标签:column 填充 多层 操作 数组 前缀 value rand false
对数据集进行分组,然后对每组进行统计分析
SQL能够对数据进行过滤,分组聚合
pandas能利用groupby进行更加复杂的分组运算
分组运算过程:split->apply->combine
拆分:进行分组的根据
应用:每个分组运行的计算规则
合并:把每个分组的计算结果合并起来
groupby()进行分组,GroupBy对象没有进行实际运算,只是包含分组的中间数据
按列名分组:obj.groupby(‘label’)
import pandas as pd import numpy as np dict_obj = {‘key1‘ : [‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘a‘], ‘key2‘ : [‘one‘, ‘one‘, ‘two‘, ‘three‘, ‘two‘, ‘two‘, ‘one‘, ‘three‘], ‘data1‘: np.random.randn(8), ‘data2‘: np.random.randn(8)} df_obj = pd.DataFrame(dict_obj) print(df_obj) # dataframe根据key1进行分组 print(type(df_obj.groupby(‘key1‘))) # dataframe的 data1 列根据 key1 进行分组 print(type(df_obj[‘data1‘].groupby(df_obj[‘key1‘])))
效果
key1 key2 data1 data2 0 a one -0.781769 0.210258 1 b one 0.396690 -0.315129 2 a two -1.819083 0.394317 3 b three 0.142387 -0.237055 4 a two -0.466665 -0.159256 5 b two 1.482328 -1.391806 6 a one -1.252323 -0.332732 7 a three 2.090247 -0.142536 <class ‘pandas.core.groupby.generic.DataFrameGroupBy‘> <class ‘pandas.core.groupby.generic.SeriesGroupBy‘>
对GroupBy对象进行分组运算/多重分组运算,如mean()
非数值数据不进行分组运算
import pandas as pd import numpy as np dict_obj = {‘key1‘ : [‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘a‘], ‘key2‘ : [‘one‘, ‘one‘, ‘two‘, ‘three‘, ‘two‘, ‘two‘, ‘one‘, ‘three‘], ‘data1‘: np.random.randn(8), ‘data2‘: np.random.randn(8)} df_obj = pd.DataFrame(dict_obj) print(df_obj) # 分组运算 grouped1 = df_obj.groupby(‘key1‘) print(grouped1.mean()) grouped2 = df_obj[‘data1‘].groupby(df_obj[‘key1‘]) print(grouped2.mean())
效果
key1 key2 data1 data2 0 a one 0.405285 -1.813457 1 b one -1.037339 1.096004 2 a two -0.766808 -0.090973 3 b three -0.167037 1.077283 4 a two 0.543593 -0.323844 5 b two -1.178883 0.670555 6 a one -0.361643 -0.789085 7 a three 0.247109 0.374743 data1 data2 key1 a 0.013507 -0.528523 b -0.794420 0.947948 key1 a 0.013507 b -0.794420 Name: data1, dtype: float64
size() 返回每个分组的元素个数
import pandas as pd import numpy as np dict_obj = {‘key1‘ : [‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘a‘], ‘key2‘ : [‘one‘, ‘one‘, ‘two‘, ‘three‘, ‘two‘, ‘two‘, ‘one‘, ‘three‘], ‘data1‘: np.random.randn(8), ‘data2‘: np.random.randn(8)} df_obj = pd.DataFrame(dict_obj) print(df_obj) # 分组运算 grouped1 = df_obj.groupby(‘key1‘) print(grouped1.mean()) grouped2 = df_obj[‘data1‘].groupby(df_obj[‘key1‘]) print(grouped2.mean()) # size print(grouped1.size()) print(grouped2.size())
效果
