标签:语言 它的 inter sdn 依次 使用 under 流程 ocs
我们知道进程之间内存是隔离的不共享。所以一般说到内存就是指的一个进程用到的内存。
而一个进程的内存一般可以分为 5个区:栈区, 堆区, 静态区(全局区), 文字常量区,代码区。而我们主要理解栈区和堆区,其他3个区里面的内容都是静态的。
函数里面涉及到几乎大部分内容都在栈区,比如函数的实参,局部变量,操作符。
优点: cpu处理简单速度快,函数返回,栈区里面的空间就释放,而且对应线程是唯一的(并发安全)。
缺点: 数据结构导致操作不灵活,生命周期短;一般在编译期间就决定了栈区的大小,通常很小。
比较灵活的内存区,进程里面的所有线程共享。程序员操作方便,比如C语言里面malloc申请内存,free释放内存。
优点: 用户态程序操作方便;空间大可以申请比较大的类型数据;里面的变量生命周期长。
缺点: 进程里面所有线程共享这个区域,不是线程(并发)安全的;随着线程不断地申请和释放,导致出现很多内存碎片数据区域不连续,最终导致数据的读写变慢,出现性能问题;没有gc的情况下,需要自己手动管理,如果管理不当很容易造成OOM。
由于堆区的灵活性还有不安全,使得我们不得对其进行管理,比如GC;如果想用的更高效,就得最好还可以管理堆区的分配。所以我们所说的内存管理,主要就是管理堆区的内存分配和释放。
在放一张go内存管理的宏观图加深理解:
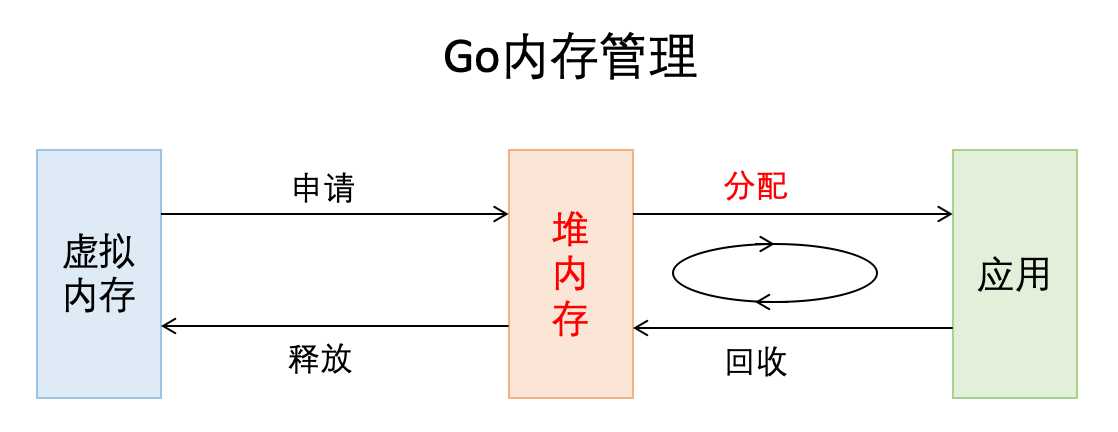
全称Thread Cache Malloc,是google开源的内存管理库。其实有很多内存管理库,但他们追求的本质是在多线程编程下,追求更高内存管理效率。
Go的内存管理是借鉴了TCMalloc,随着Go的迭代,Go的内存管理与TCMalloc不一致地方在不断扩大,但其主要思想、原理和概念都是和TCMalloc一致的。
TCMalloc的细节这里不作讲述。详情介绍可以参考下面两篇文章:
TCMalloc(英文): http://goog-perftools.sourceforge.net/doc/tcmalloc.html
TCMalloc介绍(中文): https://blog.csdn.net/aaronjzhang/article/details/8696212
