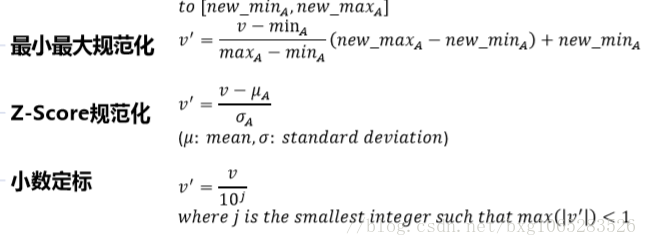标签:中心 国家 线性回归 算法 数据共享 ase 原来 reg nts
1.数据预处理
2.数据清洗
3.数据集成
4.数据归约
5.数据变换
6.数据离散化
7.大数据预处理
①不完整 缺少属性值或仅仅包含聚集数据
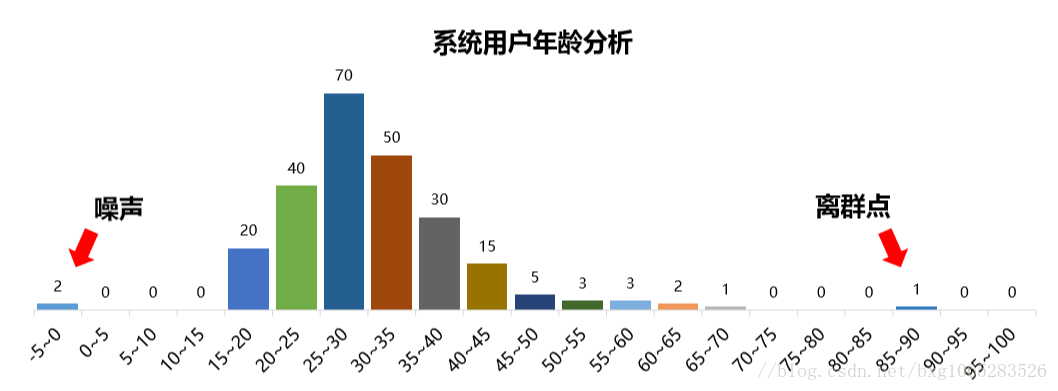
②含噪声 包含错误或存在偏离期望的离群值 比如:salary=“-10”,明显是错误数据
③不一致 用于商品分类的部门编码存在差异 比如age=“42”Birthday=“03/07/1997”
而我们在使用数据过程中对数据有如下要求:
一致性、准确性、完整性、时效性、可信性、可解释性
由于获得的数据规模太过庞大,数据不完整、重复、杂乱,在一个完整的数据挖掘过程中,数据预处理要花费60%左右的时间。
1.缺失值的处理:
①忽略元组:若有多个属性值缺失或者该元祖剩余属性值使用价值较小时,应选择放弃