key1 key2 data1 data2 0 a one -0.304378 1.082606 1 b one 2.915354 0.618401 2 a two 0.517311 0.400274 3 b three 0.305766 -0.688211 4 a two -0.321439 -1.570279 5 b two -0.598021 -0.002561 6 a one -1.572549 0.917218 7 a three 1.147867 -1.142880 data1 data2 key1 a -0.106638 -0.062612 b 0.874366 -0.024124 key1 a -0.106638 b 0.874366 Name: data1, dtype: float64 key1 a 5 b 3 dtype: int64 key1 a 5 b 3 Name: data1, dtype: int64
obj.groupby(self_def_key)
自定义的key可为列表或多层列表
obj.groupby([‘label1’, ‘label2’])->多层dataframe
import pandas as pd import numpy as np dict_obj = {‘key1‘ : [‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘a‘], ‘key2‘ : [‘one‘, ‘one‘, ‘two‘, ‘three‘, ‘two‘, ‘two‘, ‘one‘, ‘three‘], ‘data1‘: np.random.randn(8), ‘data2‘: np.random.randn(8)} df_obj = pd.DataFrame(dict_obj) print(df_obj) # 按自定义key分组,列表 self_def_key = [0, 1, 2, 3, 3, 4, 5, 7] print(df_obj.groupby(self_def_key).size()) # 按自定义key分组,多层列表 print(df_obj.groupby([df_obj[‘key1‘], df_obj[‘key2‘]]).size()) # 按多个列多层分组 grouped2 = df_obj.groupby([‘key1‘, ‘key2‘]) print(grouped2.size()) # 多层分组按key的顺序进行 grouped3 = df_obj.groupby([‘key2‘, ‘key1‘]) print(grouped3.mean()) # unstack可以将多层索引的结果转换成单层的dataframe print(grouped3.mean().unstack())
效果
key1 key2 data1 data2 0 a one 0.997420 1.427648 1 b one -0.439493 0.864381 2 a two -0.586568 -0.266915 3 b three 0.626975 -1.411871 4 a two 0.549642 0.875476 5 b two -1.275776 -1.124462 6 a one -0.635578 0.039922 7 a three 1.037085 -1.842645 0 1 1 1 2 1 3 2 4 1 5 1 7 1 dtype: int64 key1 key2 a one 2 three 1 two 2 b one 1 three 1 two 1 dtype: int64 key1 key2 a one 2 three 1 two 2 b one 1 three 1 two 1 dtype: int64 data1 data2 key2 key1 one a 0.180921 0.733785 b -0.439493 0.864381 three a 1.037085 -1.842645 b 0.626975 -1.411871 two a -0.018463 0.304281 b -1.275776 -1.124462 data1 data2 key1 a b a b key2 one 0.180921 -0.439493 0.733785 0.864381 three 1.037085 0.626975 -1.842645 -1.411871 two -0.018463 -1.275776 0.304281 -1.124462
每次迭代返回一个元组 (group_name, group_data)
可用于分组数据的具体运算
import pandas as pd import numpy as np dict_obj = {‘key1‘: [‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘a‘], ‘key2‘: [‘one‘, ‘one‘, ‘two‘, ‘three‘, ‘two‘, ‘two‘, ‘one‘, ‘three‘], ‘data1‘: np.random.randn(8), ‘data2‘: np.random.randn(8)} df_obj = pd.DataFrame(dict_obj) print(df_obj) grouped1 = df_obj.groupby(‘key1‘) # 单层分组,根据key1 print("---") for group_name, group_data in grouped1: print(group_name) print(group_data)
效果
key1 key2 data1 data2 0 a one 1.362713 0.545293 1 b one 1.276236 0.747326 2 a two -0.224800 0.347855 3 b three -0.522983 -0.150675 4 a two 0.233628 2.042220 5 b two 0.090460 -0.611156 6 a one 0.372772 -0.779909 7 a three 0.281172 -0.192912 --- a key1 key2 data1 data2 0 a one 1.362713 0.545293 2 a two -0.224800 0.347855 4 a two 0.233628 2.042220 6 a one 0.372772 -0.779909 7 a three 0.281172 -0.192912 b key1 key2 data1 data2 1 b one 1.276236 0.747326 3 b three -0.522983 -0.150675 5 b two 0.090460 -0.611156