Go内存管理源自TCMalloc,但它比TCMalloc还多了2件东西:逃逸分析和垃圾回收。逃逸分析和GC会在后面的文章中分享。
再看一张Go内存管理各个模块配合工作的图片:
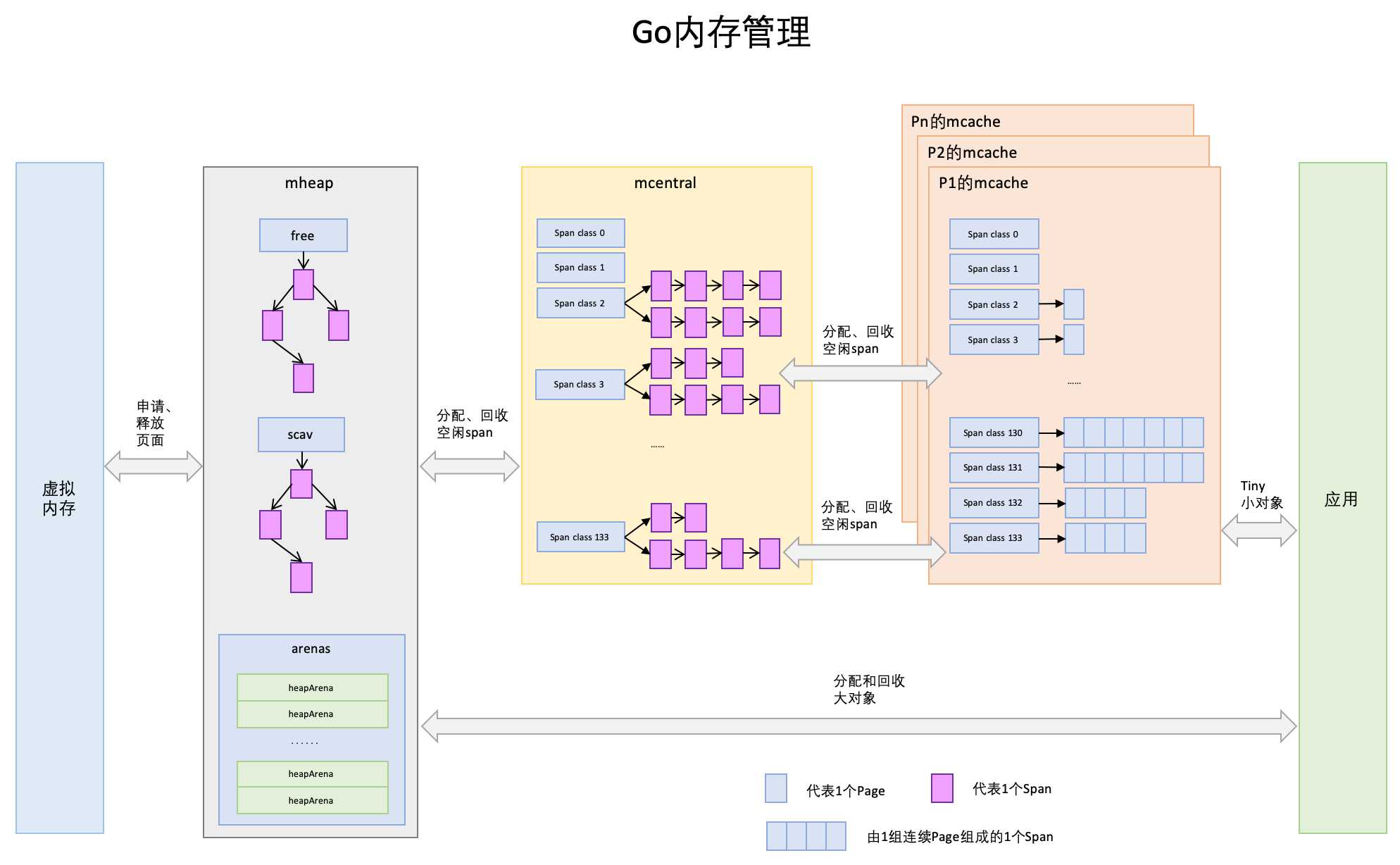
咱们先简单了解一下go内存管理的工作流程。
我们的go进程需要申请一个小对象(<=32KB)的时候直接从mcache里面申请,如果mcache里面没有多余的空间分配,就向mcentral申请一个单位的空间(xKB,具体大小先不管,后面会说)。如果mcentral没有多余的呢,就向mheap申请;如果mheap也不够了呢,mheap就直接从操作系统中分配一组新的内存空间(至少1MB)。
如果申请的大对象(>32KB),直接从mheap分配。
可以发现流程很简单,就是当自己需要内存就向上一级申请内存空间,如果没有多余,就自己上级模块再向他的上一级的内存模块申请空间,依次类推直到内核。
把内存分为多级管理,降低锁的粒度(只是去mcentral和mheap会申请锁), 以及多种对象大小类型,减少分配产生的内存碎片。
接下来就详细说一些模块和概念。
操作系统内存管理中,内存的最粒度是4KB,也就是说分配内存最小4kb起。而golang里面一个page是8KB。
Span是内存管理的基本单位,代码中为mspan,一组连续的Page组成1个Span。mspan其实是一个双向链表的结构,其中包含页面的起始地址,它具有的页面的span类以及它包含的页面数(npage)。后面我们会细说mspan的对象结构,以及什么是span类。
type mspan struct {
next *mspan // next span in list, or nil if none
prev *mspan // previous span in list, or nil if none
list *mSpanList // For debugging. TODO: Remove.
startAddr uintptr // address of first byte of span aka s.base()
npages uintptr // number of pages in span
.....
