标签:应该 with 可视化 表情 mes 形状 测量 间隔 度量
面部表情视频中进行远程心率测量:ICCV2019论文解析
Remote Heart Rate Measurement from Highly Compressed Facial Videos: an End-to-end Deep Learning Solution with Video Enhancement

论文链接:
摘要
远程光容积描记术(rPPG)是一种无接触测量心脏活动的方法,在许多应用领域(如远程医疗)具有巨大的潜力。现有的rPPG方法依赖于分析面部视频的非常详细的细节,这些细节容易受到视频压缩的影响。本文提出了一种利用隐藏的rPPG信息增强和注意力网络的两阶段端到端的方法,这是第一次尝试对抗视频压缩丢失和从高压缩视频中恢复rPPG信号。 The method includes two parts:
1) 用于视频增强的时空视频增强网络(STVEN),以及
2) 用于rPPG信号恢复的rPPG网络(rPPGNet)。
rPPGNet可以独立工作以实现鲁棒的rPPG测量,STVEN网络可以添加并联合训练以进一步提高性能,特别是在高度压缩的视频上。
在两个基准数据集上进行了综合实验,结果表明,
1) 该方法不仅对压缩后的高质量视频对具有优异的性能,
2) 它还可以很好地推广到只有压缩视频可用的新数据,这意味着在现实世界的应用前景广阔。
1. Introduction
心电图(ECG)和光体积描记器(PPG)是测量心脏活动的常用方法。这两种类型的信号对于医疗保健应用非常重要,因为它们提供了基本平均心率(HR)和更详细的信息,如心率变异性(HRV)。
然而,这些信号大多来自皮肤接触的ECG/BVP传感器,这可能会引起不适,不便于长期监测。为了解决这一问题,近年来,远程光容积描记术(rPPG)得到了迅速的发展,它的目标是在没有任何接触的情况下对心脏活动进行远程测量[4,12,19,18,31,32,22]。然而,以往的rPPG测量工作大多没有考虑到视频压缩的影响,而事实上,商业摄像机拍摄的大多数视频都是通过不同比特率的不同压缩编解码器进行压缩的。
最近,两篇文献[7,16]指出并证明了在使用不同比特率的压缩视频时,rPPG测量的性能有不同程度的下降。如图1(a)所示,由于视频压缩过程的帧内和帧间编码造成的信息丢失,从高压缩视频中测量的rPPG信号通常遭受噪声曲线形状和不准确的峰值位置。考虑到Internet上存储和传输的方便性,视频压缩是远程业务发展的必然趋势。因此,开发能够在高压缩视频上可靠工作的rPPG方法具有重要的实用价值。然而,还没有提出解决这一问题的办法。
为了解决这一问题,本文提出了一种基于隐藏rPPG信息增强和注意网络的两阶段端到端的方法,该方法可以有效地抵抗视频压缩丢失,并从高压缩的面部视频中恢复rPPG信号。图1(b)说明了本文从高压缩视频中测量rPPG的方法的优点。本文的贡献包括: •据本文所知,本文提供了第一个直接从压缩视频进行鲁棒rPPG测量的解决方案,这是一个端到端的框架,由视频增强模块STVEN(时空视频增强网络)和强大的信号恢复模块rPPGNet组成。
•rPPGNet具有基于皮肤的注意模块和划分约束,可以在HR和HRV两个水平上精确测量。与以往只输出简单的HR数的工作相比,所提出的rPPGNet能够产生更丰富的具有曲线形状和峰值位置的rPPG信号。此外,即使不使用STVEN模块,它在基准数据集的各种视频格式上也优于最新的方法。
