标签:重复元素 变量 查看 错误 改变 目的 不能 元素查找 使用
Leetcode T350,求两个集合的交集,我的方法错误,但是错误在哪里。
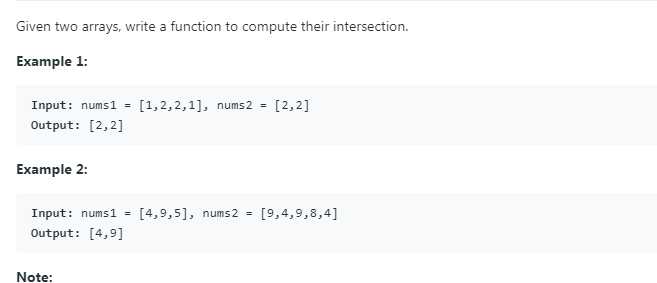
1.学会了array如何转为list,其实还是一个个添加元素式转变最简单
ques:为什么要转变呢?其实自己就是认为在list里面可以去contains 一句话作为代码,所以自己去转变了
2.对于数组,直接是length属性,对于字符串,是length函数,对于抽象的而言,是size函数
4.对于list而言,对于每个index的元素,是用get方法来获得。
5.对于l1.retainAll(l2)而言,意思是说:对于l1里面的每个元素,我都去检索查看,查看它是不是在L2里面,但是注意,这个函数不能求到交集。最后的话,在l1剩下的,是存在于l2里面的元素。
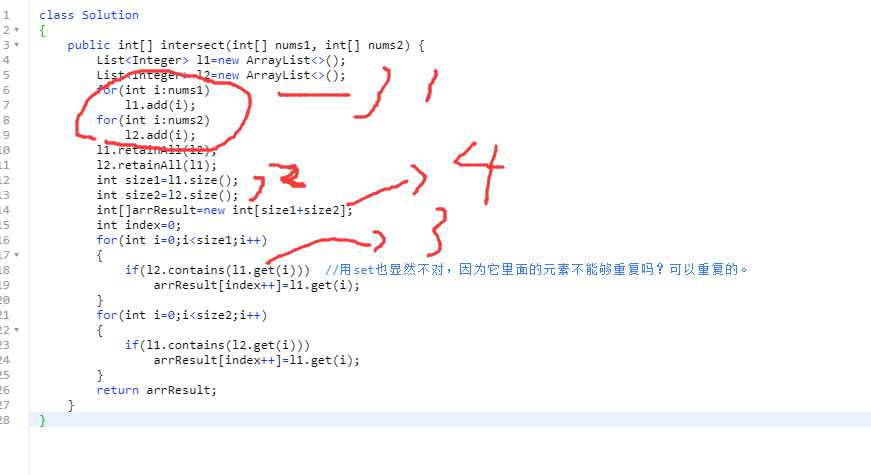
这里讲的是:remove函数是怎么做的,remove函数的意思是:remove掉相应的index上面的元素。
key2:对于remove了之后,在list里面,它是去相应的索引值减一了的。
因此的话,为什么要i--,意思是说,并不要,少减少一个元素。(和之前链表的删除,删除了就不要移动,是同一个道理在。)
也就是对于list的一些操作都已经知道了。 包括增加,删除相应的index的元素,得到相应的index的元素。
而数组转为list,是一个个添加元素。list转为数组,就是直接用toArray方法。
String[] str2=list.toArray(new String[list.size()]
key:必须是包装类型的数组,例如会返回Integer[]类型的,但是key!!!!:Integer[]类型的转为int[]类型的,又要去一个个添加元素了。
重新思考这道题里面应该用什么数据结构:
set?那么数组1里面可能是有重复元素的,不太行。
Tree?也不是上下层的结构,用tree合理吗?
array?先试一下array的方法。
自己写了一遍
class Solution
{
public int[] intersect(int[] nums1, int[] nums2)
{
// int []nums3=new int[nums1.length+nums2.length];//key:要思考的是:数组这件事情,一开始就要定很大的size,定够足够的size给它。
int index=0; //对于多出来的空间,它是仍然返回的.
int []nums5=new int[nums1.length+nums2.length];//变量声明的作用域体现了。如果在{}里面,出了它就不能用
int[]nums3;
int[] nums4;
if(nums1.length<nums2.length)
{
nums3=Arrays.copyOf(nums1,nums1.length);
nums4=Arrays.copyOf(nums2,nums2.length);
}
else
{
nums3=Arrays.copyOf(nums2,nums2.length);
nums4=Arrays.copyOf(nums1,nums1.length);
}
for(int i=0;i<nums3.length;i++) //时间复杂度的话,应该是两个长度去相乘吧。
{
if(contains(nums3[i],nums4)) //i*j的感觉
{
nums5[index++]=nums3[i];
}
}
return Arrays.copyOfRange(nums3,0,index);
}
public boolean contains(int i,int []num) //这里的话,是指向同一片空间的吧。
{//指针的指向是要看的。。
boolean containsIt=false;
int j;
for(j=0;j<num.length;j++)
{
if(num[j]==i) //如果改变num,那么是只改变了指针呀。
{
containsIt=true;
break;
}
}
if(containsIt)
{
if(j==(num.length-1)) //改变这个空间的值应该怎么弄呢?
num[-1]=null; //把最后一片空间给切掉是用这个方法吗?