②人工填写:该方法费时,数据庞大时行不通
③全局常量填充:方法简单,但有可能会被挖掘程序愚以为形成了又去的概念
④属性中心度量填充:对于正常的数据分布而言可以使用均值,而倾斜数据分布应使用中位数
⑤最可能的值填充:使用回归、基于推理的工具或者决策树归纳确定。
2.噪声数据与离群点:
噪声:被测量的变量的随机误差或者方差(一般指错误的数据)
离群点:数据集中包含一些数据对象,他们与数据的一般行为或模型不一致。(正常值,但偏离大多数数据)
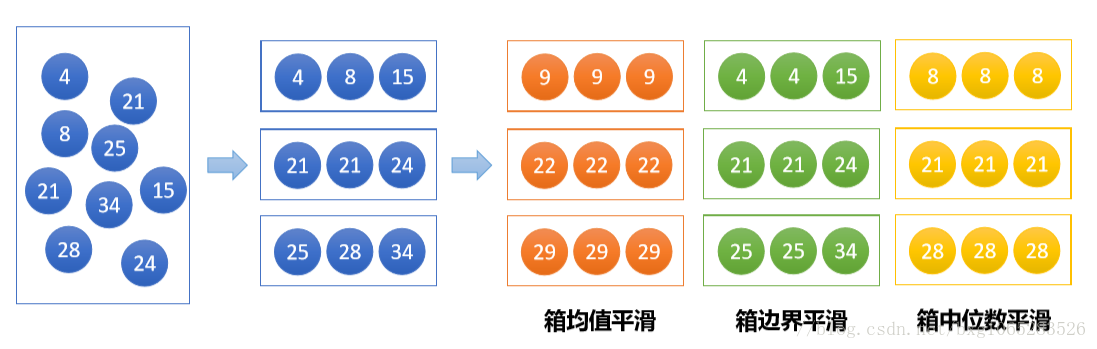
分箱(binning):通过考察数据周围的值来光滑有序数据值,这些有序的值被分布到一些“桶”或箱中,由于分箱方法只是考虑近邻的值,因此是局部光滑。
分箱的方法:
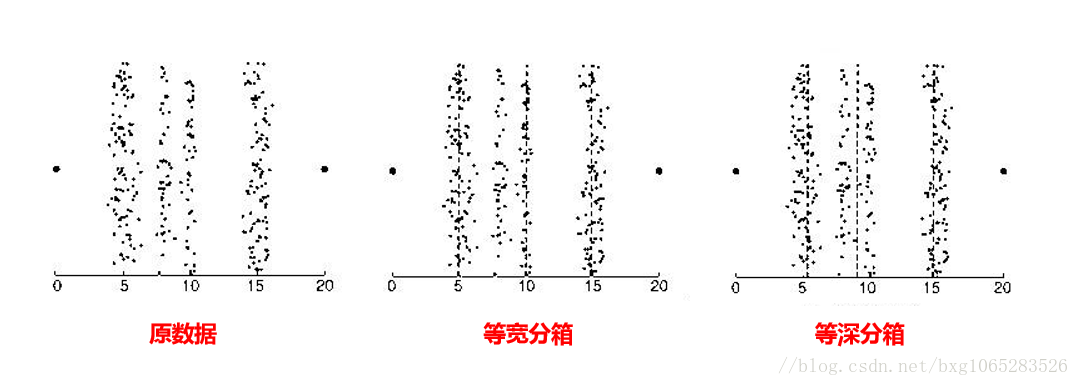
等宽分箱:每个“桶”的区间宽度相同
等深分箱:每个“桶”的样本个数相同
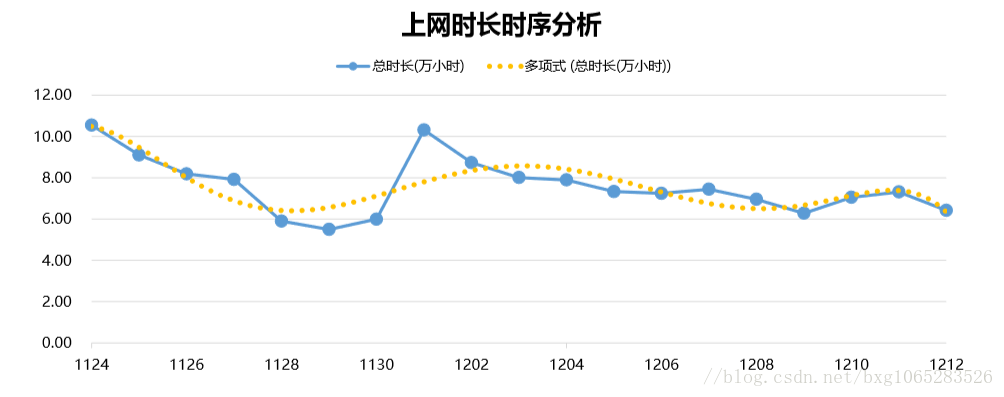