•STVEN是一个视频到视频转换生成器,有助于细粒度学习,它是第一个视频压缩增强网络,用于提高对高度压缩视频的rPPG测量。
•本文进行了跨数据集测试,结果表明,STVEN能够很好地泛化以增强用于rPPG测量的不可见的、高度压缩的视频,这意味着在实际应用中具有潜在的应用前景。
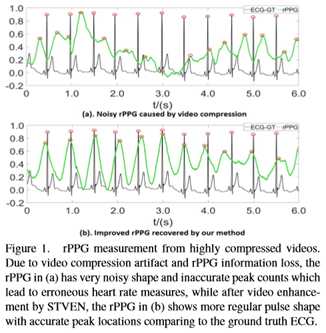
2. Related Work
远程光容积描记测量。
在过去的几年中,一些传统的方法通过分析面部感兴趣区域(ROI)的细微颜色变化来探索视频中rPPG的测量,包括盲源分离[19,18]、最小均方[12]、多数投票[10]和自适应矩阵完成[31]。然而,这些作品中的ROI选择是定制的或任意的,这可能会导致信息丢失。理论上讲,所有皮肤像素都有助于rPPG信号的恢复。还有其他利用所有皮肤像素进行rPPG测量的传统方法,例如基于色度的rPPG(CHROM)[4]、与肤色正交的投影平面(POS)[35]和空间子空间旋转[36、34、13]。所有这些方法对每个皮肤像素的贡献都是相等的,这与不同的皮肤部位对rPPG的恢复所承受的权重不同是背道而驰的。 最近,有人提出了一些基于深度学习的平均心率估计方法,包括synrhethm[17]、HR-CNN[25]和DeepPhys[3]。卷积神经网络(CNN)也被用于皮肤分割[2,28],然后从皮肤区域预测HR。这些方法都是基于空间二维CNN,无法捕捉rPPG测量所必需的时间特征。此外,皮肤分割任务与rPPG恢复任务是分开处理的,这两个高度相关的任务之间缺乏相互的特征共享。
视频压缩及其对rPPG的影响。
在实际应用中,视频压缩以其存储容量大、质量退化小等优点得到了广泛的应用。作为运动图像专家组(MPEG)和国际电信联盟电信标准化部门(ITU-T)的标准,已经开发了许多视频压缩编解码器。其中包括MPEG-2第2部分/H.262[8]和低比特率标准MPEG-4第2部分/H.263[21]。当前一代标准AVC/H.264[37]在编码效率上比H.262和H.263大约提高了一倍。最近,下一代标准HEVC/H.265[27]采用了越来越复杂的编码策略,使编码效率比H.264提高了一倍左右。在视频编码阶段,量化的结果不可避免地会产生压缩伪影。具体来说,现有的压缩标准减少了人眼看不见的细微变化。它不利于rPPG测量的目的,rPPG测量主要依赖于不可见水平上的细微变化。视频压缩对rPPG测量的影响直到最近才被研究。三项工作[7,16,24]一致证明压缩伪影确实降低了HR估计的准确性。然而,这些工作仅在使用传统方法的小规模私有数据集上进行了测试,并且还不清楚压缩是否也影响了大数据集上基于深度学习的rPPG方法。此外,这些工作只是指出了rPPG的压缩问题,但还没有提出解决方案。
压缩视频的质量增强。
在深度学习的高性能推动下,一些研究者将其引入到压缩视频的质量提升中,取得了很好的效果,包括ARCNN[5]、深度残差去噪神经网络(DnCNN)[39]、生成性对抗网络[6]和多帧质量提升网络[38]。然而,它们都是为解决一般的压缩问题或其他任务(如目标检测)而设计的,而不是为rPPG测量而设计的。关于从低质量视频中恢复rPPG,有两部著作[1540]。[15]关注的是帧分辨率,而不是视频压缩和格式。另一种方法[40]试图解决压缩视频中的rPPG问题,但该方法仅在提取rPPG后的生物信号处理水平上进行,与视频增强无关。据本文所知,目前还没有针对高压缩视频中rPPG恢复问题的视频增强方法。