for(int k=j;k<num.length-1;k++) //小于 num.length。就是到达它了。
{
num[k]=num[k+1];
}
}
return containsIt;
}
}
这是不行的。
还是先学点东西吧:
nums3=Arrays.copyOf(nums1,nums1.length);
Arrays.copyOfRange(nums3,0,index);
这两个函数的作用:
(1)返回数组的副本
(2)返回数组的副本的某些截取的片段。
(3)数组需要先定它的空间大小才能使用。
key:现在会了如何返回数组的副本,如何对数组里面进行截取,但是编译仍然不行。
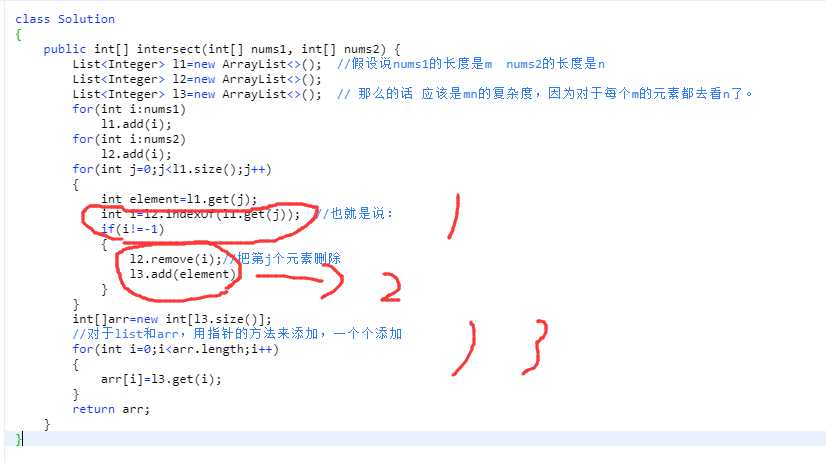
那么它这里用到了map来解决问题,目的:
统计数量,统计在集合1里面出现的元素及其数量,建立map关系
它这里的思想:用list来添加结果,添加完之后,再转换为array。原因:对于array而言,添加、删除元素是复杂的操作,对于list而言较为简单
引入map的目的是:两个东西的交集,如果说list1的和list2的一一对应了之后,那么list1和list2其实都应该删除,然后再去重新看list1和list2
思想:不用array来添加、删除元素,使用list来删除,使用map来添加、删除。
那么为什么之前用list来删除不对呢?
改了一下,用list来删除,是对的了现在
学会的:
1.list里面查看某个元素是否存在,是用contains方法来查看
2.而查看这个是否包含某个元素,是使用:indexOf 查看某个元素的索引,如果说是-1的话,证明这个元素不存在于其中。
3.其实要点就在于:用list和其他容器,来做添加、删除的操作。对于数组,就算是结果需要数组,都先做成了list,之后再转成数组
第二个要点就是说:交集的关系,其实是说,两个集合里面一一对应了之后,要删除它们对应的元素,一一对应后删除的操作。
为什么用map呢?它这里:
它是 遍历完其中一个集合之后,统计其数量属性放到map里面,再对于第二个集合统计属性(使用map查看其中的数量属性对应关系),来获得操作
目的:其实如果linkedlist 也是m*n的时间复杂度,而对于treemap 就是n*logm的时间复杂度。
统计了属性之后,时间复杂度是m,对于数组2的n个元素而言,都需要去在map里面看,是否有对应的key在其中
key:学会了先统计再说的思想(没减少复杂度,但是清晰一点).并且学会如果说是查找的话,对于查找操作可以建立BST来减小查找的消耗。即:查找能用的一个很好的结构,BST
也就是对于统计的属性放到bst里面,可以很方便查找。
treemap:
一个元素查找的时间复杂度:
logM
n个元素
n*logM
map:
一个元素查找的时间复杂度:
M
n个元素
n*M

瞬间从16减小到5
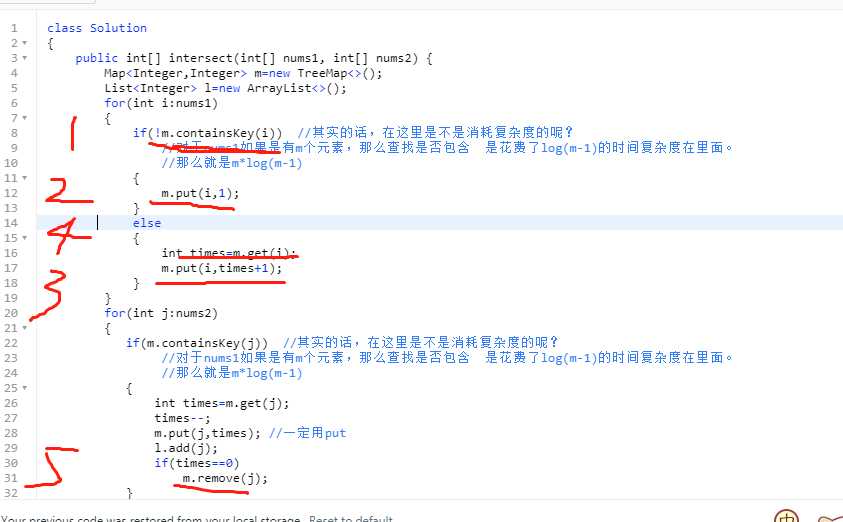
这里说的是map是怎么使用的
m.containsKey(i) 意味着: m是否包含key i
m.put(key,value) 把key和value的对应关系进行建立 或者说把key和value的关系进行改变
m.remove()
m.get(key)
这里的四种方法都是m的使用,以及的话Treemap可以帮助减小查找的时间复杂度,这也是要知道的。
标签:重复元素 变量 查看 错误 改变 目的 不能 元素查找 使用
原文地址:https://www.cnblogs.com/startFrom0/p/12630290.html