import pandas as pd import numpy as np dict_obj = {‘key1‘ : [‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘a‘], ‘key2‘ : [‘one‘, ‘one‘, ‘two‘, ‘three‘, ‘two‘, ‘two‘, ‘one‘, ‘three‘], ‘data1‘: np.random.randn(8), ‘data2‘: np.random.randn(8)} df_obj = pd.DataFrame(dict_obj) print(df_obj) # 按多个列多层分组 grouped2 = df_obj.groupby([‘key1‘, ‘key2‘]) # 多层分组 for group_name, group_data in grouped2: print(group_name) print(group_data)
效果
key1 key2 data1 data2 0 a one -1.045283 1.719594 1 b one -0.578823 0.432679 2 a two -1.018024 0.031187 3 b three -0.014241 -0.361193 4 a two 0.450544 0.266884 5 b two -0.304399 0.382678 6 a one 1.650063 -1.184126 7 a three -1.373968 -0.368473 (‘a‘, ‘one‘) key1 key2 data1 data2 0 a one -1.045283 1.719594 6 a one 1.650063 -1.184126 (‘a‘, ‘three‘) key1 key2 data1 data2 7 a three -1.373968 -0.368473 (‘a‘, ‘two‘) key1 key2 data1 data2 2 a two -1.018024 0.031187 4 a two 0.450544 0.266884 (‘b‘, ‘one‘) key1 key2 data1 data2 1 b one -0.578823 0.432679 (‘b‘, ‘three‘) key1 key2 data1 data2 3 b three -0.014241 -0.361193 (‘b‘, ‘two‘) key1 key2 data1 data2 5 b two -0.304399 0.382678
import pandas as pd import numpy as np dict_obj = {‘key1‘: [‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘a‘], ‘key2‘: [‘one‘, ‘one‘, ‘two‘, ‘three‘, ‘two‘, ‘two‘, ‘one‘, ‘three‘], ‘data1‘: np.random.randn(8), ‘data2‘: np.random.randn(8)} df_obj = pd.DataFrame(dict_obj) grouped1 = df_obj.groupby(‘key1‘) # GroupBy对象转换list print(list(grouped1)) # GroupBy对象转换dict print(dict(list(grouped1)))
效果
[
(
‘a‘, key1 key2 data1 data2 0 a one 0.377288 -1.662824 2 a two -0.206785 2.269787 4 a two -2.085155 -0.067927 6 a one -0.510846 0.888039 7 a three 0.782220 0.438419)
, (
‘b‘,
key1 key2 data1 data2 1 b one -1.999189 -0.934550 3 b three 0.696655 -2.640779 5 b two 0.247095 -0.227695)
]
{
‘a‘:
key1 key2 data1 data2 0 a one 0.377288 -1.662824 2 a two -0.206785 2.269787 4 a two -2.085155 -0.067927 6 a one -0.510846 0.888039 7 a three 0.782220 0.438419, ‘b‘: key1 key2 data1 data2 1 b one -1.999189 -0.934550 3 b three 0.696655 -2.640779 5 b two 0.247095 -0.227695
}
import pandas as pd import numpy as np dict_obj = {‘key1‘: [‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘a‘], ‘key2‘: [‘one‘, ‘one‘, ‘two‘, ‘three‘, ‘two‘, ‘two‘, ‘one‘, ‘three‘], ‘data1‘: np.random.randn(8), ‘data2‘: np.random.randn(8)} df_obj = pd.DataFrame(dict_obj) grouped1 = df_obj.groupby(‘key1‘) # 按列分组 print(‘----------------‘) # 按列分组 print(df_obj.dtypes) print(‘----------------‘) # 按数据类型分组 print(df_obj.groupby(df_obj.dtypes, axis=1).size())