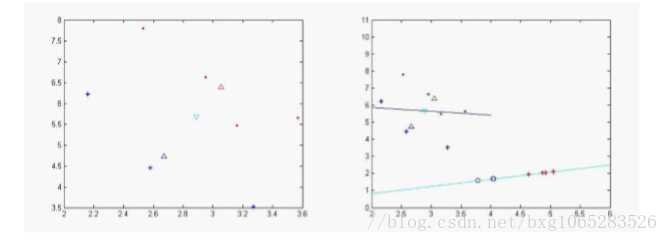
回归(regression):用一个函数拟合数据来光滑数据。
线性回归找出拟合两个属性(变量)的最佳直线;多元线性回归涉及多个属性,将数据拟合到多维曲面
下图即对数据进行线性回归拟合:
离群点:
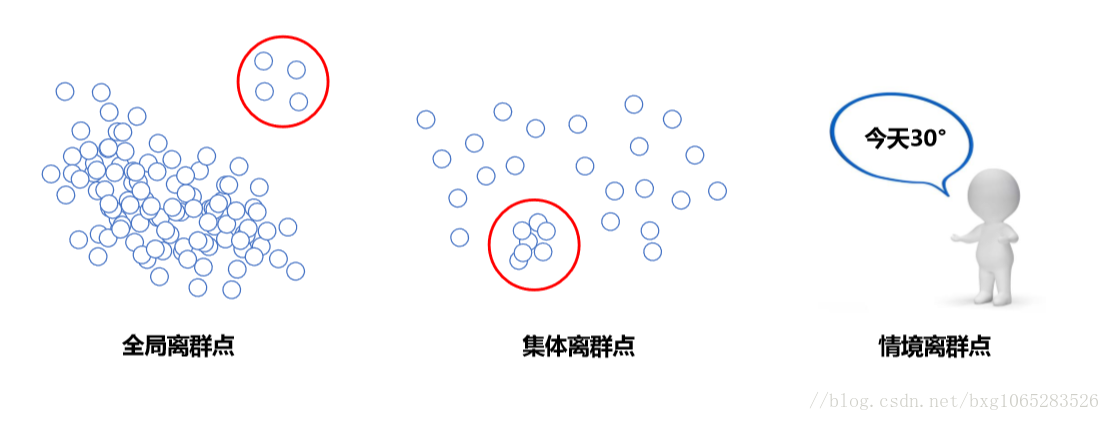
2.1 离群点的分类
①全局离群点:个别数据离整体数据较远
②集体离群点:一组数据与其他数据分布方式不同
③情景离群点
2.2 离群点检测的方法
①基于统计的离群点检测:假设给定的数据集服从某一随机分布(如正态分布等),用不一致性测试识别异常。
如果某个样本点不符合工作假设,那么认为它是离群点;如果它符合备选假设,则认为它是符合某一备选假设分布的离群点。
②基于密度的局部离群点检测:通过基于局部离群点检测就能在样本空间数据分布不均匀的情况下也可以准确发现。
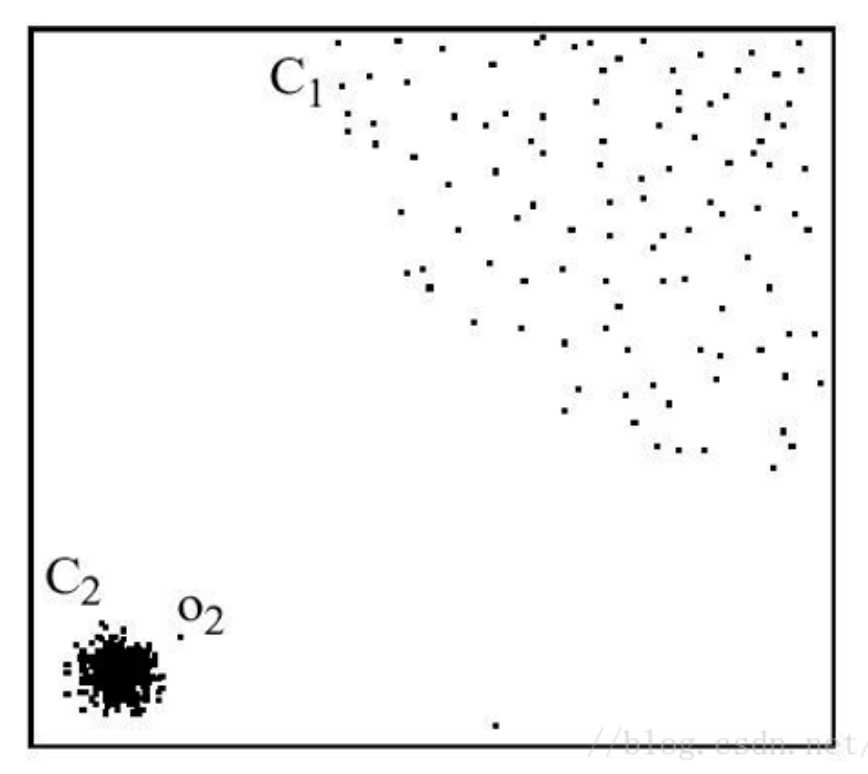
