Channel 的名字不难发现,新IO里的 Channel 是按功能来划分的,例如 Pipe.SinkChannel、Pipe.SourceChannel 是用于支持线程之间通信的管道 Channel;ServerSocketChannel、SocketChannel 是用于支持 TCP 网络通信的 Channel;而 DatagramChannel 则是用于支持 UDP 网络通信的Channel。
所有的 Channel 都不应该通过构造器来直接创建,而是通过传统的节点 InputStream、OutputStream 的 getChannel() 方法来返回对应的 Channel,不同的节点流获得的 Channel 不一样。例如,FileInputStream、FileOutputStream 的 getChannel() 返回的是 FileChannel,而 PipedInputStream 和 PipedOutputStream 的 getChannel()返回的是 Pipe.SinkChannel、Pipe.SourceChannel。
Channel 中最常用的三类方法是 map()、read() 和 write(),其中 map() 方法用于将 Channel 对应的部分或全部数据映射成 ByteBuffer;而 read() 或 write() 方法都有一系列重载形式,这些方法用于从 Buffer中读取数据或向 Buffer 中写入数据。
map() 方法的方法签名为:MappedByteBuffer map(FileChannel.MapMode mode, long position,long size),第一个参数执行映射时的模式,分别有只读、读写等模式;而第二个、第三个参数用于控制将 Channel 的哪些数据映射成 ByteBuffer。
下面程序示范了直接将 FileChannel 的全部数据映射成 ByteBuffer 的效果。
public class FileChannelTest { public static void main(String[] args) { File f = new File("FileChannelTest.java"); try ( // 创建FileInputStream,以该文件输入流创建FileChannel FileChannel inChannel = new FileInputStream(f).getChannel(); // 以文件输出流创建FileBuffer,用以控制输出 FileChannel outChannel = new FileOutputStream("a.txt").getChannel()) { // 将FileChannel里的全部数据映射成ByteBuffer MappedByteBuffer buffer = inChannel.map(FileChannel.MapMode.READ_ONLY, 0, f.length()); // ① // 使用GBK的字符集来创建解码器 Charset charset = Charset.forName("GBK"); // 直接将buffer里的数据全部输出 outChannel.write(buffer); // ② // 再次调用buffer的clear()方法,复原limit、position的位置 buffer.clear(); // 创建解码器(CharsetDecoder)对象 CharsetDecoder decoder = charset.newDecoder(); // 使用解码器将ByteBuffer转换成CharBuffer CharBuffer charBuffer = decoder.decode(buffer); // CharBuffer的toString方法可以获取对应的字符串 System.out.println(charBuffer); } catch (IOException ex) { ex.printStackTrace(); } } }
上面程序中的两行粗体字代码分别使用 FileInputStream、FileOutputStream 来获取 FileChannel,虽然 FileChannel 既可以读取也可以写入,但 FileInputStream 获取的 FileChannel 只能读,而 FileOutputStream 获取的 FileChannel 只能写。程序中①号代码处直接将指定 Channel 中的全部数据映射成 ByteBuffer,然后程序中②号代码处直接将整个 ByteBuffer 的全部数据写入一个输出 FileChannel 中,这就完成了文件的复制。
程序后面部分为了能将 FileChannelTest.java 文件里的内容打印出来,使用了 Charset 类和 CharsetDecoder 类将 ByteBuffer 转换成 CharBuffer。关于 Charset 和 CharsetDecoder 下一节将会有更详细的介绍。
不仅 InputStream、OutputStream 包含了 getChannel() 方法,在 RandomAccessFile 中也包含了一个 getChannel() 方法,RandomAccessFile 返回的 FileChannel() 是只读的还是读写的,则取决于 RandomAccessFile 打开文件的模式。例如,下面程序将会对 a.txt 文件的内容进行复制,追加在该文件后面。
public class RandomFileChannelTest { public static void main(String[] args) throws IOException { File f = new File("a.txt"); try ( // 创建一个RandomAccessFile对象 RandomAccessFile raf = new RandomAccessFile(f, "rw"); // 获取RandomAccessFile对应的Channel FileChannel randomChannel = raf.getChannel()) { // 将Channel中所有数据映射成ByteBuffer ByteBuffer buffer = randomChannel.map(FileChannel.MapMode.READ_ONLY, 0, f.length()); // 把Channel的记录指针移动到最后 randomChannel.position(f.length()); // 将buffer中所有数据输出 randomChannel.write(buffer); } } }