效果
---------------- key1 object key2 object data1 float64 data2 float64 dtype: object ---------------- float64 2 object 2 dtype: int64
import pandas as pd import numpy as np df_obj2 = pd.DataFrame(np.random.randint(1, 10, (5, 5)), columns=[‘a‘, ‘b‘, ‘c‘, ‘d‘, ‘e‘], index=[‘A‘, ‘B‘, ‘C‘, ‘D‘, ‘E‘]) df_obj2.loc[1, 1:4] = np.NaN print(df_obj2)
效果:
a b c d e A 3.0 4.0 9.0 4.0 9.0 B 2.0 4.0 8.0 5.0 6.0 C 5.0 4.0 5.0 4.0 4.0 D 8.0 8.0 5.0 4.0 7.0 E 9.0 1.0 1.0 3.0 5.0 1 NaN NaN NaN NaN NaN
import pandas as pd import numpy as np # 通过字典分组 df_obj2 = pd.DataFrame(np.random.randint(1, 10, (5, 5)), columns=[‘a‘, ‘b‘, ‘c‘, ‘d‘, ‘e‘], index=[‘A‘, ‘B‘, ‘C‘, ‘D‘, ‘E‘]) mapping_dict = {‘a‘:‘Python‘, ‘b‘:‘Python‘, ‘c‘:‘Java‘, ‘d‘:‘C‘, ‘e‘:‘Java‘} print(‘---------------‘) print(df_obj2) print(‘---------------‘) print(df_obj2.groupby(mapping_dict, axis=1).size()) print(‘---------------‘) print(df_obj2.groupby(mapping_dict, axis=1).count()) # 非NaN的个数 print(‘---------------‘) print(df_obj2.groupby(mapping_dict, axis=1).sum())
效果:
--------------- a b c d e A 8 2 7 3 1 B 6 5 6 6 4 C 3 8 2 4 9 D 8 5 5 6 8 E 1 7 6 4 6 --------------- C 1 Java 2 Python 2 dtype: int64 --------------- C Java Python A 1 2 2 B 1 2 2 C 1 2 2 D 1 2 2 E 1 2 2 --------------- C Java Python A 3 8 10 B 6 10 11 C 4 11 11 D 6 13 13
# 通过函数分组 df_obj3 = pd.DataFrame(np.random.randint(1, 10, (5,5)), columns=[‘a‘, ‘b‘, ‘c‘, ‘d‘, ‘e‘], index=[‘AA‘, ‘BBB‘, ‘CC‘, ‘D‘, ‘EE‘]) #df_obj3 def group_key(idx): """ idx 为列索引或行索引 """ #return idx return len(idx) print(df_obj3.groupby(group_key).size()) # 以上自定义函数等价于 #df_obj3.groupby(len).size()
效果:
1 1
2 3
3 1
dtype: int64
# 通过索引级别分组 columns = pd.MultiIndex.from_arrays([[‘Python‘, ‘Java‘, ‘Python‘, ‘Java‘, ‘Python‘], [‘A‘, ‘A‘, ‘B‘, ‘C‘, ‘B‘]], names=[‘language‘, ‘index‘]) df_obj4 = pd.DataFrame(np.random.randint(1, 10, (5, 5)), columns=columns) print(df_obj4) # 根据language进行分组 print(df_obj4.groupby(level=‘language‘, axis=1).sum()) # 根据index进行分组 print(df_obj4.groupby(level=‘index‘, axis=1).sum())
效果:
language Python Java Python Java Python index A A B C B 0 7 2 4 6 5 1 2 8 8 8 8 2 2 5 6 2 8 3 8 7 6 9 5 4 8 3 4 9 2 language Java Python 0 8 16 1 16 18 2 7 16 3 16 19 4 12 14 index A B C 0 9 9 6 1 10 16 8 2 7 14 2 3 15 11 9 4 11 6 9
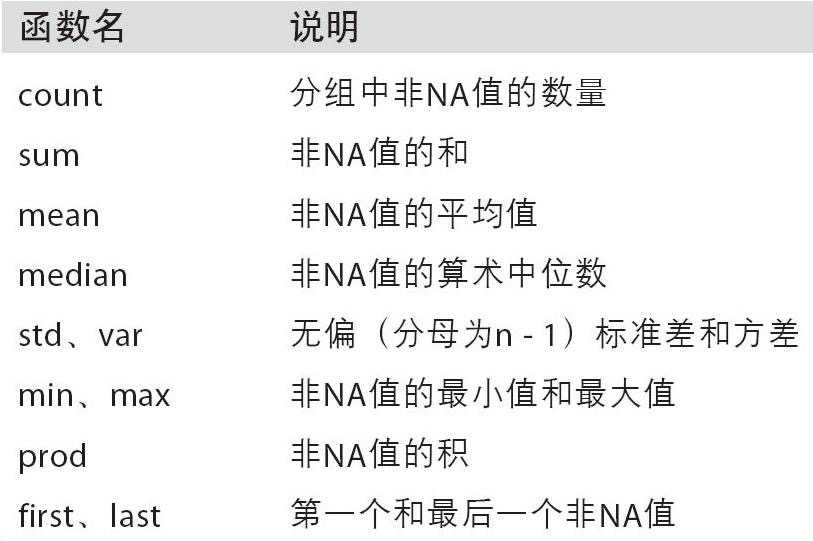
数组产生标量的过程,如mean()、count()等
常用于对分组后的数据进行计算