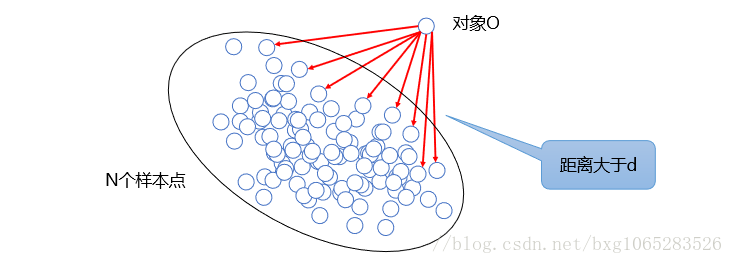
③基于距离的离群点检测:如果样本空间D至少有N个样本点与对象O的距离大于d,那么对象O是以至少N个样本点和距离d为参数的基于距离的离群点。
④基于偏差的离群点检测:通过检查一组对象的主要特征来识别离群点,那些些不符合这种特征的数据对象被判定为离群点。
2.3 传统离群点检测的缺点:
①基于统计的算法:不适合多维空间,预先要知道样本空间中数据集的分布特征
②基于距离的算法:参数的选取非常敏感,受时间复杂度限制,不适用于高维稀疏数据集。
③基于偏差的算法:实际应用少,在高维数据集中,很难获得该数据集的主要特征。
1.数据属性
①标称属性:属性值是一些符号或事物的名称,经常看做分类属性,如头发颜色:黄色、黑色、棕色
②二元属性:是一种标称属性,只有两个类别 0或1 true or false
③序数属性:其可能的值时间具有有意义的序或秩评定,如客户满意度:0-很满意 1-不能太满意...