上面程序中的粗体字代码可以将 Channel 的记录指针移动到该 Channel 的最后,从而可以让程序将指定 ByteBuffer 的数据追加到该 Channel 的后面。每次运行上面程序,都会把 a.txt 文件的内容复制一份,并将全部内容追加到该文件的后面。
如果读者习惯了传统IO的“用竹筒多次重复取水”的过程,或者担心 Channel 对应的文件过大,使用 map() 方法一次将所有的文件内容映射到内存中引起性能下降,也可以使用 Channel 和 Buffer 传统的“用竹筒多次重复取水”的方式。如下程序所示。
public class ReadFile { public static void main(String[] args) throws IOException { try ( // 创建文件输入流 FileInputStream fis = new FileInputStream("ReadFile.java"); // 创建一个FileChannel FileChannel fcin = fis.getChannel()) { // 定义一个ByteBuffer对象,用于重复取水 ByteBuffer bbuff = ByteBuffer.allocate(256); // 将FileChannel中数据放入ByteBuffer中 while (fcin.read(bbuff) != -1) { // 锁定Buffer的空白区 bbuff.flip(); // 创建Charset对象 Charset charset = Charset.forName("GBK"); // 创建解码器(CharsetDecoder)对象 CharsetDecoder decoder = charset.newDecoder(); // 将ByteBuffer的内容转码 CharBuffer cbuff = decoder.decode(bbuff); System.out.print(cbuff); // 将Buffer初始化,为下一次读取数据做准备 bbuff.clear(); } } } }
上面代码虽然使用 FileChannel 和 Buffer 来读取文件,但处理方式和使用 InputStream、byte[] 来读取文件的方式几乎一样,都是采用“用竹筒多次重复取水”的方式。但因为 Buffer 提供了 flip() 和 clear() 两个方法,所以程序处理起来比较方便,每次读取数据后调用 flip() 方法将没有数据的区域“封印”起来,避免程序从 Buffer 中取出 null 值:数据取出后立即调用 clear() 方法将 Buffer 的 position 设0,为下一次读取数据做准备。
前面已经提到:计算机里的文件、数据、图片文件只是一种表面现象,所有文件在底层都是二进制文件,即全部都是字节码。图片、音乐文件暂时先不说,对于文本文件而言,之所以可以看到一个个的字符,这完全是因为系统将底层的二进制序列转换成字符的缘故。在这个过程中涉及两个概念:编码(Encode)和解码(Decode),通常而言,把明文的字符序列转换成计算机理解的二进制序列(普通人看不懂)称为编码,把二进制序列转换成普通人能看懂的明文字符串称为解码,如下图所示。

计算机底层是没有文本文件、图片文件之分的,它只是忠实地记录每个文件的二进制序列而已。当需要保存文本文件时,程序必须先把文件中的每个字符翻译成二进制序列:当需要读取文本文件时,程序必须把二进制序列转换为一个个的字符。
Java 默认使用 Unicode 字符集,但很多操作系统并不使用 Unicode 字符集,那么当从系统中读取数据到 Java 程序中时,就可能出现乱码等问题。
JDK 1.4 提供了Charset 来处理字节序列和字符序列(字符串)之间的转换关系,该类包含了用于创建解码器和编码器的方法,还提供了获取 Charset 所支持字符集的方法,Charset 类是不可变的。
Charset 类提供了一个 availableCharsets() 静态方法来获取当前 JDK 所支持的所有字符集。所以程序可以使用如下程序来获取该 JDK 所支持的全部字符集。
public class CharsetTest { public static void main(String[] args) { // 获取Java支持的全部字符集 SortedMap<String, Charset> map = Charset.availableCharsets(); for (String alias : map.keySet()) { // 输出字符集的别名和对应的Charset对象 System.out.println(alias + "----->" + map.get(alias)); } } }
上面程序中的粗体字代码获取了当前 Java 所支持的全部字符集,并使用遍历方式打印了所有字符集的别名(字符集的字符串名称)和 Charset 对象。从上面程序可以看出,每个字符集都有一个字符串名称,也被称为字符串别名。对于中国的程序员而言,下面几个字符串别名是常用的。
提示:可以使用 System 类的 getProperties() 方法来访问本地系统的文件编码格式,文件编码格式的属性名为 file-encoding。
一旦知道了字符集的别名之后,程序就可以调用 Charset 的 forName() 方法来创建对应的 Charset 对象,forName() 方法的参数就是相应字符集的别名。例如如下代码:
Charset cs = Charset.forName("ISO-8859-1");
Charset cs = Charset.forName("GBK");