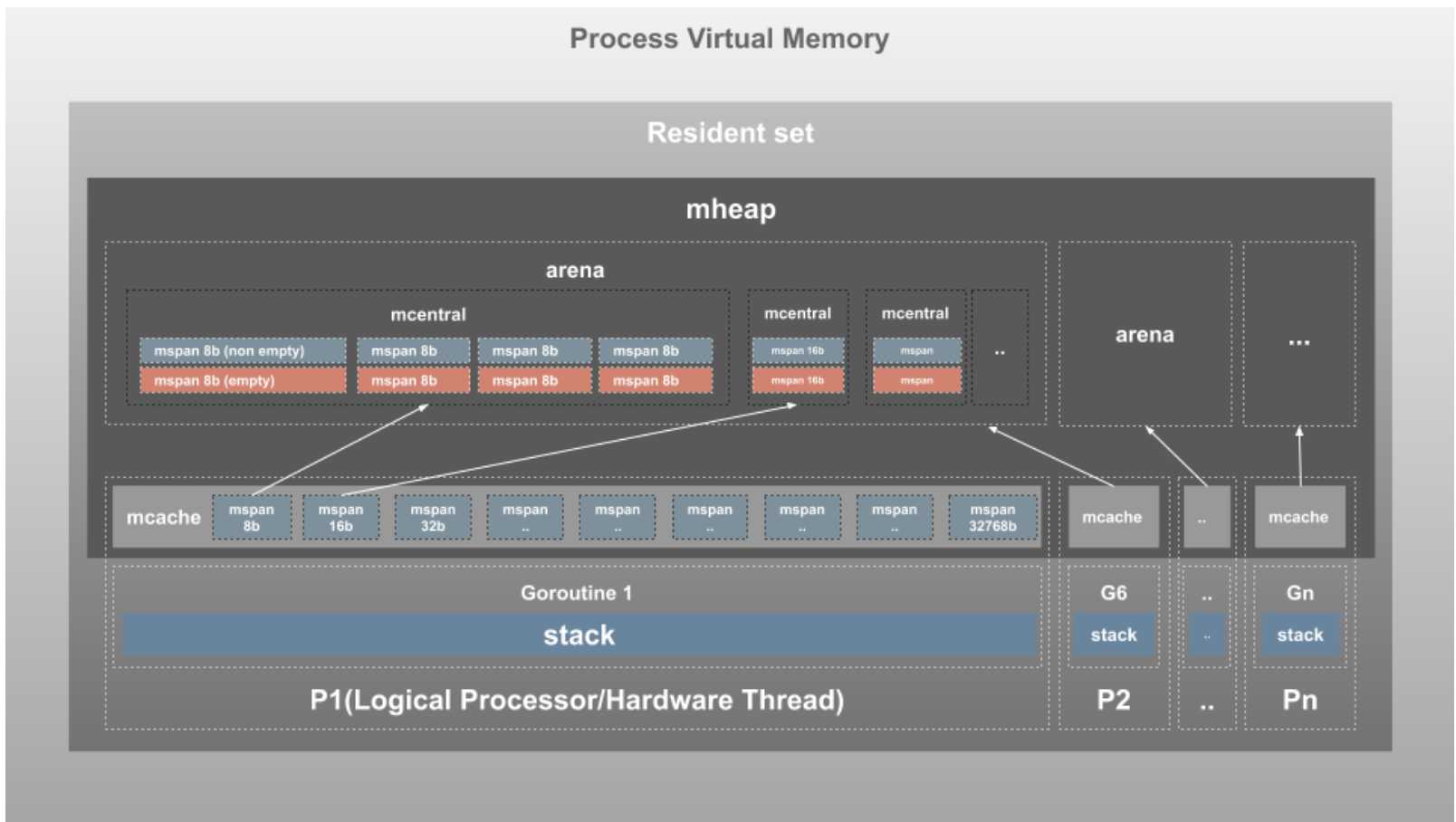
mcache保存的是各种大小的Span,并按Span class分类,小对象(<=32KB)直接从mcache分配内存,它起到了缓存的作用,并且可以无锁访问。
mcache是每个逻辑处理器(P)的本地内存线程缓存。Go中是每个P拥有1个mcache。
mcache是每个级别的Span有2个链表,这和mcache申请内存有关,稍后我们再解释。
type mcache struct {
// The following members are accessed on every malloc,
// so they are grouped here for better caching.
next_sample uintptr // trigger heap sample after allocating this many bytes
local_scan uintptr // bytes of scannable heap allocated
// Allocator cache for tiny objects w/o pointers.