import pandas as pd import numpy as np dict_obj = {‘key1‘ : [‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘a‘], ‘key2‘ : [‘one‘, ‘one‘, ‘two‘, ‘three‘, ‘two‘, ‘two‘, ‘one‘, ‘three‘], ‘data1‘: np.random.randint(1,10, 8), ‘data2‘: np.random.randint(1,10, 8)} df_obj5 = pd.DataFrame(dict_obj) print(df_obj5)
效果:
key1 key2 data1 data2
0 a one 4 4
1 b one 1 6
2 a two 5 3
3 b three 7 2
4 a two 6 3
5 b two 7 5
6 a one 3 9
7 a three 3 8
sum(), mean(), max(), min(), count(), size(), describe()
import pandas as pd import numpy as np df_obj5 = pd.DataFrame(np.random.randint(1, 10, (5,5)), columns=[‘key1‘, ‘b‘, ‘c‘, ‘d‘, ‘e‘], index=[‘key1‘, ‘B‘, ‘C‘, ‘D‘, ‘E‘]) print(df_obj5.groupby(‘key1‘).sum()) print(df_obj5.groupby(‘key1‘).max()) print(df_obj5.groupby(‘key1‘).min()) print(df_obj5.groupby(‘key1‘).mean()) print(df_obj5.groupby(‘key1‘).size()) print(df_obj5.groupby(‘key1‘).count()) print(df_obj5.groupby(‘key1‘).describe())
效果:
b c d e key1 2 6 7 7 6 3 1 6 5 8 7 9 2 3 1 9 14 12 9 5 b c d e key1 2 6 7 7 6 3 1 6 5 8 7 9 2 3 1 9 9 8 8 3 b c d e key1 2 6 7 7 6 3 1 6 5 8 7 9 2 3 1 9 5 4 1 2 b c d e key1 2 6.0 7.0 7.0 6.0 3 1.0 6.0 5.0 8.0 7 9.0 2.0 3.0 1.0 9 7.0 6.0 4.5 2.5 key1 2 1 3 1 7 1 9 2 dtype: int64 b c d e key1 2 1 1 1 1 3 1 1 1 1 7 1 1 1 1 9 2 2 2 2 b ... e count mean std min 25% 50% ... std min 25% 50% 75% max key1 ... 2 1.0 6.0 NaN 6.0 6.0 6.0 ... NaN 6.0 6.00 6.0 6.00 6.0 3 1.0 1.0 NaN 1.0 1.0 1.0 ... NaN 8.0 8.00 8.0 8.00 8.0 7 1.0 9.0 NaN 9.0 9.0 9.0 ... NaN 1.0 1.00 1.0 1.00 1.0 9 2.0 7.0 2.828427 5.0 6.0 7.0 ... 0.707107 2.0 2.25 2.5 2.75 3.0 [4 rows x 32 columns]
grouped.agg(func)
func的参数为groupby索引对应的记录
import pandas as pd import numpy as np df_obj5 = pd.DataFrame(np.random.randint(1, 10, (5, 5)), columns=[‘key1‘, ‘b‘, ‘c‘, ‘d‘, ‘e‘], index=[‘key1‘, ‘B‘, ‘C‘, ‘D‘, ‘E‘]) df_obj = pd.DataFrame(np.random.randint(1, 10, (5,5)), columns=[‘key1‘, ‘b‘, ‘c‘, ‘d‘, ‘e‘], index=[‘key1‘, ‘B‘, ‘C‘, ‘D‘, ‘E‘]) # 自定义聚合函数 def peak_range(df): """ 返回数值范围 """ # print type(df) #参数为索引所对应的记录 return df.max() - df.min() print(df_obj5.groupby(‘key1‘).agg(peak_range)) print(df_obj.groupby(‘key1‘).agg(lambda df: df.max() - df.min()))
效果:
b c d e key1 1 0 0 0 0 2 0 0 0 0 5 0 0 0 0 9 6 3 4 5 b c d e key1 2 1 5 7 7 3 0 0 0 0 5 0 0 0 0 6 0 0 0 0
同时应用多个函数进行聚合操作,使用函数列表
import pandas as pd import numpy as np df_obj5 = pd.DataFrame(np.random.randint(1, 10, (5, 5)), columns=[‘key1‘, ‘b‘, ‘c‘, ‘d‘, ‘e‘], index=[‘key1‘, ‘B‘, ‘C‘, ‘D‘, ‘E‘]) df_obj = pd.DataFrame(np.random.randint(1, 10, (5,5)), columns=[‘key1‘, ‘b‘, ‘c‘, ‘d‘, ‘e‘], index=[‘key1‘, ‘B‘, ‘C‘, ‘D‘, ‘E‘]) # 自定义聚合函数 def peak_range(df): """ 返回数值范围 """ # print type(df) #参数为索引所对应的记录 return df.max() - df.min() # 应用多个聚合函数 # 同时应用多个聚合函数 print(df_obj.groupby(‘key1‘).agg([‘mean‘, ‘std‘, ‘count‘, peak_range])) # 默认列名为函数名 print(df_obj.groupby(‘key1‘).agg([‘mean‘, ‘std‘, ‘count‘, (‘range‘, peak_range)])) # 通过元组提供新的列名
