标签:csv default log 参数 pipe doc imp code dom
pip install scrapy
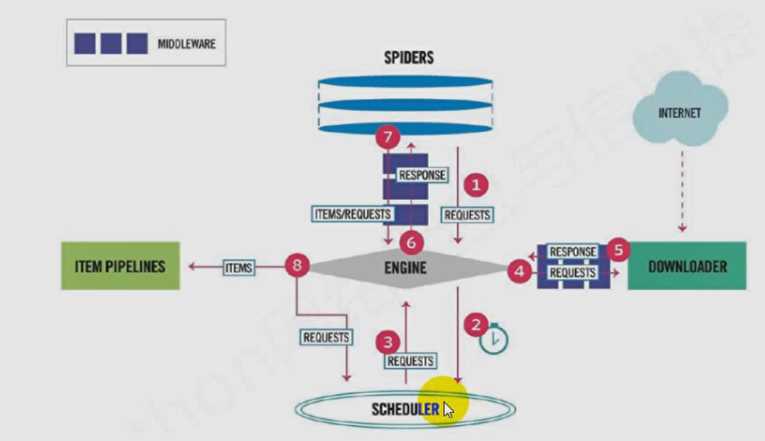
首先通过spider(爬虫)组件构建request对象,并将request对象经由scrapy Engine(scrapy 引擎) 发送给Scheduler(调度器),调度器对request对象进行整理,安排。经过 下载中间件到达下载器,下载器请求网页,返回response对象,由scrapy Engine(scrapy 引擎) 发送给爬虫组件进行数据提取,将提取出的数据发送给 Item Pipeline 进行数据的处理或者分析。
下载中间件:
爬虫中间件:功能类似于下载中间件,但下载中间件更加常用。
scrapy startproject baidu
scrapy genspider baidu_demo #爬虫名 www.baidu.com#限定域
# -*- coding: utf-8 -*-
import scrapy
class BaiduDemoSpider(scrapy.Spider):
name = ‘baidu_demo‘ #爬虫名
allowed_domains = [‘www.baidu.com‘] #允许爬取的域名
start_urls = [‘http://www.baidu.com/‘] #初始url
def parse(self, response): #对返回的响应进行解析
pass
#USER_AGENT = ‘baidu (+http://www.yourdomain.com)‘ #配置USER-AGENT
ROBOTSTXT_OBEY = False #是否遵循robots协议
#CONCURRENT_REQUESTS = 32 #同一时间的发送请求数 默认16
#DOWNLOAD_DELAY = 3 #向同一个网站发送请求的间隔,默认0
#向同一个域名或者同一个ip同时发送的请求数,二选一。
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
#COOKIES_ENABLED = False #是否保存cookies,默认保存
#DEFAULT_REQUEST_HEADERS = {
# ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘,
# ‘Accept-Language‘: ‘en‘,
#} #默认请求头,按照需要更改。
#SPIDER_MIDDLEWARES = {
# ‘baidu.middlewares.BaiduSpiderMiddleware‘: 543,
#} #爬虫中间件是否可用,数字越小优先级越高。
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# ‘baidu.middlewares.BaiduDownloaderMiddleware‘: 543,
#} #下载中间件是否可用,数字越小优先级越高。
#ITEM_PIPELINES = {
# ‘baidu.pipelines.BaiduPipeline‘: 300,
#} #配置 ITEM_PIPELINES(处理解析后的数据),是否可用,数字越小优先级越高。
# -*- coding: utf-8 -*-
import scrapy
class BaiduDemoSpider(scrapy.Spider):
name = ‘baidu_demo‘
allowed_domains = [‘www.baidu.com‘]
start_urls = [‘http://www.baidu.com/‘]
def parse(self, response):
with open(‘../baidu.html‘, ‘w‘, encoding=‘utf-8‘) as file:
file.write(response.text)
scrapy runspider baidu_demo(#爬虫名) [可选参数]
可选参数
-a 设置该爬虫的参数 格式:name=value
-o 输出文件 常用文件类型:csv、json、xml、pickle
-logfile=file(指定日志文件)
--nolog 不输出日志
-L Level(日志等级,默认DEBUG)
标签:csv default log 参数 pipe doc imp code dom
原文地址:https://www.cnblogs.com/hjnzs/p/12629564.html