为了克服上述缺点和空白,本文提出了一种基于高压缩视频的两阶段端到端的基于深度学习的RPPG测量方法。
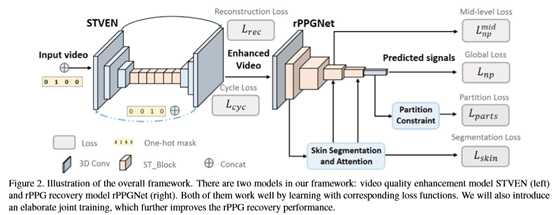
3. Methodology
作为一种两阶段端到端的方法,本文将首先在第3.1节中介绍本文的视频增强网络STVEN,然后在第3.2节中介绍rPPG信号恢复网络rPPGNet,最后说明如何联合训练这两部分以提高性能。总体框架如图2所示。
3.1. STVEN
为了提高高压缩视频的质量,本文提出了一种称为时空视频增强网络(STVEN)的视频到视频生成器,如图2的左边所示。这里,本文通过假设来自不同压缩比特率的压缩伪影具有不同的分布来执行细粒度学习。结果,压缩视频被放入基于其压缩比特率表示为C的bucket[0,1,2,…,C]中。这里,0和C分别表示压缩率最低和最高的视频。
本文用时空卷积神经网络建立了模型STVEN。该体系结构由两个下采样层和两个上采样层在两端组成,中间有六个时空块。体系结构的详细信息显示在表1的顶部。
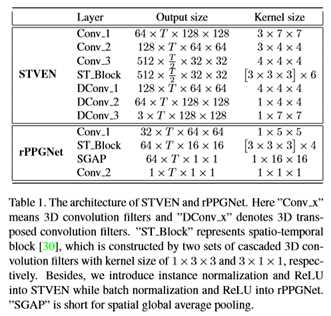
3.2. rPPGNet
提出的rPPGNet由时空卷积网络、基于皮肤的注意模块和分区约束模块组成。基于皮肤的注意有助于自适应地选择皮肤区域,并引入分割约束来学习更好的rPPG特征表示。
时空卷积网络。
以前的工作,如[4,35],通常投影空间池RGB到另一个颜色空间,以更好地表示rPPG信息。然后采用基于时间上下文的规范化方法去除不相关信息(如光照或运动引起的噪声)。本文将这两个步骤合并为一个模型,提出了一种以RGB通道的T帧人脸图像为输入,直接输出rPPG信号的端到端时空卷积网络。rPPGNet的主干网和体系结构如图2和表1所示。为了恢复rPPG信号y∈RT,与相应的地面真值ECG信号yg∈RT相比,该信号应具有准确的脉冲峰值位置,采用负Pearson相关来定义损失函数。它可以表述为
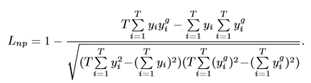
与均方误差(MSE)不同,本文的损失是最小化线性相似性误差而不是逐点强度误差。本文在先前的测试中尝试了MSE损失,由于信号的强度值与本文的任务无关(即测量准确的峰值位置),并且不可避免地引入了额外的噪声,因此获得了更差的性能。
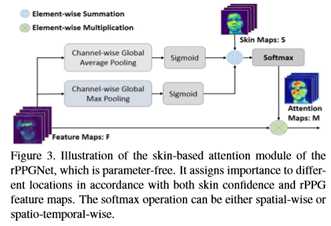
皮肤分割和注意。 不同的皮肤区域有不同的血管密度和生物物理参数图(黑色素和血红蛋白),因此对rPPG信号的测量有不同程度的贡献。因此,皮肤分割任务与rPPG信号恢复任务密切相关。这两个任务可以看作是一个多任务学习问题。因此,本文在第一个块之后使用皮肤分割分支。皮肤分割分支将共享的低层时空特征投影到皮肤域中,皮肤域通过空间和信道卷积以及剩余连接来实现。由于相关的rPPG数据集中没有地面真皮肤图,因此本文通过自适应皮肤分割算法为每个帧生成二值标签[29]。模块如图3所示。
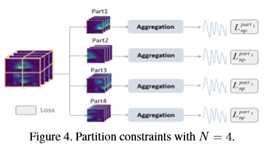
分区约束。
为了帮助模型学习更集中的rPPG特征,引入了局部划分约束。如图4所示, 分区损失可以被认为是高级功能的一个退出[26]。它具有正则化效应,因为每个分割损失彼此独立,从而迫使部分特征足够强大,以恢复rPPG信号。也就是说,通过划分约束,模型可以更集中于rPPG信号而不是干扰。总之,rPPGNet的损失函数可以写成