获得了 Charset 对象之后,就可以通过该对象的 newDecoder()、newEncoder() 这两个方法分别返回 CharsetDecoder 和 CharsetEncoder 对象,代表该 Charset 的解码器和编码器。调用 CharsetDecoder 的 decode() 方法就可以将 ByteBuffer(字节序列)转换成 CharBuffer(字符序列),调用 CharsetEncoder 的 encode() 方法就可以将 CharBuffer 或 String(字符序列)转换成 ByteBuffer(字节序列)。如下程序使用了 CharsetEncoder 和 CharsetDecoder 完成了 ByteBuffer 和 CharBuffer 之间的转换。
注意:Java7 新增了一个 StandardCharsets 类,该类里包含了 ISO_8859_1、UTF8、UTF16 等类变量,这些类变量代表了最常用的字符集对应的 Charset 对象。
public class CharsetTransform { public static void main(String[] args) throws Exception { // 创建简体中文对应的Charset Charset cn = Charset.forName("GBK"); // 获取cn对象对应的编码器和解码器 CharsetEncoder cnEncoder = cn.newEncoder(); CharsetDecoder cnDecoder = cn.newDecoder(); // 创建一个CharBuffer对象 CharBuffer cbuff = CharBuffer.allocate(8); cbuff.put(‘孙‘); cbuff.put(‘悟‘); cbuff.put(‘空‘); cbuff.flip(); // 将CharBuffer中的字符序列转换成字节序列 ByteBuffer bbuff = cnEncoder.encode(cbuff); // 循环访问ByteBuffer中的每个字节 for (int i = 0; i < bbuff.capacity(); i++) { System.out.print(bbuff.get(i) + " "); } // 将ByteBuffer的数据解码成字符序列 System.out.println("\n" + cnDecoder.decode(bbuff)); } }
上面程序中的两行粗体字代码分别实现了将 CharBuffer 转换成 ByteBuffer,将 ByteBuffer 转换成 CharBuffer 的功能。实际上,Charset 类也提供了如下三个方法。
也就是说,获取了 Charset 对象后,如果仅仅需要进行简单的编码、解码操作,其实无须创建 CharsetEncoder 和 CharsetDecoder 对象,直接调用 Charset 的 encode() 和 decode() 方法进行编码、解码即可。
提示:在 String 类里也提供了一个 getBytes(String charset) 方法,该方法返回 byte[],该方法也是使用指定的字符集将字符串转换成字节序列。
文件锁在操作系统中是很平常的事情,如果多个运行的程序需要并发修改同一个文件时,程序之间需要某种机制来进行通信,使用文件锁可以有效地阻止多个进程并发修改同一个文件,所以现在的大部分操作系统都提供了文件锁的功能。
文件锁控制文件的全部或部分字节的访问,但文件锁在不同的操作系统中差别较大,所以早期的 JDK 版本并未提供文件锁的支持。从 JDK1.4 的 NIO 开始,Java 开始提供文件锁的支持。
在 NIO 中,Java 提供了 FileLock 来支持文件锁定功能,在 FileChannel 中提供的 lock()/tryLock() 方法可以获得文件锁 FileLock 对象,从而锁定文件。lock() 和 tryLock() 方法存在区别:当 lock() 试图锁定某个文件时,如果无法得到文件锁,程序将一直阻塞;而 tryLock() 是尝试锁定文件,它将直接返回而不是阻塞,如果获得了文件锁,该方法则返回该文件锁,否则将返回 null。
如果 FileChannel 只想锁定文件的部分内容,而不是锁定全部内容,则可以使用如下的 lock() 或 tryLock() 方法。
当参数 shared 为 true 时,表明该锁是一个共享锁,它将允许多个进程来读取该文件,但阻止其他进程获得对该文件的排他锁。当 shared 为 false 时,表明该锁是一个排他锁,它将锁住对该文件的读写。程序可以通过调用 FileLock 的 isShared 来判断它获得的锁是否为共享锁。
注意:直接使用 lock() 或 tryLock() 方法获取的文件锁是排他锁。
处理完文件后通过 FileLock 的 release() 方法释放文件锁。下面程序示范了使用 FileLock 锁定文件的示例。
public class FileLockTest { public static void main(String[] args) throws Exception { try ( // 使用FileOutputStream获取FileChannel FileChannel channel = new FileOutputStream("a.txt").getChannel()) { // 使用非阻塞式方式对指定文件加锁 FileLock lock = channel.tryLock(); // 程序暂停10s Thread.sleep(10000); // 释放锁 lock.release(); } } }
上面程序中的第一行粗体字代码用于对指定文件加锁,接着程序调用 Thread.sleep(10000) 暂停了 10 秒后才释放文件锁(如程序中第二行粗体字代码所示),因此在这10秒之内,其他程序无法对 a.txt 文件进行修改。
注意:文件锁虽然可以用于控制并发访问,但对于高并发访问的情形,还是推荐使用数据库来保存程序信息,而不是使用文件。
关于文件锁还需要指出如下几点。
标签:读取 静态方法 包括 复制 二进制文件 文件输入 取出 tput 需要
原文地址:https://www.cnblogs.com/jwen1994/p/12597109.html