④数值属性:定量的,可度量的量,用整数换实数值表示。
2.离散属性与连续属性
1.离散属性:具有有限或无限可数个值,可以是数值属性,如性别、员工号
2.连续属性:非离散的,一般用浮点变量表示。
3.数据集成
数据集成是把不同来源、格式、特点性质的数据在逻辑上或物理上有机的集中,从而为企业提供全面的数据共享。数据集成时,模式集成和对象匹配非常重要,如何将来自于多个信息源的等价实体进行匹配即实体识别问题。
在进行数据集成时,同一数据在系统中多次重复出现,需要消除数据冗余,针对不同特征或数据间的关系进行相关性分析。
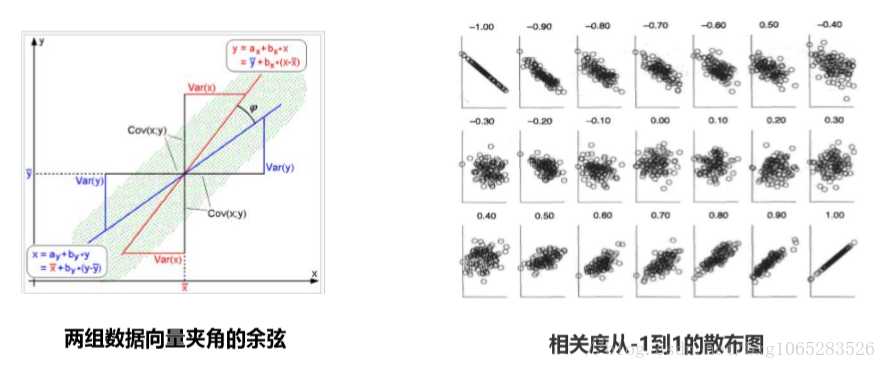
相关性分析时用皮尔逊相关系数度量, 用于度量两个变量X和Y之间得相关(线性相关),其值介于1和-1之间。
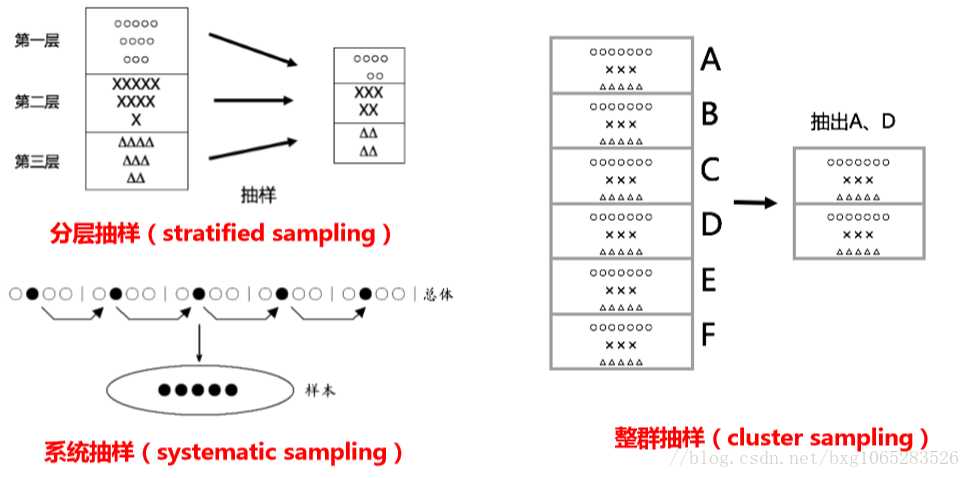
1.数据规约策略
①维规约:减少考虑的随机变量或属性的个数,或把原数据变换或投影到更小的空间,具体方法:小波变换、主成分分析等。
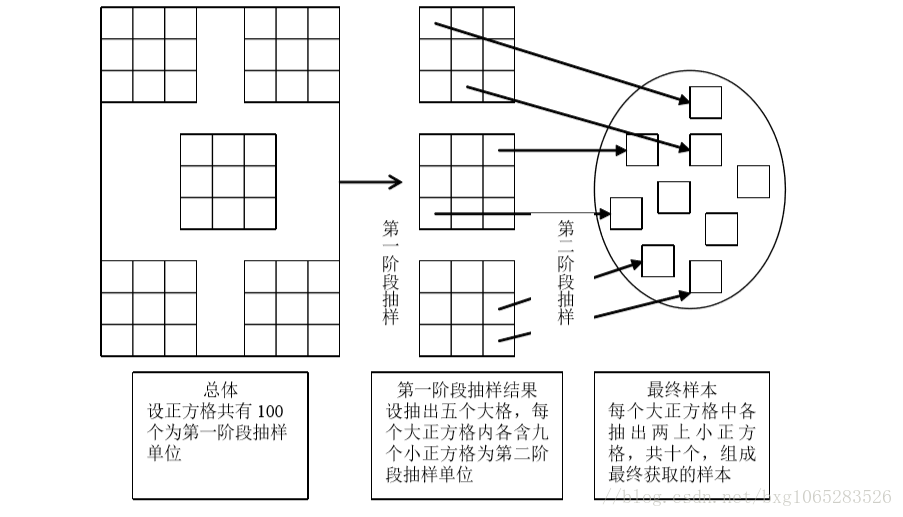
②数量规约:用替代的、较小的数据表示形式替换原数据 具体方法包括:抽样和数据立方体聚集
③数据压缩:无损压缩:能从压缩后的数据重构恢复原来的数据,不损失信息。有损压缩:只能近似重构原数据。
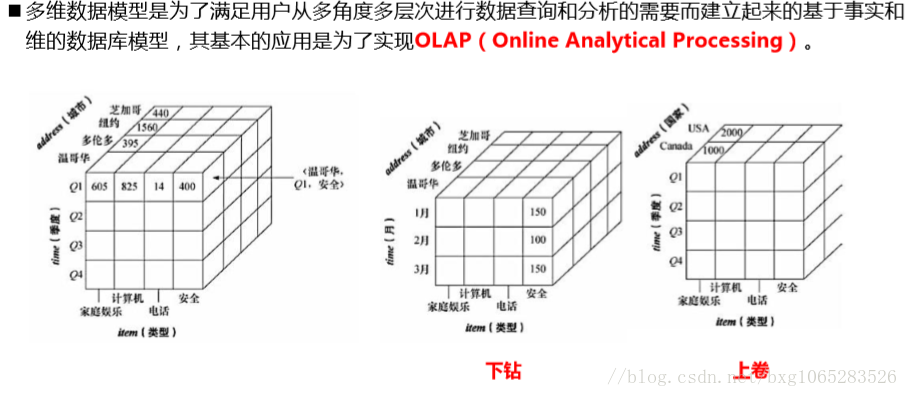
下钻是将一个大范围度量细化,如图将季度分成月份表示,上卷与其相反,将城市上卷为国家。
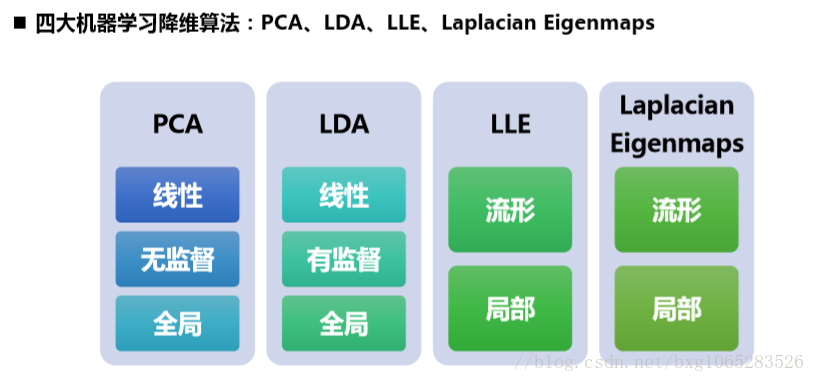