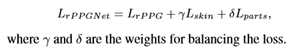
3.3. Joint Loss Training
当STVEN与rPPGNet分开训练时,输出的视频不能保证后者的有效性。受[14]的启发,本文设计了一个高级联合训练策略,以确保STVEN能够特别增强视频,有利于rPPG恢复,这将提高rPPGNet的性能,即使是在高度压缩的视频上。 首先,本文使用第3.2节中描述的训练方法在高质量视频上训练rPPGNet。 其次,本文用不同比特率的压缩视频训练STVEN。
最后,本文训练级联网络,如图2所示,所有高级任务模型参数都是固定的。 因此,以下所有损失函数
是为更新STVEN而设计的。在这里,本文采用面向应用程序的联合训练,本文更喜欢端到端的性能,而不是两个阶段的性能。
在这种训练策略中,本文去掉了循环丢失部分,因为本文期望STVEN在视频压缩过程中恢复更丰富的rPPG信号而不是无关的信息丢失。
因此,本文只需要知道它的目标标签,所有输入到STVEN的视频的压缩标签可以简单地设置为0作为默认值。这使得该模型更具通用性,因为它不需要对输入视频进行主观压缩标记,因此可以对压缩率不明确的新视频进行处理。

4. Experiments
本文在四个子实验中测试了该系统,前三个在OBF[11]数据集上,最后一个在MAHNOB-HCI[23]数据集上。
首先,本文在OBF上评估rPPGNet的平均HR和HRV特征度量。
其次,本文压缩OBF视频,并探讨视频压缩对rPPG测量性能的影响。
再次,本文证明了STVEN可以增强压缩视频,提高OBF上rPPG的测量性能。 最后,在MAHNOBHCI上对STVEN和rPPGNet的联合系统进行了交叉测试,验证了系统的通用性。
4.1. Datasets and Setting
视频以61fps的速度录制,分辨率780x580,压缩格式为AVC/H.264,平均比特率≈4200kb/s,实验评价采用EXG2信号作为地面真实心电图。本文遵循与之前的工作相同的程序[17,25,3]并使用每个视频的30秒(第306到2135帧)。
使用最新版本的FFmpeg[1]执行视频压缩。为了实现三种主流压缩标准(H.263、H.264和H.265),本文使用了三种编解码器(MPEG4、x264和x265)。为了证明STVEN对高压缩视频(即文件大小较小且比特率低于1000 kb/s)的影响,本文将OBF视频压缩为三个质量级别,即平均比特率(文件大小)=1000 kb/s(36.4 MB)、500 kb/s(18.2 MB)和250 kb/s(9.1 MB)。比特率(文件大小)分别是原始视频的20、40和80倍。
4.2. Implementation Details
训练环境。
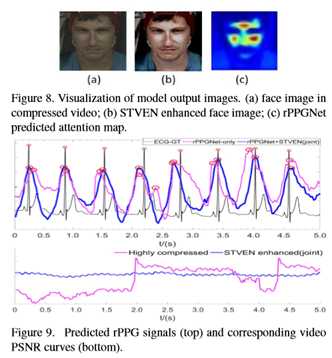
对于所有的面部视频,本文使用Viola Jones面部检测器[33]来检测和裁剪粗糙的面部区域(见图8(a))并移除背景。本文通过开源Bob1生成二元皮肤面具,阈值为0.3作为基本真相。所有人脸和皮肤图像分别标准化为128x128和64x64。
绩效指标。
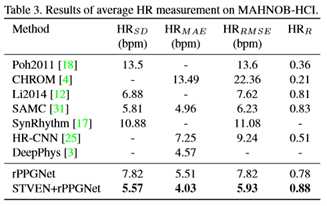