// See "Tiny allocator" comment in malloc.go.
// tiny points to the beginning of the current tiny block, or
// nil if there is no current tiny block.
//
// tiny is a heap pointer. Since mcache is in non-GC‘d memory,
// we handle it by clearing it in releaseAll during mark
// termination.
tiny uintptr
tinyoffset uintptr
local_tinyallocs uintptr // number of tiny allocs not counted in other stats
// The rest is not accessed on every malloc.
alloc [numSpanClasses]*mspan // spans to allocate from, indexed by spanClass
.....
它按Span class对Span分类,串联成链表,当mcache的某个级别Span的内存被分配光时,它会向mcentral申请1个当前级别的Span。所有线程共享的缓存,需要加锁访问。
type mcentral struct {
lock mutex
spanclass spanClass
nonempty mSpanList // list of spans with a free object, ie a nonempty free list
empty mSpanList // list of spans with no free objects (or cached in an mcache)
// nmalloc is the cumulative count of objects allocated from
// this mcentral, assuming all spans in mcaches are
// fully-allocated. Written atomically, read under STW.
nmalloc uint64
}
每个mcentral包含两个mspanList
它把从OS申请出的内存页组织成Span,并保存起来。当mcentral的Span不够用时会向mheap申请,mheap的Span不够用时会向OS申请,向OS的内存申请是按页来的,然后把申请来的内存页生成Span组织起来,同样也是需要加锁访问的。大对象(>32KB)直接从mheap上分配。
type mheap struct {
// lock must only be acquired on the system stack, otherwise a g
// could self-deadlock if its stack grows with the lock held.
lock mutex
free mTreap // free spans
sweepgen uint32 // sweep generation, see comment in mspan
sweepdone uint32 // all spans are swept
sweepers uint32 // number of active sweepone calls
// allspans is a slice of all mspans ever created. Each mspan
// appears exactly once.
//
// The memory for allspans is manually managed and can be
// reallocated and move as the heap grows.
//
