标签:org 后台 integer ORC inf switch writable cas shuffle
1.Shuffle机制
1.1 什么是shuffle机制
1.1.1 在hadoop中数据从map阶段传递给reduce阶段的过程就叫shuffle,shuffle机制是整个MapReduce框架中最核心的部分;
1.1.2 shuffle翻译成中文的意思为:洗牌,发牌(核心机制:数据分区,排序,缓存)
1.2 shuffle的作用范围
一般把数据从map阶段输出到reduce阶段的过程叫shuffle,所以shuffle的作用范围是map阶段数据输出到reduce阶段数据输入这一整个中间过程;
1.3 shuffle图解
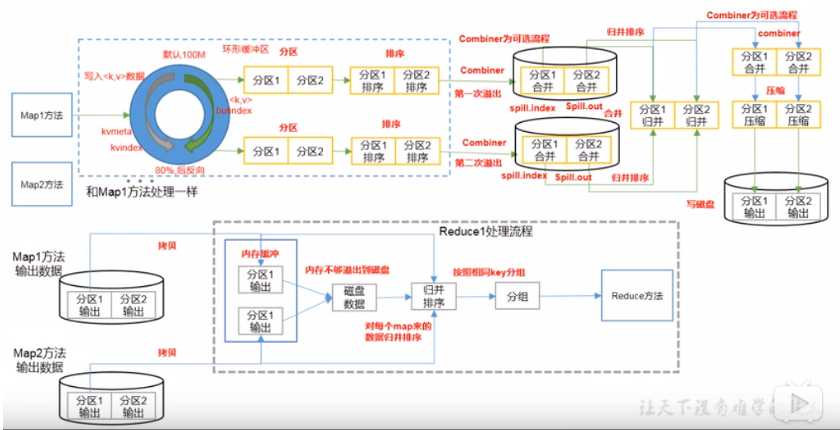
shuffle并不是hadoop的一个组件,只是map阶段产生数据输出到reduce阶段取得数据作为输入之前的一个过程;
1.4 shuffle的执行阶段流程
1.4.1 collect阶段:将mapTask的结果输出到默认大小为100的环形缓冲区,保存的是key/value序列化数据,partition分区信息等;
1.4.2 spill阶段:当内存中的数据量达到一定阈值的时候,就会将数据写入本地磁盘中,在将数据写磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序;
1.4.3 merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个mapTask最终值产生一个中间数据文件;
1.4.4 copy阶段:reducetask启动fetcher线程到已经完成mapTask的节点上复制一份属于自己的数据,这些数据默认会保存在内存缓冲区中,当内存的缓冲区达到一定阈值的时候,就会将数据写入磁盘中;
1.4.5 merge阶段:在reducetask远程复制数据的同时,会在后台开启两个线程(一个是内存到磁盘合并,一个是磁盘到磁盘合并)对内存到本地的数据文件进行合并操作;
1.4.6 sort阶段:在对数据进行合并的同时,会进行排序操作,由于mapTask阶段已经对数据进行了局部排序,reducetask只需保证copy的数据的最终整体有效性即可;
1.5 注意
shuffle中的缓冲区大小会影响到MapReduce程序的执行效率,原则上说,缓冲区越大,磁盘IO的次数越少,执行速度就越快,正是因为shuffle的过程中要不断的将文件从磁盘写入到内存,再从内存写入到磁盘,从而导致了hadoop中MapReduce执行效率相对于storm等一些实时计算来说比较低下的原因;
2.Partition分区
2.1 默认Partitioner分区
@Public @Stable public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> { public HashPartitioner() { } public void configure(JobConf job) { } public int getPartition(K2 key, V2 value, int numReduceTasks) { // key的hashcode值与Integer的最大值 在和reduceTask数量求余 return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; } }
默认分区是根据key的hashCode值对ReduceTasks的个数取模得到的;用户没法控制哪个key存储到哪个分区中;
2.2 分区总结
(1)如果reduceTask的数量>getPartition的结果数,则会产生几个空的输出文件part-r-000xx;
(2)如果1<ReduceTask的数量<getPartition的结果数,则有一部分分区数据无处安放,会发生异常;
(3)如果ReduceTask的数量=1,则不管mapTask端输出多少个分区文件,最终结果都交给这一个ReduceTask,最终也就会产生一个结果文件part-r-00000;
(4)分区号必须从零开始,逐一累加;
3.Partition分区案例实操
MyPartitioner类编写
package com.wn.partition; import com.wn.flow.FlowwBean; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; public class MyPartitioner extends Partitioner<Text, FlowwBean> { @Override public int getPartition(Text text, FlowwBean flowwBean, int i) { String phone = text.toString(); switch (phone.substring(0,3)){ case "136": return 0; case "137": return 1; case "138": return 2; case "139": return 3; default: return 4; } } }
PartitionDriver类编写
package com.wn.partition; import com.wn.flow.FlowMapper; import com.wn.flow.FlowReducer; import com.wn.flow.FlowwBean; import com.wn.wordcount.WcDriver; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class PartitionDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //获取一个Job实例 Job job = Job.getInstance(new Configuration()); //设置类路径 job.setJarByClass(PartitionDriver.class); //设置mapper和reducer job.setMapperClass(FlowMapper.class); job.setReducerClass(FlowReducer.class); //设置分区 job.setNumReduceTasks(5); job.setPartitionerClass(MyPartitioner.class); //设置mapper和reducer输出类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowwBean.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowwBean.class); //设置输入的数据 FileInputFormat.setInputPaths(job,new Path("E:\\input")); FileOutputFormat.setOutputPath(job,new Path("E:\\output")); //提交job boolean b = job.waitForCompletion(true); System.exit(b?0:1); } }
4.WritableComparable排序
排序是MapReduce框架中最重要的操作之一;
mapTask和reducetask均会对数据按照key进行排序;该操作属于hadoop的默认行为;任何应用程序中的数据均会被排序,而不管逻辑上是否需要;
默认排序是按照字典顺序排序,且实现该排序的方法是快速排序;
5.WritableComparable排序案例实操()
6.WritableComparable排序案例实操()
7.Combiner合并
8.Combiner合并案例实操
9.GroupingComparator分组(辅助。。。)
10.GroupingComparator分组案例实操
hadoop-MapReduce框架原理之Shuffle机制
标签:org 后台 integer ORC inf switch writable cas shuffle
原文地址:https://www.cnblogs.com/wnwn/p/12620764.html