为了评估恢复的rPPG信号的准确性,本文遵循了先前的工作[11,17],在OBF数据集上报告了平均HR和几个常见的HRV特征,然后在MAHNOB-HCI数据集上评估了几个平均HR测量指标。计算了四个常用的HRV特征[11,18]进行评估,包括呼吸频率(RF)(单位:Hz)、低频(LF)、高频(HF)和低频/高频(单位:标准化单位:n.u.)。
恢复的rPPGs和它们对应的地面真值ecg都经过相同的滤波、归一化和峰值检测过程来获得拍间间隔,从中计算平均HR和HRV特征。
本文报告了最常用的绩效评估指标,包括:标准差(SD)、均方根误差(RMSE)、皮尔逊相关系数(R)和平均绝对误差(MAE)。用△PSNR评价增强前后视频质量的变化。
4.3. Results on OBF
OBF有大量高质量的视频片段,适合于验证本文的方法在平均HR和HRV水平上的稳健性。本文执行独立于受试者的10倍交叉验证方案来评估OBF数据集上的rPPGNet和STVEN。在测试阶段,根据30秒长的输出rPPG信号计算平均HR和HRV特征。
rPPGNet对高质量视频的评价。
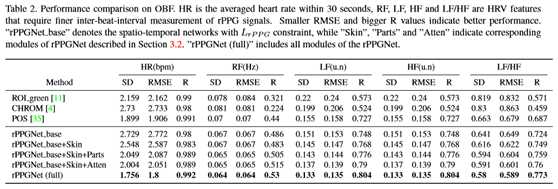
在这里,本文在原始的OBF视频上重新实现了几种传统的方法[4,11,35],并将结果与表2中的结果进行了比较。结果表明,rPPGNet(full)在平均HR和HRV特征上均优于其它方法。
从融合试验结果可以得出结论:
1) 皮肤分割模块(表2中的第五行)。多任务学习的性能略有提高,说明这两个任务可能具有相互隐藏的信息。
2) 分区模块(表2中的第六行)通过帮助模型学习更集中的特性,进一步提高了性能。
3) 基于皮肤的注意力教会网络去哪里看,从而提高性能。在本文的观察中,基于空间的softmax操作的空间注意比时空注意效果更好,因为在rPPG恢复任务中,不同帧的权重应该非常接近。
rPPGNet对高压缩视频的评价。
本文使用第4.1节中描述的三个编解码器(MPEG4、x264和x265)将OBF视频压缩为三个比特率级别(250、500和1000 kb/s),因此本文有九组(3×3)高度压缩的视频。本文使用10倍交叉验证,对9组视频中的每一组分别使用rPPGNet和其他三种方法进行评估。
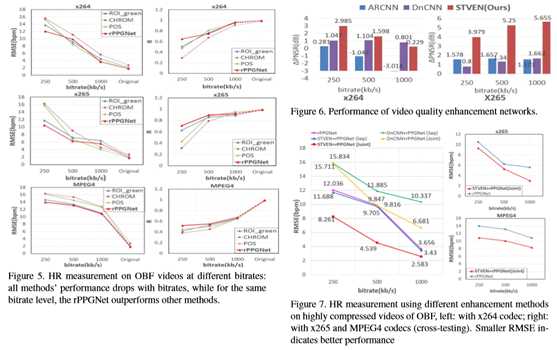
结果如图5所示。从图中本文可以看到,
第一,当比特率降低时,传统方法和rPPGNet的性能都会下降,这对所有三种压缩编解码器都是正确的。观察结果与之前的研究结果一致[16,24],并证明压缩确实影响rPPG的测量。
其次,重要的结果是,在相同的压缩条件下,rPPGNet在大多数情况下都能优于其他方法,特别是250kb/s的极低比特率,这证明了rPPGNet的鲁棒性。但是在低比特率下的准确率并不令人满意,本文希望通过视频增强来进一步提高性能,即使用所提出的STVEN网络。
用STVEN评价rPPGNet对高压缩视频的增强效果。
首先,本文证明了基于△PSNR的STVEN确实在总体上提高了视频质量。如图6所示,经STVEN增强的视频的△PSNR大于零,表明质量得到了提高。本文还将STVEN与其他两种增强网络(ARCNN[5]和DnCNN[39])进行了比较,STVEN获得的△PSNR比其他两种方法更大。