效果:
b c ... d e mean std count peak_range mean ... peak_range mean std count peak_range key1 ... 1 4 NaN 1 0 3 ... 0 8 NaN 1 0 2 5 NaN 1 0 9 ... 0 5 NaN 1 0 7 4 NaN 1 0 4 ... 0 7 NaN 1 0 8 2 NaN 1 0 8 ... 0 7 NaN 1 0 9 5 NaN 1 0 8 ... 0 8 NaN 1 0 [5 rows x 16 columns] b c ... d e mean std count range mean std count ... std count range mean std count range key1 ... 1 4 NaN 1 0 3 NaN 1 ... NaN 1 0 8 NaN 1 0 2 5 NaN 1 0 9 NaN 1 ... NaN 1 0 5 NaN 1 0 7 4 NaN 1 0 4 NaN 1 ... NaN 1 0 7 NaN 1 0 8 2 NaN 1 0 8 NaN 1 ... NaN 1 0 7 NaN 1 0 9 5 NaN 1 0 8 NaN 1 ... NaN 1 0 8 NaN 1 0 [5 rows x 16 columns]
import pandas as pd import numpy as np df_obj = pd.DataFrame(np.random.randint(1, 10, (5, 5)), columns=[‘a‘, ‘b‘, ‘c‘, ‘d‘, ‘e‘], index=[‘A‘, ‘B‘, ‘C‘, ‘D‘, ‘E‘]) # 应用多个聚合函数 # 每列作用不同的聚合函数 dict_mapping = {‘a‘: ‘mean‘, ‘b‘: ‘sum‘} print(df_obj.groupby(‘a‘).agg(dict_mapping)) print(‘--------‘) dict_mapping = {‘a‘: [‘mean‘, ‘max‘], ‘b‘: ‘sum‘} print(df_obj.groupby(‘a‘).agg(dict_mapping))
效果
a b a 2 2 8 4 4 4 5 5 3 7 7 7 -------- a b mean max sum a 2 2 2 8 4 4 4 4 5 5 5 3
import pandas as pd import numpy as np dict_obj = {‘key1‘ : [‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘a‘], ‘key2‘ : [‘one‘, ‘one‘, ‘two‘, ‘three‘, ‘two‘, ‘two‘, ‘one‘, ‘three‘], ‘data1‘: np.random.randint(1, 10, 8), ‘data2‘: np.random.randint(1, 10, 8)} df_obj = pd.DataFrame(dict_obj) print(df_obj) # 按key1分组后,计算data1,data2的统计信息并附加到原始表格中,并添加表头前缀 k1_sum = df_obj.groupby(‘key1‘).sum().add_prefix(‘sum_‘) print(k1_sum)
效果:
key1 key2 data1 data2 0 a one 7 7 1 b one 4 9 2 a two 8 2 3 b three 6 3 4 a two 3 3 5 b two 3 3 6 a one 6 2 7 a three 9 1 sum_data1 sum_data2 key1 a 33 15 b 13 15
使用merge的外连接,比较复杂
# 方法1,使用merge k1_sum_merge = pd.merge(df_obj, k1_sum, left_on=‘key1‘, right_index=True) print(k1_sum_merge)
transform的计算结果和原始数据的形状保持一致,
如:grouped.transform(np.sum)
# 方法2,使用transform k1_sum_tf = df_obj.groupby(‘key1‘).transform(np.sum).add_prefix(‘sum_‘) df_obj[k1_sum_tf.columns] = k1_sum_tf print(df_obj)
也可传入自定义函数,
# 自定义函数传入transform def diff_mean(s): """ 返回数据与均值的差值 """ return s - s.mean() print(df_obj.groupby(‘key1‘).transform(diff_mean))
整体代码:
import pandas as pd import numpy as np dict_obj = {‘key1‘: [‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘b‘, ‘a‘, ‘a‘], ‘key2‘: [‘one‘, ‘one‘, ‘two‘, ‘three‘, ‘two‘, ‘two‘, ‘one‘, ‘three‘], ‘data1‘: np.random.randint(1, 10, 8), ‘data2‘: np.random.randint(1, 10, 8)} df_obj = pd.DataFrame(dict_obj) print(df_obj) # 按key1分组后,计算data1,data2的统计信息并附加到原始表格中,并添加表头前缀 k1_sum = df_obj.groupby(‘key1‘).sum().add_prefix(‘sum_‘) print(k1_sum) # 方法1,使用merge k1_sum_merge = pd.merge(df_obj, k1_sum, left_on=‘key1‘, right_index=True) print(k1_sum_merge) # 方法2,使用transform k1_sum_tf = df_obj.groupby(‘key1‘).transform(np.sum).add_prefix(‘sum_‘) df_obj[k1_sum_tf.columns] = k1_sum_tf print(df_obj) # 自定义函数传入transform def diff_mean(s): """ 返回数据与均值的差值 """ return s - s.mean() print(df_obj.groupby(‘key1‘).transform(diff_mean))
效果:
key1 key2 data1 data2 0 a one 9 8 1 b one 5 3 2 a two 3 5 3 b three 3 7 4 a two 3 3 5 b two 2 2 6 a one 4 2 7 a three 6 8 sum_data1 sum_data2 key1 a 25 26 b 10 12 key1 key2 data1 data2 sum_data1 sum_data2 0 a one 9 8 25 26 2 a two 3 5 25 26 4 a two 3 3 25 26 6 a one 4 2 25 26 7 a three 6 8 25 26 1 b one 5 3 10 12 3 b three 3 7 10 12 5 b two 2 2 10 12 key1 key2 data1 data2 sum_key2 sum_data1 sum_data2 0 a one 9 8 onetwotwoonethree 25 26 1 b one 5 3 onethreetwo 10 12 2 a two 3 5 onetwotwoonethree 25 26 3 b three 3 7 onethreetwo 10 12 4 a two 3 3 onetwotwoonethree 25 26 5 b two 2 2 onethreetwo 10 12 6 a one 4 2 onetwotwoonethree 25 26 7 a three 6 8 onetwotwoonethree 25 26 data1 data2 sum_data1 sum_data2 0 4.000000 2.8 0 0 1 1.666667 -1.0 0 0 2 -2.000000 -0.2 0 0 3 -0.333333 3.0 0 0 4 -2.000000 -2.2 0 0 5 -1.333333 -2.0 0 0 6 -1.000000 -3.2 0 0 7 1.000000 2.8 0 0
func函数也可以在各分组上分别调用,最后结果通过pd.concat组装到一起(数据合并)
import pandas as pd import numpy as np dataset_path = ‘./starcraft.csv‘ df_data = pd.read_csv(dataset_path, usecols=[‘LeagueIndex‘, ‘Age‘, ‘HoursPerWeek‘, ‘TotalHours‘, ‘APM‘]) def top_n(df, n=3, column=‘APM‘): """ 返回每个分组按 column 的 top n 数据 """ return df.sort_values(by=column, ascending=False)[:n] print(df_data.groupby(‘LeagueIndex‘).apply(top_n))
# apply函数接收的参数会传入自定义的函数中 print(df_data.groupby(‘LeagueIndex‘).apply(top_n, n=2, column=‘Age‘))
print(df_data.groupby(‘LeagueIndex‘, group_keys=False).apply(top_n))
apply可以用来处理不同分组内的缺失数据填充,填充该分组的均值。
整体代码:
import pandas as pd import numpy as np dataset_path = ‘./starcraft.csv‘ df_data = pd.read_csv(dataset_path, usecols=[‘LeagueIndex‘, ‘Age‘, ‘HoursPerWeek‘, ‘TotalHours‘, ‘APM‘]) def top_n(df, n=3, column=‘APM‘): """ 返回每个分组按 column 的 top n 数据 """ return df.sort_values(by=column, ascending=False)[:n] print(df_data.groupby(‘LeagueIndex‘).apply(top_n)) # apply函数接收的参数会传入自定义的函数中 print(df_data.groupby(‘LeagueIndex‘).apply(top_n, n=2, column=‘Age‘)) print(df_data.groupby(‘LeagueIndex‘, group_keys=False).apply(top_n))
标签:column 填充 多层 操作 数组 前缀 value rand false
原文地址:https://www.cnblogs.com/loaderman/p/11967365.html