// In general, allspans is protected by mheap_.lock, which
// prevents concurrent access as well as freeing the backing
// store. Accesses during STW might not hold the lock, but
// must ensure that allocation cannot happen around the
// access (since that may free the backing store).
allspans []*mspan // all spans out there
...
central [numSpanClasses]struct {
mcentral mcentral
pad [cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize]byte
}
...
我们用一张图来深化一下各个结构体之间的关系
通过下图看看数据大小类别之间的转换
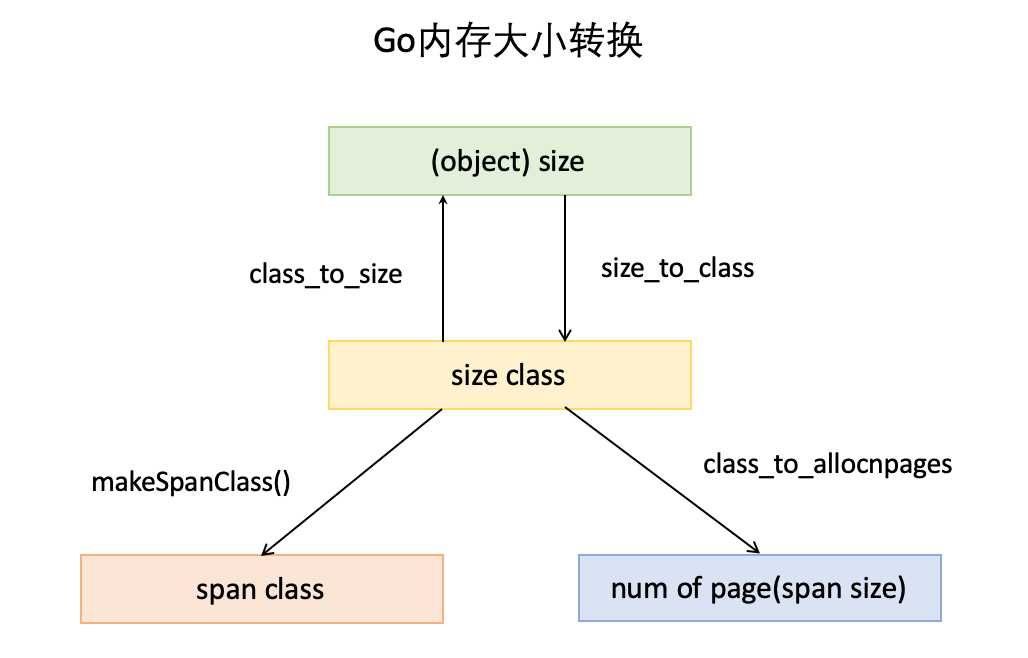
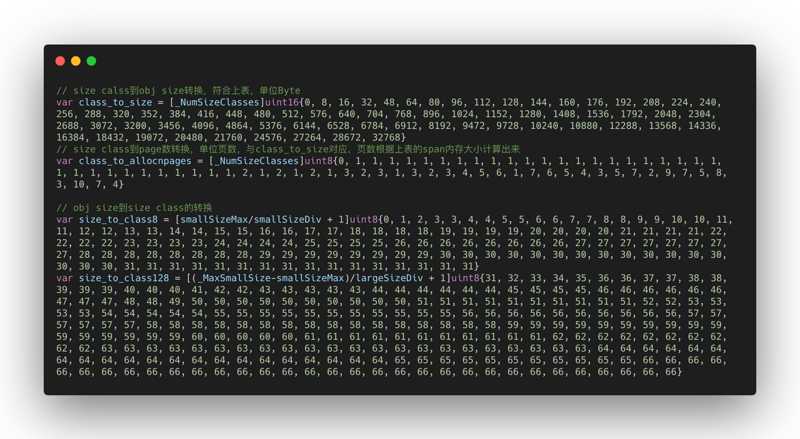
1. object size:指申请一个对象占用的内存大小。
2. size class: 简称class,是指size的级别,一共有67个级别。相当于把size归类到一定大小的区间段,比如size[1,8]属于size class 1,size(8,16]属于size class 2。(简单点理解就是不同的class, mspan里面npage成员变量的值就不一样)
3. span class: 指span的级别,但span class的大小与span的大小并没有正比关系。span class主要用来和size class做对应,1个size class对应2个span class,2个span class的span大小相同,只是功能不同,1个用来存放包含指针的对象,一个用来存放不包含指针的对象,不包含指针对象的Span就无需GC扫描了。
4. num of page:就是mspan结构体里面的npages,代表Page的数量,其实就是Span包含的页数,用来分配内存。
再结合一下数据大小转换表(源代码里面有),对大小转换加深理解。
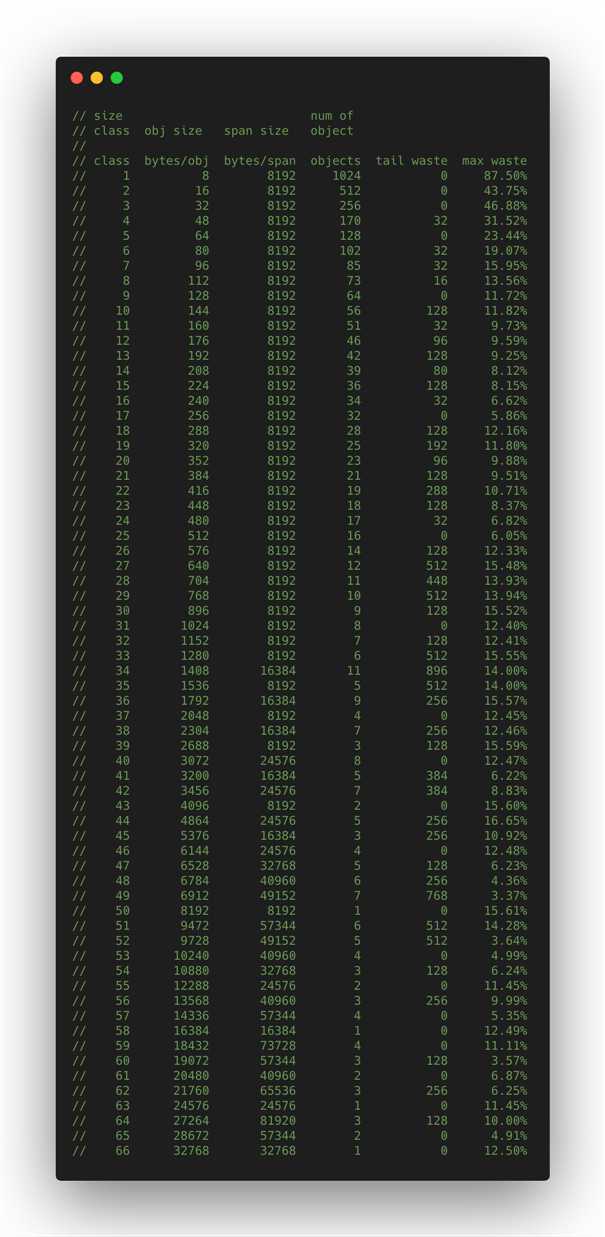
该图里面的第一二行对应上图的大小类型。class_to_size,size_to_class和class_to_allocnpages3个数组,对应内存大小转换那幅图上的3个箭头。
从上图第四行看起,看到数据一共有66行,也就是有66个class。上文不是说有67个吗?因为还有一共是0,就没有列举在里面。
举例:第一行
// class bytes/obj bytes/span objects tail waste max waste // 1 8 8192 1024 0 87.50%
就是类别1的对象大小是8bytes,所以class_to_size[1]=8;span大小是8KB,为1页,所以class_to_allocnpages[1]=1。
最后一列max waste代表最大浪费的内存百分比,计算方法在源码printComment函数中:
func printComment(w io.Writer, classes []class) {
fmt.Fprintf(w, "// %-5s %-9s %-10s %-7s %-10s %-9s\n", "class", "bytes/obj", "bytes/span", "objects", "tail waste", "max waste")
prevSize := 0
for i, c := range classes {
if i == 0 {
continue
}
spanSize := c.npages * pageSize