然后将STVEN与rPPGNet级联,验证了视频增强模型能够提高rPPGNet的HR测量性能。本文在x264压缩视频上比较了两种增强网络(STVEN与DnCNN[39])和两种训练策略(单独训练与联合训练)的性能。单独的训练意味着增强网络预先训练在高度压缩的视频上,rPPGNet预先训练在高质量的原始视频上,而联合训练则调整两个单独训练的结果,两个任务同时丢失。
图7(左)的结果表明:对于高压缩视频的rPPG恢复和HR测量,
1) STVEN有助于提高rPPGNet的性能,而DnCNN没有;以及
2) 联合训练比单独训练效果好。令人惊讶的是,STVEN在单独训练模式和联合训练模式下都能增强rPPGNet,而DnCNN[39]在单独训练模式和联合训练模式下都能抑制rPPGNet,这可能是由于STVEN具有细粒度学习的优良时空结构和DnCNN单帧模型的局限性所致。
STVEN-rPPGNet的泛化能力如图7(右)所示,其中在x264视频上训练的联合系统在MPEG4和x265视频上进行了交叉测试。由于STVEN的质量和rPPG信息增强,rPPGNet能够通过MPEG4和x265压缩从未经训练的视频中测量更精确的HR。
4.4. Results on MAHNOB-HCI
为了验证本文的方法的通用性,本文在MAHNOB-HCI数据集上对本文的方法进行了评估。MAHNOB-HCI是HR测量中应用最广泛的数据集,由于其高压缩率和自发运动(如面部表情),视频样本具有挑战性。采用独立于受试者的9倍交叉验证方案(一次3名受试者,共27名受试者)。由于没有原始的高质量视频可用,STVEN在OBF firstly上使用x264高压缩视频进行训练,然后与MAHNOB-HCI上训练的rPPGNet级联进行测试。与表3中的最新方法相比,本文的rPPGNet在主观无关协议方面优于基于深度学习的方法[17,25]。借助于STVEN丰富的rPPG信息进行视频增强,本文的两阶段方法(STVEN+rPPGNet)优于其他所有方法。这表明即使没有高质量的视频,STVEN也可以交叉提高性能。
4.5. Visualization and Discussion
在图8中,本文将一个示例可视化,以显示STVEN+rPPGNet方法的可解释性。来自rPPGNet图8(c)的预测注意图聚焦于具有最强rPPG信息的皮肤区域(例如,前额和脸颊),这与[32]中提到的先验知识一致。
如图8(b)所示,STVEN增强的面部图像似乎在相似的皮肤区域具有更丰富的rPPG信息和更强的脉动流,这表明图8(c)的一致性。
本文还将rPPGNet恢复的rPPG信号标绘在有或无STVEN的高压缩视频上。如图9(顶部)所示,得益于STVEN的增强,预测信号具有更精确的IBIs。此外,图9(底部)显示了具有STVEN增强的高压缩视频的较低客观质量(PSNR)表现,这似乎有助于恢复更平滑和稳健的rPPG信号。
5. Conclusions and Future Work
本文提出了一种基于端到端深度学习的高压缩视频rPPG信号恢复方法。利用STVEN对视频进行增强,并将rPPGNet级联以恢复rPPG信号以进行进一步的测量。在未来,本文将尝试使用与压缩相关的度量,如PSNR-HVS-M[20]来约束增强模型STVEN。此外,本文还将探索建立一种新的视频质量评估指标的方法,特别是用于rPPG恢复。
标签:应该 with 可视化 表情 mes 形状 测量 间隔 度量
原文地址:https://www.cnblogs.com/wujianming-110117/p/12625462.html