2.机器学习中的降维方法:
3.主成分分析法---线性降维方法
在降维之后能最大程度的保持数据的内在信息,通过衡量在投影方向上的数据方差大小来衡量该方向的重要程度。

4.线性判别分析----有监督的线性降维方法
数据在降维后能很容易得被区分开,将高维的模式样本投影到最佳鉴别矢量空间,保证模式样本在新子空间内有最大类间距离和最小的类内距离,即模式在该空间中有最佳的可分离性。
5.局部线性嵌入LLE----非线性降维方法
能使降维后的数据保持原有的流形结构。如果数据分布在整个封闭的球面上,LLE则不能将其映射到二维空间,且不能保持原有的数据流形,于是在处理数据时首先要保证数据不在封闭的球面或者椭圆内。
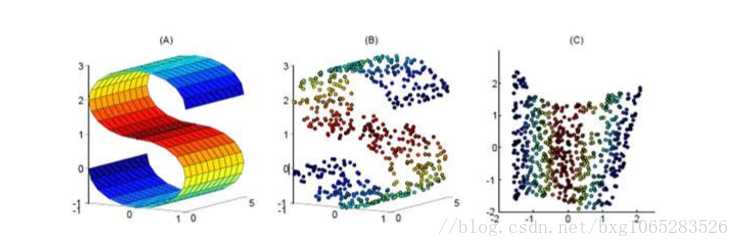
图示将三维曲面数据映射到二维坐标轴内,还能保证其大致的流线型。
1.数据变换策略
①光滑:去掉噪声,包括分箱、回归、聚类。
②属性构造:由改定的属性构造新的属性,并添加到属性集中
③聚集:对数据进行汇总或聚集,通常为多个抽象层的数据分析构造数据立方体。
④规范化:按比例缩放,使之落入特定的小区间内。
⑤离散化:属性的原始值用区间标签或概念标签替换。
⑥由标称数据产生概念分层:将标称属性泛化到较高的概念层。
2.规范化方法
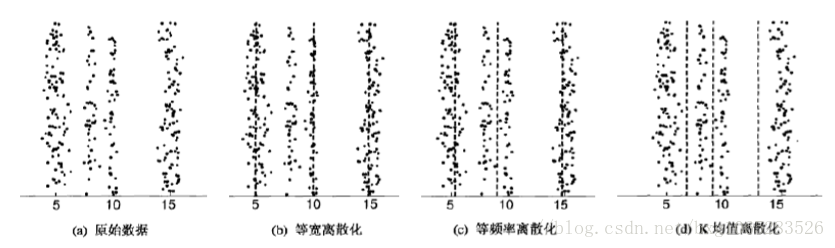
1.非监督离散化:在离散过程中不考虑类别属性,其输入数据集仅含有待离散化属性的值。
假设属性的取值空间为X={X1,X2,?,Xn},离散化之后的类标号是Y={Y1,Y2,?,Ym},则无监督离散化的情况就是X已知而Y未知。以下介绍几种常用的无监督离散化方法:
(1) 等宽算法
根据用户指定的区间数目K,将属性的值域[Xmin−Xmax]划分成K个区间,并使每个区间的宽度相等,即都等于Xmax−XminK。缺点是容易受离群点的影响而使性能不佳。
(2) 等频算法
等频算法也是根据用户自定义的区间数目,将属性的值域划分成K个小区间。他要求落在每个区间的对象数目相等。譬如,属性的取值区间内共有M个点,则等频区间所划分的K个小区域内,每个区域含有MK个点。
(3) K-means聚类算法
首先由用户指定离散化产生的区间数目K,K-均值算法首先从数据集中随机找出K个数据作为K个初始区间的重心;然后,根据这些重心的欧式距离,对所有的对象聚类:如果数据x距重心Gi最近,则将x划归Gi所代表的那个区间;然后重新计算各区间的重心,并利用新的重心重新聚类所有样本。逐步循环,直到所有区间的重心不再随算法循环而改变为止。
2.监督离散化:输入数据包括类别信息(类标号),效果比无监督好,主要有以下几种方法。
(1) 齐次性的卡方检验
1 Hadoop-集群
2 Spark
3 HBase
4 云计算处理大数据
版权声明:本文为CSDN博主「bxg1065283526」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/bxg1065283526/java/article/details/79618943
标签:中心 国家 线性回归 算法 数据共享 ase 原来 reg nts
原文地址:https://www.cnblogs.com/wt869054461/p/12628748.html