objects := spanSize / c.size
tailWaste := spanSize - c.size*(spanSize/c.size)
maxWaste := float64((c.size-prevSize-1)*objects+tailWaste) / float64(spanSize)
prevSize = c.size
fmt.Fprintf(w, "// %5d %9d %10d %7d %10d %8.2f%%\n", i, c.size, spanSize, objects, tailWaste, 100*maxWaste)
}
fmt.Fprintf(w, "\n")
}
Span最浪费内存的场景是:Span内的每个对象,占用的内存都是前一个class中对象的大小加1。比如class2的对象大小是9B,且只有一个,以此类推。
这样无法占用低一级的Span,又浪费了大量空间。所以一个Span内对象空间所浪费的内存为:所有对象空间浪费的内存之和+tail waste。
maxWaste := float64((c.size-prevSize-1)*objects+tailWaste) / float64(spanSize)
上文提到1个size class对应2个span class:
numSpanClasses = _NumSizeClasses << 1
numSpanClasses为span class的数量为134个。 所以在go内存管理这张图里面,span class的下标是从0到133。每1个span class都指向1个span,也就是mcache最多有134个span。
numSpanClasses的使用在mheap和mcache结构体里面。
为一个对象寻找span class寻找span的过程:
以分配一个不包含指针的,大小为24Byte的对象为例。
// class bytes/obj bytes/span objects tail waste max waste // 1 8 8192 1024 0 87.50% // 2 16 8192 512 0 43.75% // 3 32 8192 256 0 46.88%
size class 3,它的对象大小范围是(16,32]Byte,24Byte刚好在此区间,所以此对象的size class为3。
size class到span class的计算如下:
func makeSpanClass(sizeclass uint8, noscan bool) spanClass {
return spanClass(sizeclass<<1) | spanClass(bool2int(noscan))
}
所以size class 3对应的span class为:
span class = 3 << 1 | 1 = 7
所以该对象需要的是span class 7指向的span。
另外,包含指针noscan就是false, span class为
span class = 3 << 1 | 0 = 6
文章重要讲了go内存管理的两点:
1. 内存管理的关键数据结构之间的关系。
2. 对象与go最小内存管理单元之间的大小转换关系。
后面的文章会继续深入讲解内存分配的流程
https://mp.weixin.qq.com/s/3gGbJaeuvx4klqcv34hmmw https://tonybai.com/2020/03/10/visualizing-memory-management-in-golang https://blog.learngoprogramming.com/a-visual-guide-to-golang-memory-allocator-from-ground-up-e132258453ed
标签:语言 它的 inter sdn 依次 使用 under 流程 ocs
原文地址:https://www.cnblogs.com/xiaoxlm/p/12587557.html